课前ps:终于到我们的正文了,想想还有点小激动呢!下来我们就延续我们最佳实践的步骤。
代码预览
#coding:utf-8
from bs4 import BeautifulSoup
import requests
def detailOper(url):
web_data = requests.get(url)
soup = BeautifulSoup(web_data.text, 'lxml')
titles = soup.select('div.list > ul > li > div > p.infoBox > a')
prices = soup.select('div.list > ul > li > div > p.priType-s > span > i')
for title, price in zip(titles, prices):
data = {
'title': title.get_text(),
'detailHerf': title.get('href'),
'price':price.get_text().replace(u'万', '').replace(' ', '')
}
print(data)
def start():
urls = ['http://www.guazi.com/tj/buy/o{}/'.format(str(i)) for i in range(1, 30, 1)]
for url in urls:
detailOper(url)
if __name__ == '__main__':
start()
代码剖析
怎么样,上面的代码不多吧,我们来慢慢分析:
ps:最近在考虑买个二手车练练手,所以最后选了瓜子网作为我们的练手对象,谁让我经常访问你呢~
这两句引入我们对应的库,beautifulsoup和requests
from bs4 import BeautifulSoup
import requests
这一句调用了我们这个py脚本的入口start函数
if __name__ == '__main__':
start()
函数start的作用是构建我们要访问的urls,然后逐个调用detailOper()函数
def start():
urls = ['http://www.guazi.com/tj/buy/o{}/'.format(str(i)) for i in range(1, 30, 1)]
for url in urls:
detailOper(url)
其实我们通过观察瓜子网的url就可以发现其规律(如下图),当我们选择第二分特的时候,url变成了http://www.guazi.com/tj/buy/o2/,当我们选择第三分页的时候url变成了http://www.guazi.com/tj/buy/o3/,我们想要抓取瓜子在天津地区所有的二手车,那么我们只需要访问29次不同的分页即可,这边是我们start函数的作用,构建了29次不同的url然后分别请求抓取数据

接下来,到了我们今天的重点,如何抓取网页数据并筛选出来我们想要的,我们来一起看看detailOper()函数:
web_data = requests.get(url)
通过requests.get()函数获取了一个response对象
soup = BeautifulSoup(web_data.text, 'lxml')
首先web_data.text为抓取到的网页主体,也就是所谓的网页源代码,我们在浏览器上单击右键就可以看到获取网页源代码选项。而上面这行代码构建了一个beautifulsoup解析器,后面的参数传入解析器的type,有很多种,比如lxml,xml,html5lib,我们用的是lxml
titles = soup.select('div.list > ul > li > div > p.infoBox > a')
上面这段代码我们用soup对象的select函数筛选我们想要的网页信息,其中传入的参数是Css Path,Css Path的作用就是帮我们定位到我们需要的信息,方便我们进行筛选,那么如何获取Css Path呢?如下图步骤

首先,在网页中选中我们想要的元素,比如每个汽车的标题,然后选择其中一个的位置右键浏览器,选择其中的审查元素,当然,不同的浏览器可能名称不太一样,有的叫检查。然后我们可以看到如下画面:
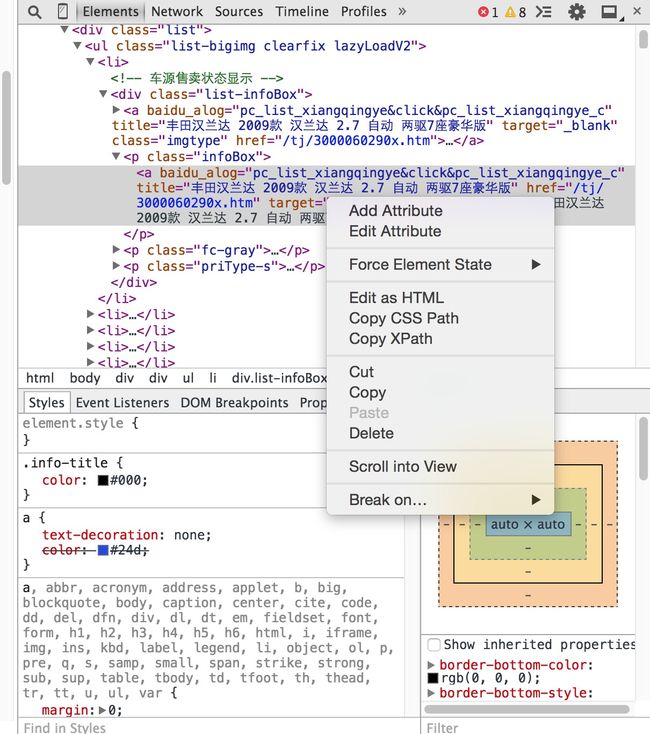
浏览器帮你自动定位到了你要筛选的信息的位置,然后在这个位置上点击右键就可以看到有选项叫Copy Css Path,这时候我们就得到了我们想要的信息的Css Path,是不是so easy呢?有同学可能还看到了有XPath,这也是可以用来定位的,使用方式和Css path类似,但是beautifulsoup支持的是CSS Selector,如果以后大家使用scrapy框架的话可能会用到XPath
接下来我们得到了body > div.w > div.list > ul > li:nth-child(40) > div > p.infoBox > a首先去掉前端一些无用的body > div.w >路径,因为我们整个网站的主体都是在body的class属性为"w"的div下,所以去掉它们能更好的选择我们想要的东西,接下来得到了div.list > ul > li:nth-child(40) > div > p.infoBox > a,这一条css path最后取出的结果是网页的第40个li元素下对应的title,鞋同应该已经发现了li:nth-child(40),后面的nth-child()定位的就是第几个li元素,我们可以观察一下网页的构成,如下图
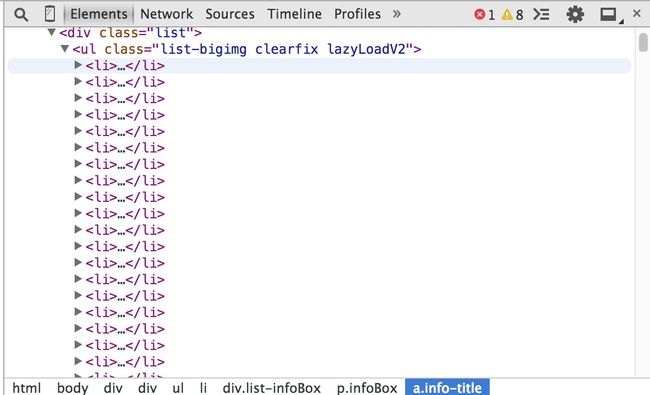
我们可以看到每个li标签其实就对应了上图中一个车,我们要取出所有的符合条件的li标签下的内容,所以我们需要去掉限制条件
div.list > ul > li> div > p.infoBox > a于是乎这便是我们的想要的Css Path,这时候我们取出的是一个titles的列表,里面存的是这个页面所有汽车的title,同理我们对着下面的价格取Css Path得到了
div.list > ul > li > div > p.priType-s > span > i,这时候,我们已经获取到了我们想要的东西。
我们来分析一下最后一段代码
for title, price in zip(titles, prices):
data = {
'title': title.get_text(),
'detailHerf': title.get('href'),
'price':price.get_text().replace(u'万', '').replace(' ', '')
}
print(data)
把我们获取到的title和price挨个取出来放入一个名为data的数据字典中,我们可以看到'title': title.get_text(),因为我们取出的title其实是beautifulsoup解析出来的一个对象,我们要获取具体属性需要使用一些它提供的函数,这个get_text()函数就是获取标签中间文字属性,知道html结构的同学可能好理解一些,例如我们这次获取到的是test标签,那么get_text()取出的就是中间部分的test,下面是真实环境,所以我们取出了:海马M3 2013款 1.5 手动 标准型
海马M3 2013款 1.5 手动 标准型
'detailHerf': title.get('href')get(属性名)方法取出的是标签中的各个属性,我们观察上面的a标签发现它有个href属性对应的是车况的具体网页,然后我们就可以通过.get(属性名)的方式获取它的值。
至此,我们真实环境中的网页解析demo1就结束了,是不是很简单呢?
ps:可能有些大神或者有基础的同学觉得我很啰嗦,但是我想说的是,我想让没有基础的同学也能看懂代码,也能明白每句的含义,因为这很重要,我们有时候往往只是知道这么做可以达到目的,但是不知道这么做的原因。
写在最后
最佳实践的前两步我已经帮你们完成了,也就是给你们一个demo,并且帮你们深入剖析了demo,那么下一步,在demo之上的扩展就要靠你们了。我留一个小作业,有兴趣的同学可以做一下,我们的demo只扒取了天津地区的二手车,那么,你们就来试试扒取瓜子网上全国所有地区的二手车信息吧~(瓜子表示自己又躺枪了)给大家一个提示
两个位置可以分别获取全国其他地区的瓜子二手车链接和每个地区拥有的车的数量哦,我们可以实现一个全自动的抓取整个瓜子网所有二手车信息的爬虫~
下一章我们讲解如何扒取动态加载的信息~
有兴趣的同学可以加群498945822一起交流学习哦~~
发现问题的同学欢迎指正,直接说就行,不用留面子,博主脸皮厚!