引言
随着实时数据的日渐普及,企业需要流式计算系统满足可扩展、易用以及易整合进业务系统。Structured Streaming是一个高度抽象的API基于Spark Streaming的经验。Structured Streaming在两点上不同于其他的Streaming API比如Google DataFlow。
第一,不同于要求用户构造物理执行计划的API,Structured Streaming是一个基于静态关系查询(使用SQL或DataFrames表示)的完全自动递增的声明性API。
第二,Structured Streaming旨在支持端到端实时的应用,切将流处理与批处理以及交互式分析结合起来。
我们发现,在实践中这种结合通常是关键的挑战。Structured Streaming的性能是Apache Flink的2倍,是Apacha Kafka 的90倍,这源于它使用的是Spark SQL的代码生成引擎。它也提供了丰富的操作特性,如回滚、代码更新一集混合流\批处理执行。
我们通过实际数据库上百个生产部署的案例来描述系统的设计和使用,其中最大的每个月处理超过1PB的数据。
1.介绍
许多高容量的数据源是实时产生数据的,比如传感器、移动应用程序的日志以及物联网。随着组织在获取这些数据方面做的越来越好,它们将目光放在了处理这些实时数据上,这可以为人类的分析带来最新的数据以及驱动自动决策。支持广泛的流计算访问需要系统易于扩展、易于使用且易于集成到业务应用中。
尽管在过去的几年中分布式流技术取得了巨大的进步,但在实际生产中使用它们还是有不小的挑战。我们从描述这些挑战开始,基于我们在Spark Streaming上的经验,这是最早期的流处理引擎,它提供了高度抽象和函数式的API。
我们发现使用中频繁的出现两种挑战:
第一,流处理系统时常要求用户考虑复杂的物理执行概念,例如at-least-once delivery,状态存储和触发模式,这些都是流处理系统独有的挑战。
第二,许多系统只关注流式计算,但是实际用例中,流通常是大型业务应用的一部分,它包含批处理,会和静态数据进行连接,且会进行交互式查询。集成这些带有其他工作的流处理系统需要大量的工程工作。
基于这些挑战,我们描述结构化流为一种新的用于流处理的高度抽象的API。Structured Streaming吸取了很多流处理系统的点子,比如Google Dataflow的分离事件发生事件和触发器处理时间,使用关系型执行引擎获得更好的性能,以及提供一个综合性的API,旨在使他们更易用且整合进Apache Spark中。特别的,Structured Streaming在两点上和广泛使用的开源流数据处理API不同:
增量查询模型:
Structured Streaming在静态的数据集上通过Spark SQL和DataFrame API表现自动的增量查询,这意味着用户只需要了解Spark批处理API就可以编写一个流数据查询。事件事件概念在这个模型里易于表达及理解。尽管增量查询引擎和试图维护已有深入的研究,但Structured Streaming是第一个广泛使用它们的开源系统。我们发现这个增量的API不仅适用于高级用户,同时也适用于初学者。例如,高级用户可以使用一组有状态的处理操作符实现对自定义逻辑的细粒度控制,同时适用于增量模型。
端到端应用的支持
当与外部系统交互或集成进更大的应用程序时,Structured Steaming的API以及内置的连接器使得编写“默认正确”的代码变得容易。数据的sources和sinks遵循简单的事务模型,默认情况下支持“exactly-once”。基于递增的API使得用批处理作业方式开发一个流式查询以及将流与静态数据的连接变得容易。此外,用户可以动态的管理多个流查询并对流输出的一致性快照做交互式查询。
除了这些设计外,我们还做了其他的一些设计,简化了Structured Steeaming的开发,并增强了其性能。
第一,Structured Streaming重用了Spark SQL的执行引擎,包括它的optimizer和runtime code generator。这样与其他流处理系统相比,Structured Steaming具有了更高的吞吐量。(Flink的两倍,Kafka的90倍),这也让Structured Streaming从Spark SQL以后的更新中受益。引擎默认运行在microbatch的处理模式下,但是对于一些查询,它也可以使用一个低延迟的连续操作。
第二,我们发现,操作一个流处理应用是具有挑战性的,所以我们设计引擎支持对故障、代码更新已输出数据的重新计算。例如,一个常见的问题是流中心的数据导致应用程序崩溃,输出一个错误的结果,用户知道很久以后才会注意到(例如,由于错误解析字段)。在Structured Streaming中,每个应用程序维护一个write-ahead event log(WAL),使用JSON格式,管理者可以从任意点重新启动应用程序。如果应用程序由于用户定义函数中的错误而崩溃,管理员可以更新UDF并且从它停止的地方重启,这时会自动的读取WAL。如果应用程序输出了错误的数据,管理员可以手动的回滚到问题开始之前,重新计算。
我们的团队从2016年开始一直在Databricks的云服务中运行Structured Streaming,以及在内部使用它,所以我们用一些例子来总结本章。生产环境的应用程序范围包括交互式网络安全分析、自动报警增量提取以及ETL过程。最大的客户应用程序每月处理超过1PB的数据,在数百台机器上运行。在雅虎的Streaming Benchmark测试中,Structured Streaming的表现是Flink的2倍,Kafka的90倍。
本文的其余部分组织如下。第二章讨论流处理的挑战,第三章给出Structured Streaming的概述,第四章描述其API,第五章讨论其查询计划,第六章讨论其执行,第七章讨论其操作特性。在第八章,我们描述在Databricks的用例以及用户。第九章我们将要测试系统的性能。第十章讨论相关工作,第十一章总结。
2.流处理的挑战
尽管在过去的几年里取得了广泛的进展,分布式的流应用仍然难以开发和操作。在设计Structured Streaming之前,我们花了很多时间与用户即设计师讨论流处理系统的挑战,包括Spark Streaming、Truviso,Storm,Dataflow以及Flink。
2.1 复杂和低级的API
流系统因为其API语义的复杂被认为相比批处理系统更难于使用。有些复杂性来源于只在流中出现的问题:比如,用户需要考虑在系统接收到全部数据前应输出什么样的中间状态,例如某网站上用户的浏览会话。然而,一起复杂性的出现时因为其低级的API:这些API经常要求用户处理复杂的物理执行操作,达不到声明式级别。
作为一个具体的例子,Google Dataflow有一个功能强大的API,具有丰富的事件处理选项去处理聚合、窗口化和无序数据。然而在这个模型中,用户需要指定窗口模式,触发模式以及触发细化模式。原始API要求用户编写一个物理操作视图,而不是逻辑查询,所以每个用户都需要理解增量处理的复杂性。
其他的APIs,例如Spark Streaming和Flink的DataStream API,也基于编写物理操作的DAG,且提供了复杂的选项去维护状态。此外,应用程序变得更加复杂,这放松了exactly-once语义,要求用户设计和实现一个一致性模型。为了解决这个问题,我们设计了Structured Streaming来实现简单的增量查询模型简单的表示应用程序。此外,我们发现添加可定制的有状态处理操作符仍然支持高级用户构建自己的处理逻辑,比如基于会话的定制、窗口(这些操作符同样可以在批任务中工作)。
2.2 集成到端到端应用程序
我们发现的第二个挑战是几乎所有的流处理任务必须运行在一个更大的应用程序中,这样的集成通常需要大量的工程工作。很多流式APIs主要关注从source输入,并将流输出写入到sink,但端到端的应用程序需要执行其他任务,包括:
(1)应用程序的业务目的可能是对最新数据进行交互式查询。在本例中,一个流处理任务更新RDBMS或者Hive中的汇总表。重要的是,当流作业在更新结果的过程中,它是原子的,用户不要看到部分结果。这对于基于文件的大数据系统比如Hive来说是困难的,Hive中的表被分割到不同的文件,甚至并行的加载到数据仓库。
(2)在ETL作业中可能需要加入从另一个存储系统加载静态数据的流或使用批处理计算进行转换。这种情况下,两者间的一致性就变得异常重要(如果静态数据被更新怎么办?),在同一个API中编写整个计算是很有用的。
(3)一个团队可能偶尔需要用批处理方式运行它的流处理业务逻辑,例如:在旧数据上填充结果或者测试代码的其他版本。用其他系统重写代码既费时又容易出错。
我们通过Structured Streaming来解决这个挑战,它与Spark批处理和交互API紧密结合。
2.3 业务挑战
部署流应用程序的最大挑战之一是实践中的管理和运维。一些关键问题如下:
(1)失败:这是研究中最受关注的问题。除了单节点故障外,系统还需要支持整个应用程序的优雅关闭和重启,例如,操作人员将其迁移到一个新的集群。
(2)代码更新:应用程序很少是完美的,所以开发者需要更新他们的代码。更新之后,他们可能想要应用程序在停止的地方重新启动,或者重新计算由于错误而导致的错误结果。流处理系统的状态管理需要同时支持者两者,且要实现故障恢复机制,系统还应支持运行时更新。
(3)重新调节:随着时间推移,应用程序的负载会发生变化,长期来看,负载会不断增大,所以用户可能希望动态的对其进行缩放,特别是在云中。
(4)落单节点:系统中的节点可能会因为软件或硬件问题而慢下来,这会拖慢整个应用程序的吞吐量,系统应该自动处理这种情况。
(5)监控:流处理系统需要让用户看到系统的负载、状态以及其他的指标。
2.4 性能挑战
除了运营和工程方面的问题,成本效益对于流应用程序可能是一个障碍,因为这些应用程序时24/7运行的。例如,如果没有动态缩放,应用程序会在繁忙时间外浪费资源;即使有了动态缩放,运行一个连续计算的任务可能比运行定期批处理作业更昂贵。因为,我们设计Structured Streaming能利用Spark SQL中的所有执行优化。
到目前为止,我们以吞吐量为主要性能度量,因为我们发现在大规模的流应用程序中,吞吐量通常是最重要的度量。需要分布式流处理系统的应用程序通常有着来自外部数据源的大量数据(例如移动设备、传感器或物联网),数据可能在到达系统时已经产生了延迟。这就是为什么事件时间处理是这些系统中的重要特性。相比之下,延迟敏感的应用程序,如高频交易或物理系统控制循环通常运行在单个放大器上,甚至是定制硬件如ASIC和FPGA上。然而,我们也设计Structured Streaming支持在延迟优化的引擎上执行,并实现了任务的连续处理模式,这些将在第6.3节中进行描述。这与Spark Streaming相比是一个很大的不同。
3 Structured Streaming概述
Structured Streaming旨在解决流处理的挑战,通过API和执行引擎设计的结合。在本节中,我们将简要概述系统的总体情况,图1展示了Structured Streaming的核心组件。
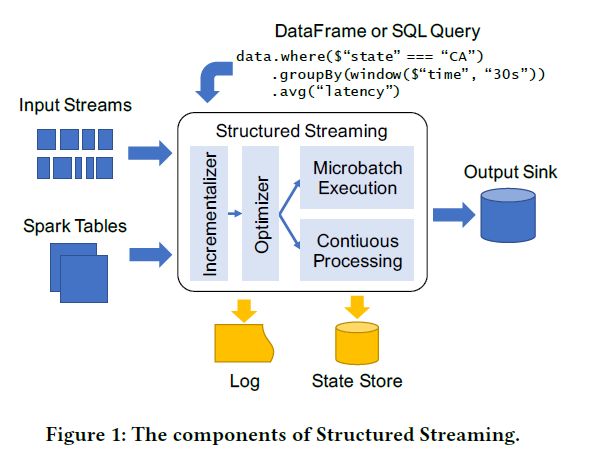
输入和输出
Structured Streaming连接到各种I/O的输入源和输出源。为了提供“exactly-once”的输出以及容错,它对sources和sinks设定了两条限制,和其他的exactly-once系统一样:
(1)输入sources必须可重读,当一个节点崩溃的时候允许系统重新读取最近的输入数据。实践中,组织需要使用可靠的消息总线,比如Kinesis或Kafka,或者一个持久的文件系统。
(2)输出sinks必须支持幂等写操作,确保在节点失败时进行可靠的恢复。Structured Streaming对特定的sinks支持原子输出,作业输出的更新呈现原子性,即使它是由多个并行工作的节点输出的。
除了外部系统,Structured Streaming还支持Spark SQL表的输入和输出。例如,用户可以从Spark的任意批输入源计算一个静态表并将其与流进行连接操作,或请求Structured Streaming输出一个内存中的Spark表用于交互式查询。
API
用户通过Spark SQL的批API:SQL和DataFrame来编写Structured Streaming对一个或多个流或表进行查询。这个查询定义了一个用户想要计算的输出表,并假设每个输入流被替换为一个实时接收数据的数据表。然后引擎决定以增量方式计算和写入输出表到sink中。不同的sink支持不同的输出模式,这决定了系统如何写出其结果:例如,有些sink是append-only的,而另一些允许按键更新记录。
特别的,为了支持流,Structured Streaming增加了几个API功能适应现有的Spark SQL API。
(1)Triggers控制引擎计算的频率
(2)用户可以将一列标记为event time(时间戳),并设置一个watermark决定event time的过期。
(3)有状态操作符允许用户跟踪和更新可变状态,通过键来实现复杂的处理,如定制基于会话的窗口。
Execution
一旦收到一个查询,Structured Streaming会优化它,使其递增化,并开始执行它。默认情况下,该系统使用类似于Spark Streaming离散流的微批模型,支持动态负载,动态缩放,故障恢复。此外,它还支持使用连续处理模型基于传统的长时间运行操作符(6.3节)。
在这两种情况下,Structured Streaming都使用以下两种形式的持久化存储来实现容错。第一,通过WAL日志跟踪哪些数据已被处理并可靠地写入。对于一些sinks,这个日志可以与sink结合以对sink进行原子更新;第二,系统使用大规模的状态存储保存长时间运行的聚合操作的状态快照。这些都是异步写入,并且可能“落后”于最新写入的数据。系统将自动跟踪日志中最后一次更新的状态,并从此处开始重新计算状态。日志和状态存储都可以运行于可插拔存储系统(HDFS或者S3)。
操作特性
使用WAL和状态存储,用户可以实现多种形式的回滚和复原。一个Structured Streaming应用程序可以关闭并在新硬件上重启。运行应用程序也能容忍节点崩溃、添加和掉队,以及向新的node派遣任务。对于UDF的代码更新,停止并重启应用程序就够了,它将开始使用新的代码。此外,用户还可以手动回滚应用程序到日志中之前的一点,重做部分计算,也可以从状态存储的旧快照开始运行。
接下来的章节会描述Structured Streaming API的细节,查询计划以及作业执行和操作。
4 编程模型
Structured Streaming结合了Google Dataflow,增量查询和Spark Streaming来支持Spark SQL API下的流处理。本节中,我们首先展示一个简短的示例,然后在Spark中添加的模型以及特定于流的操作符的语义。
4.1 简短示例
Structured Streaming使用Spark结构化数据APIs:SQL,DataFrame和Dataset。对于用户而言,主要的抽象是tables(由DataFrames或Dataset类表示)。当用户从流中创建table/DataFrame并尝试计算它,Spark自动启动一个流计算。作为一个简单的示例,我们从一个计数的批处理作业开始,这个作业计算一个web应用程序按照国家统计的点击数。假设输入的数据时JSON文件,输出应该是Parquet。这个作业可以用Spark DataFrames写出,如下所示:
//define a DataFrame to read from static data
data = spark.read.format("json").load("/in")
//Transform it to compute a result
counts = data.groupBy($"country").count()
//write to a static data sink
counts.write.format("parquet").save("/counts")
将此作业改为使用Structured Streaming,修改输入和输出源,不需要再中间做转换。例如,如果新的JSON文件继续上传到/in目录,我们可以修改任务通过只更改第一行和最后一行来进行持续更新/计数
//Define a DataFrame to read streaming data
data = spark.readStream.format("json").load("/in")
//Transform it to compute a result
counts = data.groupBy($"country").count()
//Write to a streaming data sink
counts.writeStream.format("parquet").outputMode("complete").start("/counts")
这里的output mode参数指定了Structured Streaming如何更新sink。本例中,complete模式表示为每个更新都写出全量的结果文件,因为选择的sink不支持细粒度更新。然而,其他接收器(如键值存储)支持附加的输出模式(例如,只更新已更改的键)。
在底层,Structured Streaming将由source到sink的转换自动递增化,并以流方式执行它。引擎也将自动维护状态和检查点到外部存储-本例中,存在一个运行的计数聚合,因此引擎将跟踪每个国家的计数。
最后,API自然支持窗口和事件时间,通过Spark SQL现有的聚合操作符。例如,我们不按国家来计数,而是设置一个一小时的滑动窗口,每5分钟滑动一次,根据窗口进行计数
//Count events by windows on the "time" field
data.groupBy(window($“time”,"1h","5min")).count()
这里的time字段(event time)只是数据中的一个字段,类似country。用户还可以在此字段上设置一个watermark让系统在超时后抛弃旧窗口。
4.2 编程模型语义
我们定义了Structured Streaming的语义模型如下:
(1)每个输入源都提供一部分有序的记录。我们假设这里是部分记录是因为一些消息总线系统是并行的且不保证整个记录的顺序——例如Kafka将流分成“分区”。
(2)用户提供一个查询,在输入数据上执行,输出一个结果表(result table),这个结果表可以在任意时间的任意点输出。Structured Streaming在所有输入源中的数据前缀上运行此查询始终会产生一致的结果。也就是说,绝不会发生这样的情况,结果表中合并了一条输入的数据但没有合并在它之前的数据。此外,这些前缀将随着时间推移而增加。
(3)Triggers告诉系统何时运行新的增量计算,何时更新结果表。例如,在microbatch模式下,用户可能每分钟触发一个增量更新。
(4)sink的output mode指定了结果表如何写入到输出系统中。引擎支持以下三种不同的模式:
complete
引擎一次性写出整个结果表,例如,用一个新版本的文件替换HDFS中的整个旧版本文件。当结果很大时,这种方式会非常低效。
append
引擎只能向sink添加记录。例如,一个只有map操作的作业,会单调递增的输出。
update
引擎根据一个键在合适的位置更新sink,只更新发生更改的记录。
图2直观的说明了模型。这个模型中,最具吸引力的一点是结果表的内容(逻辑上只是一个视图,不需要具体化)是独立定义于输出模式(是否需要再每个trigger时输出整个结果表)。
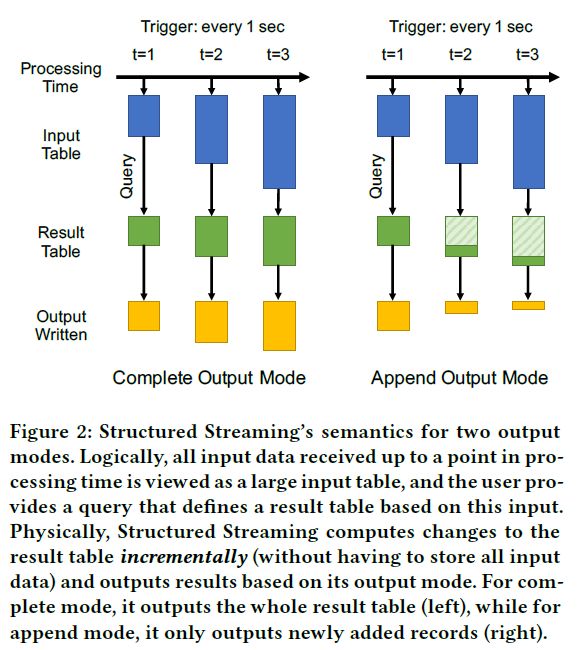
另一个具有吸引力的特性是模型具有很强的一致性语义,我们称之为前缀一致性。首先,它保证当输入记录属于同一个源(例如,日志记录来自同一设备),系统产生的结果会保证其顺序(例如,从不跳过一条记录)。第二,因为结果表是基于同时输入前缀中的所有数据,我们知道在结果表中反映了所有输入记录。相反,在一些基于节点间消息传递的系统中,一个节点接收到一条记录会发送一条更新到下游的两个节点,但不能保证这两个输出是同步的。前缀一致性也使操作更容易,用户可以将系统滚动到WAL(一个数据的特定前缀)中的一点,并从该点开始重新计算。
总之,使用Structured Streaming模型,只要用户可以理解普通的Spark和DataFrame查询,即可了解结果表的内容和将要写入sink的值。用户无需担心一致性、失败或不正确的处理顺序。
最后,读者可能会注意到我们定义的一些输出模式与某些类型的查询不兼容。例如,假设我们按照国家进行聚合技术,如上一节中代码所示,我们希望使用append输出模式。系统没法保证什么时候停止接收某一特定国家的记录,所以这个查询和输出模式的组合不正确。我们将在5.1节中描述允许的组合。
4.3 流中的特定操作符
许多Structured Streaming查询可以使用Spark SQL中的标准操作符写出,比如选择,聚合和连接。然而,为了支持流的一些独有需求,我们在Spark SQL中增加了两个新的操作符:watermarking操作符告诉系统何时关闭一个时间事件窗口和输出结果,并忘记其状态,stateful操作符允许用户写入自定义逻辑以实现复杂的处理。至关重要的是,这两个操作符仍然适合于Structured Streaming的增量语义,且它们都可用于批处理作业。
4.3.1 Event time watermarks
从逻辑的角度来看,event time的关键思想是将应用程序指定的时间戳看为数据中的任意字段,允许记录不按照顺序到达。我们可以使用标准运算符和增量运算符更新以event time分组的结果。实践证明,对于处理系统而言,设置一些关于数据延迟到达的宽松界限是十分有用的,以下是两个原因:
(1)允许任意延迟的数据可能需要存储任意大的状态。例如,如果我们按照1分钟的event time窗口对数据进行计数,系统需要记录每一个1分钟的窗口计数,因为迟到的数据可能属于任意一分钟。这将迅速导致大量的状态。
(2)一些sinks不支持数据回退,这使得它能在超时后为指定的event time写出结果。例如,自定义下游应用程序希望使用“最终”结果启动工作,但是它不支持回退。append输出模式的sink也不支持回退。
Structured Streaming允许开发人员为event time列设置一个watermark,使用withWatermark操作符。这个操作符在一个给定的时间戳列C上设置一个系统的延迟阈值Tc。在任意时间,C的watermark为max(C)-Tc.请注意,这种watermark是健壮的,可以防止积压数据:如果系统在一段时间内无法跟上输入速率,则watermark不会随意的往前移动,所有在T秒内到达的时间仍会被处理。
如果watermark存在,它会影响有状态操作符忘记旧状态,Structured Streaming可以以append模式输出数据到sink。不同的输入流会有不同的watermarks。
4.3.2 Stateful Operators
对于想要编写流处理逻辑的开发人员,Structured Streaming有状态的操作符(具有状态的UDF)可以让用户在计算的同时融入Structured Streaming以及容错机制。有两种有状态操作符,mapGroupsWithState和flatMapGroupsWithState。这两种操作符会对数据指定一个key并使用groupByKey操作,并允许开发人员定制跟踪和更新每个键的state,以及每个键的输出记录。它们的基础是Spark Streaming的updateStateByKey操作符。
mapGroupsWithState操作符,用于分组数据集,数据集中的键类型为K,值的类型为V,接收用户定义的具有以下参数的update function:
(1)key of type K
(2)newValue of type Iterator[V]
(3)state of type GroupState[S],where S is a user-specified class
//define an update function that simply tracks the
//number of events for each key as its state, returns
//that as its result, and times out keys after 30min
def updateFunc(key:Userid, newValues:Iterator[Event],
state:GroupState[Int]):Int = {
val totalEvents = state.get() + newValues.size()
state.update(totalEvents)
state.setTimeoutDuration("30 min")
return totalEvents
//Use this update function on a stream,returning a
//new table lens that contains the session lengths
lens = events.groupByKey(event => event.userId).
mapGroupsWithState(updateFunc)
当一个键接收到新的值时,运算符将调用这个函数。每次调用时,都会接收到从上次调用到现在该键接收到的所有值(为了提高效率,可以对多个值进行批处理)。同样能接收到一个被用户定义的数据类型S所包围的state对象,允许用户更新状态,从状态跟踪中删除此键,或者为这个特定的键设置超时时间。这允许用户为Key存储任意数据,以及为删除状态实现自定义逻辑(实现基于会话窗口的退出条件)。
最后,update函数返回用户指定的返回类型R。mapGroupsWithState的返回值是一个新表,包含了数据中每组的最终R条输出记录(当group关闭或者超时)。例如,开发人员希望使用mapGroupsWithState跟踪用户在网站上的会话,并输出为每个会话点击的页面总数。
图3展示了如何使用mapGroupsWithState跟踪用户会话,其中会话被定义为一系列事件,使用相同的用户标识,他们之间的间隔不到30分钟。我们在每个会话中输出时间的最终数量作为返回值R。然后,一个作业可以通过聚合结果表计算每个会话时间数的平均值。
另一个有状态操作符,flatMapGroupsWithState跟mapGroupsWithState十分相似,但是其更新函数每次更新时可以返回0或者更多,而不只是1。例如,这个操作符可以用来手动实现stream-to-table的join操作。这两个操作符也可以在批处理模式下工作,但是其更新函数只会被调用一次。
五.查询计划
我们使用Spark SQL中的Catalyst可扩展优化器实现Structured Streaming中的查询计划,这允许使用Scala中的模式匹配写入可组合规则。查询计划分三个阶段:(analysis)分析确定查询是否有效、(incrementalization)递增化以及(optimization)优化。
5.1 Analysis
查询计划的第一个阶段是analysis,在这个阶段引擎会验证用户的查询并解析属性和数据类型。Structured Streaming使用Spark SQL现有的analysis解析属性和类型,但是增加了新规则,检查查询是否可被引擎递增执行。本阶段还检查了用户选择的输出模式是否对此查询有效。例如,Append模式只能用于输出为单调的查询:也就是说,一条输出记录一旦被写出就不会被移除。这种模式下,只有包含event time的选择、连接和聚合是被允许的(这种情况下,引擎只有在watermark过期时才会输出该值)。类似的,在complete输出模式下,trigger每次触发时都要写出整张表。在Structured Streaming的官方文档中可以获得输出模式的完整描述。
5.2 Incrementalization
查询计划的下一步是将用户提供的静态查询递增化,以有效的在新数据来临时更新结果。一般来说,Structured Streaming的增量化器确保查询的结果在新数据接收时及时被更新,而不依赖于目前收到的总行数。
引擎可以递增化一个受限制的、不断增长的查询。从Spark2.3.0版本开始,支持的查询包括:
-任意数量的选择,投影和select distincts。
-流和表,两个流之间的内连接、左外连接和右外连接。对一个流进行外部连接,连接条件必须包含一个watermark。
-有状态操作符比如mapGroupsWithState
-最多一个聚合(可能在复合键上)
-聚合后的排序,只能在complete输出模式下
引擎使用Catalyst转换规则将这些支持的查询映射为物理执行树,执行计算和状态管理。例如,用户查询中的一个聚合可能会映射到有状态聚合操作符,并跟踪Structured Streaming中的开放组的状态存储和输出。在内部,Structured Streaming还跟踪在增量化过程中产生的DAG重的每个物理操作符的输出模式,类似于Dataflow中的细化模式。例如,一些操作会更新已发出的记录(相当于update模式),另一些值更新发出的新记录(append模式)。至关重要的是,在Structured Streaming中,用户不必手动指定这些内部的DAG模式。
增量化是Structured Streaming研究中的一个活跃领域,但我们发现,即使是现今的很多受限的查询集也适用于很多用例。在其他情况下,用户利用Structured Streaming有状态的操作符实现自定义增量处理逻辑,以保持其选择的状态。我们希望在引擎中增加更剑仙的自动化递增技术。
5.3 Query Optimization
查询计划的最后一个阶段是优化。Structured Streaming应用了Spark SQL中的大多数优化规则,例如谓词下推,投影下推,表达式简化等。此外,对于内存中的数据,使用Spark SQL的Tungsten二进制格式(避免Java内存开销),它的运行时代码生成器用于将连接符编译为Java字节码。这个设计意味着Spark SQL中的大多数逻辑和执行的优化能自动的应用到流上。
六.应用程序执行
Structured Streaming的最后一个组成部分是它的执行策略。本节中,我们将描述引擎如何跟踪状态,然后是两种执行模式:基于细粒度任务的微批以及基于长时操作符的连续处理。然后,我们讨论能够简化Structured Streaming应用程序管理和部署的操作特性。
6.1 状态管理和恢复
在高层次抽象上,Structured Streaming以Spark Streaming类似的方式跟踪状态,不管在微批还是连续模式中。使用两个外部存储跟踪应用程序的状态:支持持久的、原子、低延迟写入的WAL日志,可以存储大量数据并允许并行访问的state store(S3或HDFS)。Structured Streaming使用这两种系统进行失败恢复。引擎对sources和sinks在容错上提出了两个要求:第一,sources必须是可重放的,允许使用某种形式的标识符重读最近的数据,比如流偏移量。持久化的消息总线系统比如Kafka和Kinesis满足这个要求。第二,sinks应该是幂等的,允许Structured Streaming在失败时重写一些已经存在的数据。sinks可以用不同的方式实现它。
鉴于这些属性,Structured Streaming使用以下机制来进行状态跟踪,如下图所示:
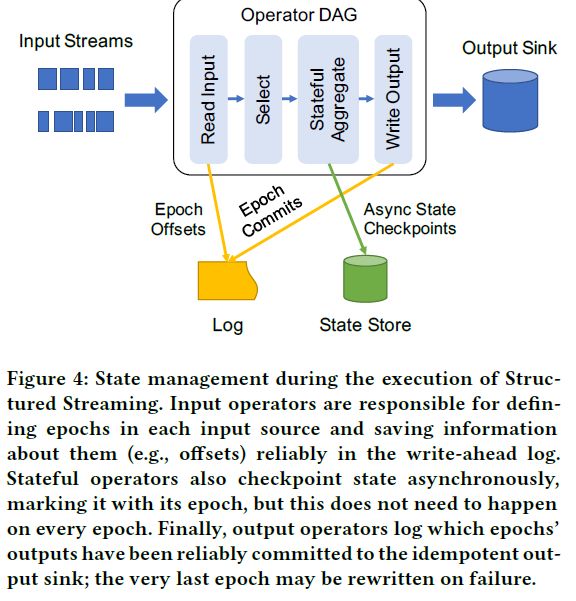
(1)当输入操作读取数据时,Spark的Master根据每个输入源中的offsets定义epochs。例如,Kafka和Kinesis将topic呈现为一系列分区,每个分区都是字节流,允许读取在这些分区上使用偏移量的数据。Master在每个epoch开始和结束的时候写日志。
(2)任何需要定期、异步检查state store中状态的操作都尽可能使用增量的检查点。它们同时存储了epoch ID和每个检查点。这些检查点不需要在每个epoch都发生或阻塞处理。
(3)输出操作将提交的epoch写入日志。Master节点在提交下一个epoch前等待所有运行操作的节点报告。根据sink的不同,如果sink支持多节点写入,Master会运行多个节点完成写入。这意味着如果流应用程序失败,只有一个epoch会被部分写入。
(4)恢复后,应用程序的新实例会查找log中最后一个未被提交到sink的epoch,其中包括其开始和结束offsets。然后使用之前epoch的offset重建应用程序内存内的状态。这只需要加载旧的状态并运行那些epoch,使用其禁用输出时相同的偏移量。最后,系统重新运行上一个epoch,依赖于sink的幂等性写出结果,然后开始新的epoch。
最后,状态管理中的所有设计对用户代码来说都是透明的。聚合操作和用户自定义状态管理操作(例如mapGroupsWithState)自动向state store中存储检查点,不需要用户自己编码实现。用户的数据类型只需要序列化即可。
6.2 微批处理模式
Structured Streaming的任务可以以两种模式运行:微批和连续操作。微批模式使用离散化的流执行模型,这是从Spark Streaming的经验中得来,并继承了它的有点,比如动态负载平衡,缩放,掉队,不需要整个系统回滚的故障恢复。在这种模式下,epoch通常设置为几百毫秒到几秒,每个epoch作为一个传统Spark任务由一系列独立的task组成DAG。和Spark Streaming一样,这种模式具有以下优点:
(1)动态负载平衡:每个操作都可以被分成很小的、独立的task在多个节点上进行调度,这样系统就可以自动平衡这些节点(如果某些节点执行速度比其他节点慢)。
(2)细粒度的故障恢复:如果节点失败,则可以仅仅执行其上的任务,而无需回滚整个集群到某检查点,这和大多数基于拓扑的系统一样。此外,丢失的任务可以并行的重新运行,这可以进一步减少恢复时间。
(3)失效节点处理:Spark将启动备份副本,就像他在批处理作业中所做的,下游任务也会使用最先完成的输出。
(4)重新调节:添加或删除节点与task一样简单,这将自动在所有可用节点上自动调度。
(5)规模和吞吐量:因为这个模式重用了Spark的批处理执行引擎,它集成了这个引擎所有的优化,比如高性能的shuffle实现以及在数千个节点上运行的能力。
这种模式的主要缺点是延迟时间长,因为在Spark中启动任务DAG是有开销的。然而,几秒的延迟在运行多步计算的大型集群上是可以实现的。
6.3 连续执行模式
在Spark 2.3中添加了一个新的连续处理引擎,它使用long-lived操作,如同传统的流系统Telegraph和Borealis。这种模式的延迟较低,单操作灵活度较低(对在运行时重新调整作业的支持有限)。
这种执行模式的关键是选择声明性的API,不绑定到Structured Streaming的执行策略。例如,最早的Spark Streaming API有一些基于处理时间的操作泄露了微批的概念,这使其难以自动程序到另一种类型的引擎。相反,Structured Streaming的API和语义独立于之执行引擎:连续执行类似于更多的trigger。注意,与纯粹基于非同步的消息传递系统不同,如Storm,我们保留了trigger和epoch的概念在这个模型里,以便多个节点的输出可以协调并一起提交到sink。
因为API支持细粒度的执行,所以Structured Streaming的作业理论上可以运行在任何分布式的流引擎上。在连续处理引擎中,我们在Spark建立了一个简单的连续操作引擎,并且可以重用Spark的基础调度引擎和每个节点的操作符(代码生成操作)。Spark 2.3.0中的第一个版本只支持类似map的任务(没有shuffle操作),这是用户最常见的场景,但是后续的设计将会加入shuffle操作。
相比于批处理引擎,持续处理有两点不同:
(1)master节点在输入源的每个partition上启动一个long-running任务,但是启动多个epoch。如果其中一个任务失败了,Spark会重启它。
(2)epoch的协调是不同的。Master节点定期告诉node启动一个新的epoch,并接收每个输入partition上的一个开始offset,并将其写入WAL中。当要求node启动下一个epoch时,Master节点会接收到上一个epoch的结束offset,并将其写入WAL,当写入了所有结束offset后,会告诉节点提交这个epoch。
八.生产用例
我们在2016年就在Databricks的managed cloud service中支持了Structured Streaming,今天,我们的云上24小时7天不间断的运行着数百个生产环境流应用程序。其中最大的每月处理超过1PB数据,且运行在数百台服务器上。我们也用Structured Streaming去监控我们的服务,其中也包括Structured Streaming自身的运行。本节上,我们描述三种不同的客户工作负载,以及我们的内部用例。
8.1 信息安全平台
一个大客户使用Structured Streaming开发一个大规模的安全平台,允许超过100个分析通过网络流量日志快速识别和响应安全事件,以及自动生成报警。这个平台将流与批处理和交互相结合,是一个端到端应用程序的好例子。

图5展示了这个平台的架构。IDS(intrusion detection system)监控组织上所有的网络流量,并将日志写入S3。从这里开始,一个Structured Streaming的ETL作业存储到一个紧凑的基于Apache Parquet的表中,存放于Databricks Delta,允许下游应用程序快且并发的访问。其他的Structured Streaming作业将这些日志产生附加的表(通过和其他数据的连接操作)。分析师交互的查询这些数据,使用SQL或者Dataframe,从而检测和诊断新的攻击模式。如果他们找到了危害,他们会回顾历史数据跟踪来自该攻击者的活动。最后,并行的,另一个Structured Streaming的集群会处理Parquet日志根据预先编写的规则生成实时的警报。
这个平台最大的挑战在:
(1)构建一个健壮且伸缩性强的流管道
(2)给分析人员提供一个高效的环境去查询新老数据。
使用AWS上提供的标准工具和服务,一个20人的团队花了6个多月的时间来构建和部署此平台的最初版本。这个最初版本有很多的限制,比如只能存储一小部分历史数据由于使用传统的数据仓库。相比之下,一个五人的工程师团队能够在两周内使用Structured Streaming重构这个平台。这个新平台支持更好的扩展性,且能够支持更复杂的分析,这是因为可以使用Spark ML API。接下来,我们提供一些例子来说明Structured Streaming的优点使这些成为可能。
首先,Structured Streaming能够自适应批的规模,使得开发人员可以构建一个能够处理大量工作的流管道,同时还能满足故障和代码升级。考虑一个流作业,它可能因为失败而离线,或者进行一次升级。当集群恢复上线时,它会开始自动处理离线时未处理的数据。最初,集群将使用大量的批处理去最大化吞吐量。一旦赶上,集群会切换为低延迟的小批量进行处理。这允许管理员定期升级集群,无需担心过度停机。
第二,Structured Streaming可以与其他流进行join操作,与历史表也可以,这样大大简化了分析。考虑一个简单的任务,识别哪个设备是来源于TCP连接的。事实证明,这项任务是具有挑战性的,因为移动设备的存在,因为这些设备的IP地址在每次它们加入网络时都是动态的。因此,只依靠TCP日志,不可能跟踪终端的连接。使用Structured Streaming,分析人员能够简单的解决这个问题。她可以简单的将TCP日志与DHCP日志进行join,将IP地址和MAC地址映射起来,然后使用组织内部的数据网络设备映射到MAC地址特定的机器和用户。另外,用户也可以即时的使用stateful operator进行join操作。
最后,使用相同的系统开发流、交互式查询和ETL为开发人员提供了快速迭代的能力,以及部署新的警报。特别的,它使得分析师能够构建和测试对检测脱机数据供给的查询,然后将这些查询部署在报警集群上。在一个例子中,一个分析师通过DNS开发了一个查询识别攻击。在这次攻击中,恶意软件通过将此信息装载到DNS中泄露机密信息,从而危及主机发送到攻击者拥有的外部DNS服务器的请求。一个用于检测这种攻击的简化查询实际上计算了在一定时间间隔内每个主机发送的DNS请求的总大小。如果聚合大于给定的阈值,则查询标记对应的主机可能受到危害。分析师利用历史数据来设置这个阈值,从而达到平衡假正率和假负率之间的期望平衡。一旦满足了结果,分析人员会简单地将此查询推到报警集群中去。
九.性能评价
本节中,我们将使用控制基准度量Structured Streaming的性能。我们在Yahoo的Streaming Benchmark研究Structured Streaming与其他系统的性能,可伸缩性,吞吐量-延迟与连续处理之间的权衡。
9.1 性能 vs 其他流系统
为了评估Structured Streaming相比于其他流引擎的性能,我们使用Yahoo的流基准平台,一个在开源系统中广泛使用的工作负载。此基准测试要求系统读取广告点击事件,并按照活动ID加入到一个广告活动的静态表中,并在10秒的event-time窗口中输出活动计数。我们比较了Kafka Streams 0.10.2、Apache Flink 1.2.1和Spark 2.3.0,在一个拥有5个c3.2*2大型Amazon EC2 工作节点和一个master节点的集群上(硬件条件为8个虚拟核心和15GB的内存)。对于Flink,我们使用优化版本的benchmark由dataArtisans发布。就像那个benchmark一样,系统从一个拥有40个partition(每个内核一个)的kafka集群中读取数据,并将结果写入kafka。最初的Yahoo benchmark使用redis保存用于连接的静态表,但是我们发现redis可能是一个瓶颈,所以我们用每个系统中的一个表替换它(Kafka中的KTable,Spark中的DataFrame,Flink中的in-memory哈希表)。

图6(a)展示了每个系统最大稳定吞吐量(积压前的吞吐量),我们发现流系统的性能有着很大的不同。Kafka Stream通过kafka消息总线实现了一个简单的消息传递模型,但在我们拥有40个core的集群上性能只有每秒70万记录。Flink可以达到3300万。而Structured Streaming可以达到6500万,近乎两倍于Flink。这个特殊的Structured Streaming查询使用没有UDF代码的DataFrame操作实现。这个性能完全来自于Spark SQL的内置执行优化,包括将数据存储在紧凑的二进制文件格式以及代码生成。正如作者指出的那样,对于Trill和其他类型,对于流过程,执行优化可以产生很大的影响。
9.2 可伸缩性
图6(b)展示了Structured Streaming的性能在我们改变集群大小时的变化。我们使用1,5,10,20个c3.2xlarge Amazon EC2 worker。我们可以看到吞吐量的伸缩近乎为线性,从一个节点的11.5 million每秒到20个节点时的225 million每秒。
9.3 连续处理
我们在一台4核服务器上对Structured Streaming的连续处理模式进行基准测试,该测试展示了延迟-吞吐量的权衡(因为分区是独立运行的,我们希望延迟与节点数量保持一致)。

图7展示了一个map任务的结果,这个map任务从Kafka中读取数据,虚线展示了微批模式能达到的最大吞吐量。可以看到,在连续模式下,吞吐量不会大幅下降,但是延迟会更低。(小于10毫秒的延迟,只有微批处理模式最大吞吐量的一半)。它的最大稳定吞吐量也略高,因为微批处理模式由于任务调度而导致延迟。
结论
流应用是很有效的工具,但是流系统仍然难于使用,操作和集合进更大的应用系统。我们设计Structured Streaming来简化这三个任务,同时与Apache Spark的其余部分进行集成。不同于其他的开源流引擎,Structured Streaming采用非常高级的API:增量化现有的Spark SQL或DataFrame查询。这使得它可以被用户广泛使用。尽管Structured Streaming的API更具声明性和约束性,但是我们发现,它在不同的范围内都能很好的工作,包括哪些需要有状态的自定义逻辑。除此之外,Structured Streaming还有其他一些强有力的特性,并且使用Spark SQL能实现更高的性能。数百个用户用例表明可以利用Structured Streaming构建复杂的业务应用程序。