目录
- 简单了解数据分析
- Python数据分析三剑客(Numpy,Pandas,Matplotlib)
- 简单使用np.array()
- 使用np的routines函数创建数组
- ndarray N维数组对象
- ndarray的基本操作
- 简单使用matplotlib.pyplot获取一个numpy数组,对其进行操作
- 学习网站
简单了解数据分析
数据分析(是把隐藏在一些看似杂乱无章的数据背后的信息提炼出来,总结出所研究对象的内在规律)
数据分析是指用适当的统计分析方法对收集来的大量数据进行分析,提取有用信息和形成结论而对数据加以详细研究和概括总结的过程。
这一过程也是质量管理体系的支持过程。在实用中,数据分析可帮助人们作出判断,以便采取适当行动。
数据分析的数学基础在20世纪早期就已确立,但直到计算机的出现才使得实际操作成为可能,并使得数据分析得以推广。
数据分析是数学与计算机科学相结合的产物。Python数据分析三剑客(Numpy,Pandas,Matplotlib)
NumPy
NumPy(Numerical Python) 是 Python 语言的一个扩展程序库,支持大量的维度数组与矩阵运算,此外也针对数组运算提供大量的数学函数库。
NumPy 的前身 Numeric 最早是由 Jim Hugunin 与其它协作者共同开发,2005 年,Travis Oliphant 在 Numeric 中结合了另一个同性质的程序库 Numarray 的特色,
并加入了其它扩展而开发了 NumPy。NumPy 为开放源代码并且由许多协作者共同维护开发。
NumPy 是一个运行速度非常快的数学库,主要用于数组计算,包含:
一个强大的N维数组对象 ndarray
广播功能函数
整合 C/C++/Fortran 代码的工具
线性代数、傅里叶变换、随机数生成等功能Numpy常用函数用法大全目录
#Numpy常用函数用法大全目录
A
array 创建一个np数组
arange 返回指定范围内的数组
argmax 返回沿轴axis最大值的索引
B
bincount 返回数组中的值中索引出现的次数
C
copysign 将b中各元素的符号赋值给数组a的对应元素
D
dot 矩阵运算
E
exp e的N次方
F
full 返回给定形状和类型的新数组,填充fill_value
G
gradient 返回N维数组的梯度
H
hsplit 通过指定要返回的相同shape的array的数量,或者通过指定分割应该发生之后的列来沿着其横轴拆分原array
I
isnan 测试NaN的元素,并将结果作为布尔数组返回
L
log e的指数
linspace 在指定的间隔内返回均匀间隔的数字
M
max 数组中最大的键
R
reshape 不改变数据同时改变数据格式
random.choice 随机分布一个数组
random.randn 返回一个或一组样本,具有标准正态分布
S
sum 每个数组各个键的总和
v
vsplit 沿着垂直轴分割,其分割方式与hsplit用法相同
Z
zeros_like 生成0填充形状和传入数组相同的数组
zeros 返回来一个给定形状和类型的用0填充的数组Pandas
pandas 是基于NumPy 的一种工具,该工具是为了解决数据分析任务而创建的。Pandas 纳入了大量库和一些标准的数据模型,
提供了高效地操作大型数据集所需的工具。pandas提供了大量能使我们快速便捷地处理数据的函数和方法。你很快就会发现,
它是使Python成为强大而高效的数据分析环境的重要因素之一。Matplotlib
Matplotlib 是一个 Python 的 2D绘图库,它以各种硬拷贝格式和跨平台的交互式环境生成出版质量级别的图形。
通过 Matplotlib,开发者可以仅需要几行代码,便可以生成绘图,直方图,功率谱,条形图,错误图,散点图等。简单使用np.array()
安装NumPy pip3 install numpy
一维数组创建
import numpy as np #as np别名方便调用
np.array([1,2,3,4,5])
#执行结果 所有代码使用的是Jupyter Notebook执行,所以没有print
array([1, 2, 3, 4, 5])二维数组创建
import numpy as np
np.array([[1,2,3],[4,5,6]])
#执行结果
array([[1, 2, 3],
[4, 5, 6]])
np.array([[1,1.2,3],[4,5,'six']])
#执行结果
array([['1', '1.2', '3'],
['4', '5', 'six']], dtype='注意
- numpy默认ndarray的所有元素的类型是相同的
- 如果传进来的列表中包含不同的类型,则统一为同一类型,优先级:str>float>int使用np的routines函数创建数组
np.linspace 等差数列
import numpy as np
np.linspace(1,100,num=10)
#执行结果
array([ 1., 12., 23., 34., 45., 56., 67., 78., 89., 100.])np.arange 使用步长
import numpy as np
np.arange(0,100,2)
#执行结果
array([ 0, 2, 4, 6, 8, 10, 12, 14, 16, 18, 20, 22, 24, 26, 28, 30, 32,
34, 36, 38, 40, 42, 44, 46, 48, 50, 52, 54, 56, 58, 60, 62, 64, 66,
68, 70, 72, 74, 76, 78, 80, 82, 84, 86, 88, 90, 92, 94, 96, 98])np.random.randint 随机数组
# 随机原理
# - 随机因子:表示的是一个无时无刻都在变化的数值(比如时间)
import numpy as np
np.random.seed(10)#指定随机因子
np.random.randint(0,100,size=(4,5))
#执行结果 不会变
array([[ 9, 15, 64, 28, 89],
[93, 29, 8, 73, 0],
[40, 36, 16, 11, 54],
[88, 62, 33, 72, 78]])
#np.random.seed(10) 不指定随机因子
np.random.randint(0,100,size=(4,5))
#执行结果 第一次
array([[49, 51, 54, 77, 69],
[13, 25, 13, 92, 86],
[30, 30, 89, 12, 65],
[31, 57, 36, 27, 18]])
#执行结果 第二次
array([[93, 77, 22, 23, 94],
[11, 28, 74, 88, 9],
[15, 18, 80, 71, 88],
[11, 17, 46, 7, 75]])
#执行结果 第三次
array([[28, 33, 84, 96, 88],
[44, 5, 4, 71, 88],
[88, 50, 54, 34, 15],
[77, 88, 15, 6, 85]])
np.random.random(size=(5,3))
#执行结果
array([[0.82110566, 0.15115202, 0.38411445],
[0.94426071, 0.98762547, 0.45630455],
[0.82612284, 0.25137413, 0.59737165],
[0.90283176, 0.53455795, 0.59020136],
[0.03928177, 0.35718176, 0.07961309]])ndarray N维数组对象
NumPy最重要的一个特点就是其N维数组对象(即ndarray),该对象是一个快速而灵活的大数据集容器,该对象由两部分组成:
- 实际的数据;
- 描述这些数据的元数据;
大部分的数组操作仅仅是修改元数据部分,而不改变其底层的实际数据。数组的维数称为秩,简单来说就是如果你需要获取数组中一个特定元素所需的坐标数,
如a是一个2×3×4的矩阵,你索引其中的一个元素必须给定三个坐标a[x,y,z],故它的维数就是3。而轴可以理解为一种对数组空间的分割,以数组a为例,
如果我们以0为轴,那么a可以看成是一个由两个元素构成的数组,其中每个元素都是一个3×4的数组。
我们可以直接将数组看作一种新的数据类型,就像list、tuple、dict一样,但数组中所有元素的类型必须是一致的,Python支持的数据类型有整型、
浮点型以及复数型,但这些类型不足以满足科学计算的需求,因此NumPy中添加了许多其他的数据类型,如bool、inti、int64、float32、complex64等。
同时,它也有许多其特有的属性和方法。
常用ndarray属性:
dtype 描述数组元素的类型
shape 以tuple表示的数组形状
ndim 数组的维度
size 数组中元素的个数
itemsize 数组中的元素在内存所占字节数
T 数组的转置
flat 返回一个数组的迭代器,对flat赋值将导致整个数组的元素被覆盖
real/imag 给出复数数组的实部/虚部
nbytes 数组占用的存储空间
常用ndarray方法:
reshape(…) 返回一个给定shape的数组的副本
resize(…) 返回给定shape的数组,原数组shape发生改变
flatten()/ravel() 返回展平数组,原数组不改变
astype(dtype) 返回指定元素类型的数组副本
fill() 将数组元素全部设定为一个标量值
sum/Prod() 计算所有数组元素的和/积
mean()/var()/std() 返回数组元素的均值/方差/标准差
max()/min()/ptp()/median() 返回数组元素的最大值/最小值/取值范围/中位数
argmax()/argmin() 返回最大值/最小值的索引
sort() 对数组进行排序,axis指定排序的轴;kind指定排序算法,默认是快速排序
view()/copy() view创造一个新的数组对象指向同一数据;copy是深复制
tolist() 将数组完全转为列表,注意与直接使用list(array)的区别
compress() 返回满足条件的元素构成的数组ndarray的基本操作
索引
import numpy as np
#准备
arr = np.random.randint(60,120,size=(6,8))
arr
#执行结果 数组
array([[102, 68, 86, 84, 80, 104, 90, 77],
[112, 92, 113, 82, 99, 91, 92, 83],
[ 84, 93, 81, 111, 86, 75, 88, 71],
[114, 101, 77, 111, 67, 73, 91, 64],
[ 90, 101, 73, 73, 92, 84, 107, 96],
[115, 102, 116, 81, 66, 83, 88, 72]])
arr[1] #直结索引取到的是 行
#执行结果
array([112, 92, 113, 82, 99, 91, 92, 83])
arr[1][2]#直结索引再索引 取到的是 某行的某个元素
#执行结果
113
#小结:一维与列表完全一致 多维时同理切片
#还是沿用上边的数据
array([[102, 68, 86, 84, 80, 104, 90, 77],
[112, 92, 113, 82, 99, 91, 92, 83],
[ 84, 93, 81, 111, 86, 75, 88, 71],
[114, 101, 77, 111, 67, 73, 91, 64],
[ 90, 101, 73, 73, 92, 84, 107, 96],
[115, 102, 116, 81, 66, 83, 88, 72]])
#获取二维数组前两行
arr[0:2]# 直接切片取得是行 取先不取后
#执行结果
array([[102, 68, 86, 84, 80, 104, 90, 77],
[112, 92, 113, 82, 99, 91, 92, 83]])
#获取二维数组前两列
arr[:,0:2]# 应用了逗号的机制,逗号左边为第一个维度(行),右边为第二个维度(列) :代表不对行做操作
#执行结果
array([[102, 68],
[112, 92],
[ 84, 93],
[114, 101],
[ 90, 101],
[115, 102]])
#获取二维数组前两行和前三列数据
arr[0:2,0:3] #逗号 左边行 右边列
#执行结果
array([[102, 68, 86],
[112, 92, 113]])
#将数组的行倒序
arr[::-1]
#执行结果
array([[115, 102, 116, 81, 66, 83, 88, 72],
[ 90, 101, 73, 73, 92, 84, 107, 96],
[114, 101, 77, 111, 67, 73, 91, 64],
[ 84, 93, 81, 111, 86, 75, 88, 71],
[112, 92, 113, 82, 99, 91, 92, 83],
[102, 68, 86, 84, 80, 104, 90, 77]])
#全部倒序
arr[::-1,::-1]
#执行结果
array([[ 72, 88, 83, 66, 81, 116, 102, 115],
[ 96, 107, 84, 92, 73, 73, 101, 90],
[ 64, 91, 73, 67, 111, 77, 101, 114],
[ 71, 88, 75, 86, 111, 81, 93, 84],
[ 83, 92, 91, 99, 82, 113, 92, 112],
[ 77, 90, 104, 80, 84, 86, 68, 102]])变形 (arr.reshape() 机器学习会用到)
#使用arr.reshape()函数,注意参数是一个tuple!
#准备数据
import numpy as np
arr = np.random.randint(60,120,size=(6,8))
arr
array([[101, 67, 88, 94, 75, 82, 105, 96],
[100, 86, 112, 69, 79, 100, 65, 114],
[ 72, 86, 95, 84, 112, 94, 103, 115],
[ 83, 110, 78, 60, 67, 86, 113, 92],
[ 74, 118, 79, 86, 63, 97, 81, 106],
[112, 118, 83, 105, 72, 78, 94, 88]])
#将数组改成一维数组
arr.reshape((48,))
#执行结果 一个中括号是一维 注意变形元素总数量不能改变,不然会报错
array([101, 67, 88, 94, 75, 82, 105, 96, 100, 86, 112, 69, 79,
100, 65, 114, 72, 86, 95, 84, 112, 94, 103, 115, 83, 110,
78, 60, 67, 86, 113, 92, 74, 118, 79, 86, 63, 97, 81,
106, 112, 118, 83, 105, 72, 78, 94, 88])
#修改数组,不改变维数
arr.reshape((48,1))
#执行结果
array([[101],
[ 67],
[ 88],
[ 94],
[ 75],
[ 82],
[105],
[ 96],
[100],
[ 86],
[112],
[ 69],
[ 79],
[100],
[ 65],
[114],
[ 72],
[ 86],
[ 95],
[ 84],
[112],
[ 94],
[103],
[115],
[ 83],
[110],
[ 78],
[ 60],
[ 67],
[ 86],
[113],
[ 92],
[ 74],
[118],
[ 79],
[ 86],
[ 63],
[ 97],
[ 81],
[106],
[112],
[118],
[ 83],
[105],
[ 72],
[ 78],
[ 94],
[ 88]])
arr.reshape((-1,48))
#执行结果
array([[101, 67, 88, 94, 75, 82, 105, 96, 100, 86, 112, 69, 79,
100, 65, 114, 72, 86, 95, 84, 112, 94, 103, 115, 83, 110,
78, 60, 67, 86, 113, 92, 74, 118, 79, 86, 63, 97, 81,
106, 112, 118, 83, 105, 72, 78, 94, 88]])
arr.reshape((12,-1))#-1可以自动补齐
#执行结果
array([[101, 67, 88, 94],
[ 75, 82, 105, 96],
[100, 86, 112, 69],
[ 79, 100, 65, 114],
[ 72, 86, 95, 84],
[112, 94, 103, 115],
[ 83, 110, 78, 60],
[ 67, 86, 113, 92],
[ 74, 118, 79, 86],
[ 63, 97, 81, 106],
[112, 118, 83, 105],
[ 72, 78, 94, 88]])
arr.reshape((-1,12))
#执行结果
array([[101, 67, 88, 94, 75, 82, 105, 96, 100, 86, 112, 69],
[ 79, 100, 65, 114, 72, 86, 95, 84, 112, 94, 103, 115],
[ 83, 110, 78, 60, 67, 86, 113, 92, 74, 118, 79, 86],
[ 63, 97, 81, 106, 112, 118, 83, 105, 72, 78, 94, 88]])
#将数组改为三维
arr.reshape((2,4,6))
#执行结果
array([[[101, 67, 88, 94, 75, 82],
[105, 96, 100, 86, 112, 69],
[ 79, 100, 65, 114, 72, 86],
[ 95, 84, 112, 94, 103, 115]],
[[ 83, 110, 78, 60, 67, 86],
[113, 92, 74, 118, 79, 86],
[ 63, 97, 81, 106, 112, 118],
[ 83, 105, 72, 78, 94, 88]]])级联 (np.concatenate(),下面图片修改有实际应用)
#一维,二维,多维数组的级联,实际操作中级联多为二维数组 (对一个或多个数组做拼接)
#准备数据
import numpy as np
arr = np.random.randint(60,120,size=(6,8))
arr
array([[101, 67, 88, 94, 75, 82, 105, 96],
[100, 86, 112, 69, 79, 100, 65, 114],
[ 72, 86, 95, 84, 112, 94, 103, 115],
[ 83, 110, 78, 60, 67, 86, 113, 92],
[ 74, 118, 79, 86, 63, 97, 81, 106],
[112, 118, 83, 105, 72, 78, 94, 88]])
np.concatenate((arr,arr),axis=1) # 轴向 0列 1行
#执行效果
array([[101, 67, 88, 94, 75, 82, 105, 96, 101, 67, 88, 94, 75,
82, 105, 96],
[100, 86, 112, 69, 79, 100, 65, 114, 100, 86, 112, 69, 79,
100, 65, 114],
[ 72, 86, 95, 84, 112, 94, 103, 115, 72, 86, 95, 84, 112,
94, 103, 115],
[ 83, 110, 78, 60, 67, 86, 113, 92, 83, 110, 78, 60, 67,
86, 113, 92],
[ 74, 118, 79, 86, 63, 97, 81, 106, 74, 118, 79, 86, 63,
97, 81, 106],
[112, 118, 83, 105, 72, 78, 94, 88, 112, 118, 83, 105, 72,
78, 94, 88]])
#级联需要注意的点:
级联的参数是列表:一定要加中括号或小括号
维度必须相同
形状相符:在维度保持一致的前提下,如果进行横向(axis=1)级联,必须保证进行级联的数组行数保持一致。如果进行纵向(axis=0)级联,
必须保证进行级联的数组列数保持一致。
可通过axis参数改变级联的方向ndarray的聚合操作
#求和np.sum
arr.sum(axis=None)
#执行结果
4374
#最大最小值:np.max/ np.min
#平均值:np.mean()
Function Name NaN-safe Version Description
np.sum np.nansum Compute sum of elements
np.prod np.nanprod Compute product of elements
np.mean np.nanmean Compute mean of elements
np.std np.nanstd Compute standard deviation
np.var np.nanvar Compute variance
np.min np.nanmin Find minimum value
np.max np.nanmax Find maximum value
np.argmin np.nanargmin Find index of minimum value
np.argmax np.nanargmax Find index of maximum value
np.median np.nanmedian Compute median of elements
np.percentile np.nanpercentile Compute rank-based statistics of elements
np.any N/A Evaluate whether any elements are true
np.all N/A Evaluate whether all elements are true
np.power 幂运算ndarray的排序
np.sort()与ndarray.sort()都可以,但有区别:
- np.sort()不改变输入
- ndarray.sort()本地处理,不占用空间,但改变输入
#准备数据
import numpy as np
arr = np.random.randint(60,120,size=(6,8))
arr
array([[101, 67, 88, 94, 75, 82, 105, 96],
[100, 86, 112, 69, 79, 100, 65, 114],
[ 72, 86, 95, 84, 112, 94, 103, 115],
[ 83, 110, 78, 60, 67, 86, 113, 92],
[ 74, 118, 79, 86, 63, 97, 81, 106],
[112, 118, 83, 105, 72, 78, 94, 88]])
arr.sort(axis=0)#会作业到原始数据中 axis=0对每一列做排序
arr
#执行结果
array([[ 72, 67, 78, 60, 63, 78, 65, 88],
[ 74, 86, 79, 69, 67, 82, 81, 92],
[ 83, 86, 83, 84, 72, 86, 94, 96],
[100, 110, 88, 86, 75, 94, 103, 106],
[101, 118, 95, 94, 79, 97, 105, 114],
[112, 118, 112, 105, 112, 100, 113, 115]])
arr.sort(axis=1)#会作业到原始数据中 axis=0对每一行做排序
arr
#执行结果
array([[ 60, 63, 65, 67, 72, 78, 78, 88],
[ 67, 69, 74, 79, 81, 82, 86, 92],
[ 72, 83, 83, 84, 86, 86, 94, 96],
[ 75, 86, 88, 94, 100, 103, 106, 110],
[ 79, 94, 95, 97, 101, 105, 114, 118],
[100, 105, 112, 112, 112, 113, 115, 118]])
简单使用matplotlib.pyplot获取一个numpy数组,对其进行操作
准备

获取一个numpy数组,简单操作查看,展示图片
# 使用matplotlib.pyplot获取一个numpy数组,数据来源于一张图片
import matplotlib.pyplot as plt
img_arr = plt.imread('./part_1/cat.jpg')
img_arr.shape#数组形状
#执行结果
(456,730,3) #行,列,颜色,总个数是维度
img_arr.size#数组大小
#执行结果
998640 #多少元素
img_arr.dtype#数组类型
#执行结果
dtype('uint8')#数组类型, uint8是8位无符号整型
img_arr#查看数组
#执行结果 三位数组231, 186, 131前两位数是像素点,后一位是颜色
array([[[231, 186, 131],
[232, 187, 132],
[233, 188, 133],
...,
[100, 54, 54],
[ 92, 48, 47],
[ 85, 43, 44]],
[[232, 187, 132],
[232, 187, 132],
[233, 188, 133],
...,
[100, 54, 54],
[ 92, 48, 47],
[ 84, 42, 43]],
#中间省略...
...,
[188, 98, 64],
[188, 95, 62],
[188, 95, 62]]], dtype=uint8)
plt.imshow(img_arr)#展示图片
#执行结果 如下图
数组减去某个值,图片发生变化
import matplotlib.pyplot as plt
img_arr = plt.imread('./part_1/cat.jpg')
img_arr.ndim #当前数组维度
#执行结果
3
img_arr-100
#执行结果
array([[[131, 86, 31],
[132, 87, 32],
[133, 88, 33],
...,
[ 0, 210, 210],
[248, 204, 203],
[241, 199, 200]],
[[132, 87, 32],
[132, 87, 32],
[133, 88, 33],
...,
[ 0, 210, 210],
[248, 204, 203],
[240, 198, 199]],
#中间省略...
...,
[ 88, 254, 220],
[ 88, 251, 218],
[ 88, 251, 218]]], dtype=uint8)
plt.imshow(img_arr - 100)
plt.savefig('./mao.jpg') #保存图片
#执行结果 如下图
将图片进行对称反转操作

import matplotlib.pyplot as plt
img_arr = plt.imread('./part_1/bcy.jpg')
plt.imshow(img_arr[:,::-1,:])
#执行结果如 下图
将图片倒置
plt.imshow(img_arr[::-1,:])
#执行结果如 下图
将图片对称反转并倒置
plt.imshow(img_arr[::-1,::-1])
#执行结果如 下图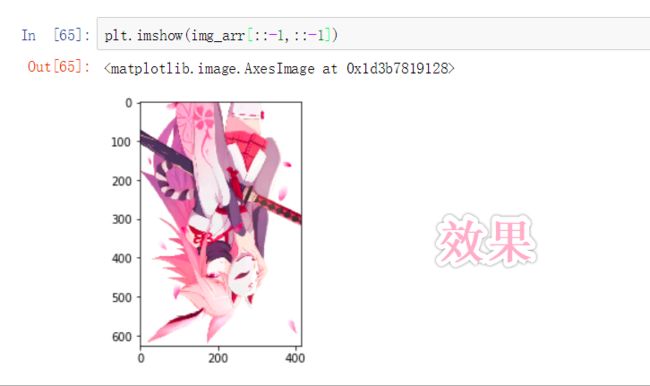
将图片对称反转并倒置并修改颜色
plt.imshow(img_arr[::-1,::-1,::-1])
#执行结果如 下图
对原图做剪裁
plt.imshow(img_arr[450:600,95:330])
#执行结果如 下图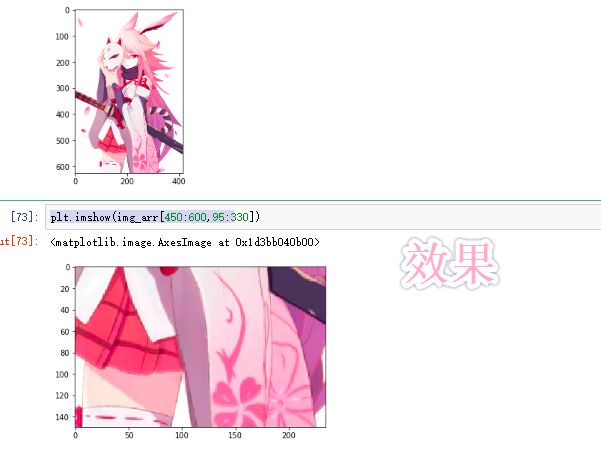
对图片进行拼接
arr_3 = np.concatenate((img_arr,img_arr,img_arr),axis=1)
plt.imshow(arr_3)
#执行结果如 下图
arr_3 = np.concatenate((img_arr,img_arr,img_arr),axis=1)#axis=1 轴向 行
arr_9 = np.concatenate((arr_3,arr_3,arr_3),axis=0)#axis=0 轴向 列
plt.imshow(arr_9)
#执行结果如 下图
学习网站
点击访问
作 者: 郭楷丰
出 处: https://www.cnblogs.com/guokaifeng/
声援博主:如果您觉得文章对您有帮助,可以点击文章右下角
【推荐】一下。您的鼓励是博主的最大动力!
自 勉:生活,需要追求;梦想,需要坚持;生命,需要珍惜;但人生的路上,更需要坚强。
带着感恩的心启程,学会爱,爱父母,爱自己,爱朋友,爱他人。