前言:
在前一篇中,介绍了如何准备数据与预处理数据。
正文:
本文将介绍模型的搭建以及如何训练
1、 模型开发流程
先上一张深度学习模型开发流程图,让大家对此有个基本印象:
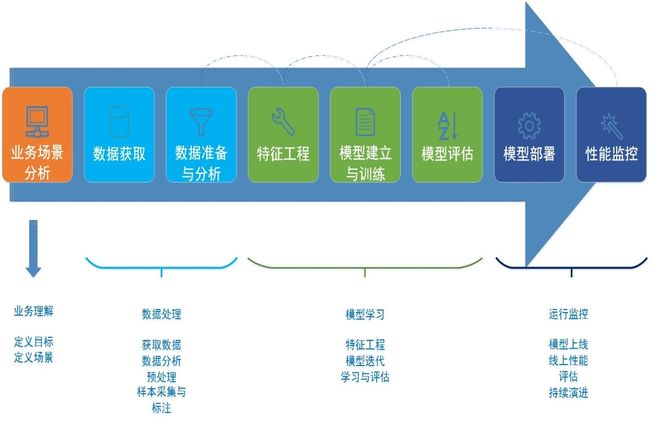
第一步:分析业务场景,理解功能需求;
第二步:数据获取,首先进行数据导入,存放在数据库中,然后使用相应的算法工具对数据进行整理和清洗,从而得到过滤好的有效数据,最后统一进行数据标注。
第三步:在模型模块中,先导入在数据模块中标注好的数据,接着设计相应的算法模型,配置好各种参数,然后开始训练模型,训练出的模型在部署前需要先验证,以确保该模型速度和精度都能满足要求。如果训练出的模型效果没有问题,接下来就可以部署到真实环境中去。反之,需要不断迭代算法与模型参数,直到训练出的模型达到要求为止。
第四步:将训练好的模型部署到实际环境中,同时对模型的性能进行监控,以便后续进一步优化。
2、模型结构搭建:
一般情况下,回归模型一般可以直接使用sklearn机器学习包就可以实现,但一般针对的是小数据量的模型(几百条记录)。
为了提高在中大型数据量上的模型效果,本文采用了tensorflow框架来搭建回归模型,模型的代码结构如下:
taflow(主目录)
./config
--config.py
''' !/usr/bin/env python3 -*- coding:utf-8 -*- filename:config.py author:jim.chen create date:9/9/2019 ''' from easydict import Easydict as edict __C = edict() cfg = __C __C.TRAIN = edict() __C.TRAIN.EPOCHS = 20000 __C.TRAIN.DISPLAY_STEP = 100 ... __C.TRAIN.SUMMARY_DIR = 'summary/' __C.TRAIN.DATASETS_PATH = 'datasets' __C.TRAIN.DATASETS_NAME= 'ac.txt' __C.TRAIN.CKPT_DIR='checkpoint' __C.PB_DIR='protobuf/' __C.TEST = edict() __C.TEST.BATCH_SIZE = 1 __C.TEST.SAVEPNG_DIR = 'figure/'
./datasets
--ac.txt
1 8 121.418 31.148 9 121.317 31.208 1 3 0 2 4 5 0 26
1 18 121.317 31.208 19 121.418 31.148 1 3 0 2 4 5 0 26
...
./preprocessing
--dataset.py
''' !/usr/bin/env python3 -*- coding: utf-8 -*- filename:dataset.py author:jim.chen create date:9/16/2019 ''' #import numpy as np import os import math import random from sklearn import preprocessing from sklearn.model_selection import train_test_split from config import config CFG = config.cfg ''' datasets acsetting sample data: 1.AC_START_TIME time() 2.AC_START_PLACE gps() long,lat 3.AC_STOP_TIME time() 4.AC_STOP_PLACE gps() long,lat 5.WIND_DIRECTION value:face 0,body 1,feet 2 6.WIND_POWER value:1,2,3,4,5,6 7.CIRCLE_IN_OUT value:in 0/out 1 8.TEMP_IN_CAR value:-40~50 9.TEMP_OUT_CAR value:-40~50 10.TEMP_OUTDOOR value:-40~50 11.CUR_MONTH value:JAN/FEB... 12.CLOSE_AFTER_1MIN value:TRUE 1/FALSE 0 12.TEMP_AC_SETTING value:-40~50 13.NEED_AC_SEETING value:YES 1/NO 0 exaple in ac_temp.txt total:17 result:16/17 time() place() curmonth curday hour_start long_start lat_start hour_stop long_stop lat_stop direct power circleinout tempincar tempoutcar tempoutdoor closeafter1min tempac needac 9 16 9 121.418 31.148 10 121.317 31.208 0 2 0 25 27 27 0 0 0 ''' class dataset(object): ''' ''' def __init__(self,is_train=True): self._split_dataset2trainval() dataset_x,dataset_y1=self._load_ac_dataset(is_train) self._x = dataset_x self._y1 = dataset_y1 #self._y2 = dataset_y2 #print('__init__ data datasets_x:\n',datasets_x) #print('__init__ data datasets_y1:\n',datasets_y1) #list_txt = np.concatenate(np.array(datasets_x), np.array(datasets_y1), axis=1) #print('__init__ data list_txt:\n',list_txt) #print('__init__ data datasets_y2:\n',datasets_y2) #x=np.column_stack([x,x_3]) #random add 3 col ,x change to 16col #print('__init__ data x:',x) #print('__init__ data self._x:',self._x) #self.preprocess() def _load_ac_dataset(self,is_train): data_x = [] data_y1 = [] #data_y2 = [] cwd = os.getcwd() if is_train == True: txt_name = os.path.join(cwd,CFG.TRAIN.DATASETS_PATH,'train.txt') else: txt_name = os.path.join(cwd,CFG.TRAIN.DATASETS_PATH,'val.txt') print('_load_ac_dataset data txt_name:',txt_name) line_count = len(open(txt_name, 'r').readlines()) print('_load_ac_dataset data line_count:',line_count) try: with open(txt_name,'r') as r_f: for each_line in r_f: data = each_line.strip().split(' ') num_feature = len(data) #print('_load_ac_dataset num_feature :',num_feature) data_x.append(data[:num_feature-1]) data_y1.append(data[num_feature-1]) #data_y2.append(data[num_feature-1]) except IOError: print('_load_ac_datasets IOError:',IOError) finally: return data_x,data_y1 #,data_y2 def _split_dataset2trainval(self): txt_list=[] cwd = os.getcwd() txt_name = os.path.join(cwd,CFG.TRAIN.DATASETS_PATH,CFG.TRAIN.DATASETS_NAME) with open(txt_name,"r") as r_f: for each_line in r_f: txt_list.append(each_line) #txt_list.sort() print("len(txt_list):",len(txt_list)) train=random.sample(txt_list,int(math.floor(len(txt_list)*4/5))) #train.sort() print("train:\n",train) print("len(train):",len(train)) val=list(set(txt_list).difference(set(train))) print("val:",val) print("len(val):",len(val)) enum_train_val=['train','val'] for item in enum_train_val: txt_name = os.path.join(cwd,CFG.TRAIN.DATASETS_PATH,item+'.txt') with open(txt_name,'w') as w1_f: for num_item in eval(item): #print("num_item:",num_item) w1_f.write(num_item) #os.remove(list_txt) w1_f.close() return def _preprocess(self): train_x_disorder,test_x_disorder,train_y_disorder,test_y_disorder=train_test_split(self.x,self.y,train_size=.8,random_state=33) #datasets preprocessing standardize ss_x = preprocessing.StandardScaler() train_x_disorder = ss_x.fit_transform(train_x_disorder) test_x_disorder=ss_x.transform(test_x_disorder) ss_y = preprocessing.StandardScaler() train_y_disorder = ss_y.fit_transform(train_y_disorder.reshape(-1,1)) test_y_disorder=ss_y.transform(test_y_disorder.reshape(-1,1)) return train_x_disorder,test_x_disorder,train_y_disorder,test_y_disorder def main(): datasets_ac_train = dataset(True) print('main data datasets_ac_train._x:\n',datasets_ac_train._x) print('main data datasets_ac_train._y1:\n',datasets_ac_train._y1) datasets_ac_val = dataset(False) print('main data datasets_ac_val._x:\n',datasets_ac_val._x) print('main data datasets_ac_val._y1:\n',datasets_ac_val._y1) #print('__init__ data datasets_ac._y2:',datasets_ac._y2) #datasets_ac._split_dataset2trainval() if __name__ == '__main__': main()
./model
--basenet.py
''' !/usr/bin/env python3 -*- coding: utf-8 -*- filename:basenet.py author:jim.chen create date:9/16/2019 ''' import tensorflow as tf #tf.__version__ :>1.14.0 import glog as log class basenet(object): ''' base model for other specific cnn ''' def __init__(self): pass def weight_variable(self,shape): initial=tf.random.truncated_normal(shape=shape,stddev=.1) return tf.Variable(initial) def bias_variable(self,shape): initial=tf.constant(.1,shape=shape) return tf.Variable(initial) def conv2d(self,x,w,s=1,padding='SAME'): if s == 1: x = tf.nn.conv2d(x,w,strides=[1,s,s,1],padding=padding) else: x = tf.nn.conv2d(x,w,strides=[1,s,s,1],padding=padding) log.info('basenet conv2d x:{:}'.format(x.get_shape().as_list())) return x def maxpool(self,x,k=2,s=2,padding='SAME'): x= tf.nn.max_pool(x,ksize=[1,k,k,1],strides=[1,s,s,1],padding=padding) return x def relu(self,x): x = tf.nn.relu(x) return x def relu6(self,x): x= min(max(0,x), 6) x = tf.nn.relu(x) return x def wx_b(self,x,w,b): x = tf.matmul(x,w)+b log.info('basenet wx_b x:{:}'.format(x.get_shape().as_list())) return x def fc(self,x,w,b): x = tf.add(tf.matmul(x,w),b) log.info('basenet fc x:{:}'.format(x.get_shape().as_list())) return x
--ac_cnn.py
''' !/usr/bin/env python3 -*- coding: utf-8 -*- filename:ac_s_cnn.py author:jim.chen create date:9/16/2019 ''' import tensorflow as tf #tf.__version__ :>1.14.0 import glog as log from config import config from model import basenet CFG = config.cfg class ac_s_cnn(basenet.basenet): def __init__(self): super(simple_cnn,self).__init__() self.xs = tf.compat.v1.placeholder(tf.float32,[None,CFG.TRAIN.FEATURE_X_SIZE*CFG.TRAIN.FEATURE_Y_SIZE]) self.ys = tf.compat.v1.placeholder(tf.float32,[None,1]) #self.rate = tf.compat.v1.placeholder(tf.float32) def conv_stage(self,net,ksize_x,ksize_y,in_ch,out_ch): #feature_size = net.get_shape().as_list() #log.info('simple_cnn conv_stage feature_size:{:}'.format(feature_size)) #log.info('simple_cnn conv_stage ksize:{:},in_ch:{:},out_ch:{:}'.format(ksize,in_ch,out_ch)) w = self.weight_variable([ksize_x,ksize_y,in_ch,out_ch]) b = self.bias_variable([out_ch]) net = self.conv2d(net,w)+b net = self.relu(net) #log.info('simple_cnn conv_stage net:{:}'.format(net.shape)) return net def fc_stage(self,net,ksize_x,ksize_y,in_ch,out_ch,act_fn=False): #feature_size = net.get_shape().as_list() #log.info('simple_cnn fc_stage feature_size:{:}'.format(feature_size)) w = self.weight_variable([ksize_x*ksize_y*in_ch,out_ch]) b = self.bias_variable([out_ch]) net = self.wx_b(net,w,b) if act_fn: net = self.relu(net) #log.info('simple_cnn fc_stage net:{:}'.format(net.shape)) return net def model(self,net): ''' input: -1x5x3x1 conv1:[2,2,1,32] ->[-1,5,3,32] conv2:[2,2,32,64] ->[-1,5,3,64] reshape -1,5,3,64->[-1,5x3x64] fc1:[5x3x64,512] ->[-1,512] fc2:[512,1] ->[-1,1] ''' net = self.conv_stage(net,2,2,1,CFG.TRAIN.CONV1_SIZE) log.info('ac_s_cnn conv1 net:{:}'.format(net.shape)) net = self.conv_stage(net,2,2,CFG.TRAIN.CONV1_SIZE,CFG.TRAIN.CONV2_SIZE) log.info('ac_s_cnn conv2 net:{:}'.format(net.shape)) net = tf.reshape(net,[-1,CFG.TRAIN.FEATURE_X_SIZE*CFG.TRAIN.FEATURE_Y_SIZE*CFG.TRAIN.CONV2_SIZE]) log.info('ac_s_cnn reshape net:{:}'.format(net.shape)) net = self.fc_stage(net,5,3,CFG.TRAIN.CONV2_SIZE,CFG.TRAIN.FC1_SIZE,act_fn=True) log.info('ac_s_cnn fc1 net:{:}'.format(net.shape)) net = self.fc_stage(net,1,1,CFG.TRAIN.FC1_SIZE,CFG.TRAIN.CLASSES_NUM) log.info('ac_s_cnn fc2 net:{:}'.format(net.shape)) return net
./evaluation
--evaluation.py
''' !/usr/bin/env python3 -*- coding: utf-8 -*- filename:evaluation.py author:jim.chen create date:9/6/2019 ''' import os import glog as log import matplotlib.pyplot as plt from sklearn.metrics import accuracy_score import numpy as np from config import config CFG = config.cfg #accuracy for regression def plot_show_effect(label,pred): fig = plt.figure(figsize=(20,5)) axes = fig.add_subplot(1,1,1) print('plot_show_effect label:',label) print('plot_show_effect pred:',pred) #pred_= np.round(np.abs(pred)) pred_= np.floor(np.abs(pred)) label_a = np.array(label) true_val = label_a.astype(float) print('plot_show_effect true_val:',true_val) pred_val = np.squeeze(pred_.reshape(pred_.shape[1],pred_.shape[0])) print('plot_show_effect pred_val:',pred_val) line1,=axes.plot(range(len(pred_val)),pred_val,'b--',label='pred',linewidth=1) line2,=axes.plot(range(len(true_val)),true_val,'g',label='real') axes.grid() plt.legend(handles=[line1,line2]) plt.title('Air-conditioning',fontsize=10,fontweight='bold',color='red') plt.xlabel('epoch',fontsize=16) plt.ylabel('temperature',fontsize=16) plt.ylim(0,30) plt.savefig(os.path.join(CFG.TEST.SAVEPNG_PATH,str(CFG.TRAIN.EPOCHS)+'.png'),bbox_inches='tight') plt.show() def addonedim(list_val): new_list = list[:,np.newaxis] print('addonedim new_list:',new_list) return new_list def delonedim(list_val): #squeeze all dim=1 #np.squeeze(x,axis=(2,)) only squeeze axis=2 new_list = np.squeeze(list_val) print('delonedim new_list:',new_list) return new_list # epoch | tp_ratio abs | lr | iou # 3k <0.3 0.05 0.4705 # 3k <0.3 0.01 0.6862 # 3k <0.3 0.005 0.6274 # 1k <0.3 0.01 0.6470 # 2k <0.3 0.01 0.6176 # 3k <0.3 0.01 0.6862 0.5882 0.6470 6960 # 4k <0.3 0.01 0.5784 # 5k <0.3 0.01 0.6176 # 3k <0.5 0.01 0.8235 0.8431 def compute_tp_ratio(pred,label): tp = 0 count = len(pred) for i in range(count): if abs(pred[i]-label[i]) < CFG.TRAIN.THRESHHOLD: tp+=1 ratio_tp = tp/count log.info('compute_tp_ratio count:{:},tp:{:},ratio_tp:{:}'.format(count,tp,ratio_tp)) return ratio_tp #accuracy for classifier def compute_accuracy(pred,label): ret = accuracy_score(pred,label) return ret
./utils
''' !/usr/bin/env python3 -*- coding: utf-8 -*- filename:utility.py author:jim.chen create date:9/19/2019 ''' import os def ispathexist(path): if not os.path.exist(path): return False else: return True def ispathexist(path): if not os.path.exist(path): return False else: return True
生成目录:
./checkpoint

./figure

./summary
--train_ac.py
''' !/usr/bin/env python3 -*- coding: utf-8 -*- filename:train_ac.py author:jim.chen create date:9/16/2019 ''' import tensorflow as tf #tf.__version__ :1.14.0 import glog as log import numpy as np from config import config #from model.ac_s_cnn import ac_s_cnn from model.ac_n_cnn import ac_n_cnn from preprocessing import dataset from evaluation import evaluation CFG = config.cfg def dataset_input(): log.info('dataset_input') train_y = [] test_y = [] dataset_train = dataset.dataset(True) #print('main data dataset_train._x:\n',dataset_train._x) #print('main data dataset_train._y1:\n',dataset_train._y1) train_x = dataset_train._x len_y = len(dataset_train._y1) print('dataset_input dataset_train len_y:\n',len_y) for i in range(len_y): train_y.append([dataset_train._y1[i]]) dataset_test = dataset.dataset(False) #print('main data dataset_test._x:\n',dataset_test._x) #print('main data dataset_test._y1:\n',dataset_test._y1) test_x = dataset_test._x len_y = len(dataset_test._y1) print('dataset_input dataset_test len_y:\n',len_y) for i in range(len_y): test_y.append([dataset_test._y1[i]]) return train_x,train_y,test_x,test_y def build_model(input,ys): log.info('build_model') #model = ac_s_cnn() net = ac_n_cnn() pred = net.model(input) log.info('pred:{:}'.format(pred.shape)) ''' cross_entropy = -tf.reduce_mean(y_*tf.log(tf.clip_by_value(y,1e-10,1.0))) ''' cost = tf.reduce_mean(tf.reduce_sum(tf.square(ys-pred),reduction_indices=[1])) log.info('cost:{:}'.format(cost)) train_opt = tf.compat.v1.train.AdamOptimizer(CFG.TRAIN.LEARNING_RATE).minimize(cost) return cost,train_opt,pred def tf_summary(sess,cost): log.info('tf_summary') tf.compat.v1.summary.scalar('cost_:', cost) merge_summary = tf.compat.v1.summary.merge_all() train_writer = tf.compat.v1.summary.FileWriter(CFG.TRAIN.SUMMARY_DIR,sess.graph) return merge_summary,train_writer def save_model2pb(): def model_train(sess,merge_summary,train_writer,train_opt,cost,xs,ys,train_x,train_y): log.info('model_train') train_len_y = len(train_y) print('model_train train_len_y:\n',train_len_y) cost_epoch =[] saver = tf.compat.v1.train.Saver() #saver = tf.compat.v1.train.Saver(max_to_keep=4,keep_checkpoint_every_n_hours=2) #[w1,w2] for step in range(CFG.TRAIN.EPOCHS): start = (step*CFG.TRAIN.BATCH_SIZE)%train_len_y end = min(start+CFG.TRAIN.BATCH_SIZE,train_len_y) #cost_,train_summary,_ = sess.run([cost,merge_summary,train_opt],feed_dict={xs:train_x,ys:train_y}) cost_,train_summary,_ = sess.run([cost,merge_summary,train_opt],feed_dict={xs:train_x[start:end],ys:train_y[start:end]}) #cost_ = sess.run(cost,feed_dict={xs:train_x,ys:train_y}) train_writer.add_summary(train_summary,step) cost_epoch.append(cost_) cost_epoch_arr = np.array(cost_epoch) cost_mean = cost_epoch_arr.mean() if (step+1) % CFG.TRAIN.DISPLAY_STEP == 0: print(step+1,'cost:',cost_mean) if (step+1) % (CFG.TRAIN.DISPLAY_STEP*10) == 0: #checkpoint_ac-1000.index #checkpoint_ac-1000.meta #checkpoint_ac-1000.data-00000-of-00001 #checkpoint saver.save(sess,CFG.TRAIN.CKPT_DIR+'ac',global_step=step+1,write_meta_graph==False) cost_epoch =[] cost_epoch.append(cost_mean) del cost_epoch def model_test(sess,pred,xs,ys,test_x,test_y): log.info('model_test') pred_val = sess.run(pred,feed_dict={xs:test_x,ys:test_y}) for i in range(len(pred_val)): log.info('model_test pred_val:{:},label:{:}'.format(pred_val[i],test_y[i])) evaluation.plot_show_effect(test_y,pred_val) #evaluation.compute_tp_ratio(pred_val,dataset_test._y1) #return pred_val def main(): xs = tf.compat.v1.placeholder(tf.float32,[None,CFG.TRAIN.FEATURE_X_SIZE*CFG.TRAIN.FEATURE_Y_SIZE]) ys = tf.compat.v1.placeholder(tf.float32,[None,CFG.TRAIN.CLASSES_NUM]) #dataset input train_x,train_y,test_x,test_y = dataset_input() #input = tf.reshape(xs,[-1,CFG.TRAIN.FEATURE_X_SIZE,CFG.TRAIN.FEATURE_Y_SIZE,CFG.TRAIN.CLASSES_NUM]) input = tf.reshape(xs,[-1,CFG.TRAIN.FEATURE_X_SIZE,CFG.TRAIN.FEATURE_Y_SIZE,CFG.TRAIN.CLASSES_NUM]) log.info('input:{:}'.format(input)) #build net model cost,train_opt,pred = build_model(input,ys) sess = tf.compat.v1.Session() sess.run(tf.compat.v1.global_variables_initializer()) #save cost to show in tensorboard merge_summary,train_writer = tf_summary(sess,cost) #training model model_train(sess,merge_summary,train_writer,train_opt,cost,xs,ys,train_x,train_y) #test model model_test(sess,pred,xs,ys,test_x,test_y) if __name__ == '__main__': main()
--test_ac.py
''' !/usr/bin/env python3 -*- coding: utf-8 -*- filename:test_ac.py author:jim.chen create date:9/19/2019 ''' import tensorflow as tf #tf.__version__ :1.14.0 import glog as log import numpy as np from config import config #from model.ac_s_cnn import ac_s_cnn from model.ac_n_cnn import ac_n_cnn from preprocessing import dataset from evaluation import evaluation CFG = config.cfg def model_test(sess,pred,xs,ys,test_x,test_y): log.info('model_test') pred_val = sess.run(pred,feed_dict={xs:test_x,ys:test_y}) for i in range(len(pred_val)): log.info('model_test pred_val:{:},label:{:}'.format(pred_val[i],test_y[i])) evaluation.plot_show_effect(test_y,pred_val) #evaluation.compute_tp_ratio(pred_val,dataset_test._y1) #return pred_val def main(): xs = tf.compat.v1.placeholder(tf.float32,[None,CFG.TRAIN.FEATURE_X_SIZE*CFG.TRAIN.FEATURE_Y_SIZE]) ys = tf.compat.v1.placeholder(tf.float32,[None,CFG.TRAIN.CLASSES_NUM]) #dataset input train_x,train_y,test_x,test_y = dataset_input() input = tf.reshape(xs,[-1,CFG.TRAIN.FEATURE_X_SIZE,CFG.TRAIN.FEATURE_Y_SIZE,CFG.TRAIN.CLASSES_NUM]) log.info('input:{:}'.format(input)) sess = tf.compat.v1.Session() sess.run(tf.compat.v1.global_variables_initializer()) #checkpoint_ac-1000.index #checkpoint_ac-1000.meta #checkpoint_ac-1000.data-00000-of-00001 #checkpoint saver = tf.compat.v1.train.import_meta_graph(CFG.TRAIN.CKPT_DIR+'ac'+str(CFG.TRAIN.EPOCHS)) saver.restore(sess,tf.train.latest_checkpoint('./')) #test model model_test(sess,pred,xs,ys,test_x,test_y) if __name__ == '__main__': main()
3、模型训练:
在config中配置好超参数,然后,运行命令:
python train_ac.py
如果没有报错,就会开始训练。。。
(未完待续)
上一篇:数据准备与预处理
使用Tensorflow搭建回归预测模型之二:数据准备与预处理
下一篇:模型测试与评估
(待更新)