最近想深入学习SQL,在网上搜索到一些SQL 优化的资料要么是张冠李戴,Oracle 优化的资料硬是弄成啦MS SQL 优化的资料,而且被很多人转载,收藏,有些要么有些含糊不清,好像是那么回事,也没经过验证,实践出真知!下面是我对SELECT COUNT(*), SELECT COUNT(1),SELECT COUNT (0), SELECT COUNT(Field)等孰优孰劣的测试结果,如果测试方法有什么不足,也希望大家给点建议。
首先我们来看看测试的机器、以及开发环境吧:双核处理器 T6670 2G DDR2的内存 数据版本如下图所示:

然后建一个简单的测试表
CREATE TABLE Employee
(
[EmployeeID] INT IDENTITY(1,1), --雇员ID
[EmployeeName] NVARCHAR(20) , --雇员姓名
[SEX] BIT , --性别
[Department] NVARCHAR(20) , --部门
CONSTRAINT [PK_Employee_ID_Name] PRIMARY KEY (EmployeeID, EmployeeName)
)
--插入一百万数据
DECLARE @Index INT;
SET @Index = 1;
WHILE @Index < 1000000
BEGIN
INSERT INTO Employee
VALUES('Employee' + STR(@Index), '0', '技术部门');
SET @Index = @Index + 1;
END
--建立非聚集索引
CREATE INDEX IDX_Employee_Department ON Employee([Department]);
好,到目前为止我们已经把测试用的表、数据都弄好啦,接下来我们来看看执行一次SELECT COUNT 的使用时间
- DBCC DROPCLEANBUFFERS;
- DBCC FREEPROCCACHE;
- SET STATISTICS TIME ON;
- SELECT COUNT(0) FROM Employee
- SET STATISTICS TIME OFF;
我们会得到下面的输出结果
DBCC 执行完毕。如果DBCC 输出了错误信息,请与系统管理员联系。
DBCC 执行完毕。如果DBCC 输出了错误信息,请与系统管理员联系。
SQL Server 执行时间:
CPU 时间= 219 毫秒,占用时间= 1033 毫秒。
接下来我们来看看各种Count的实际执行计划,截图如下
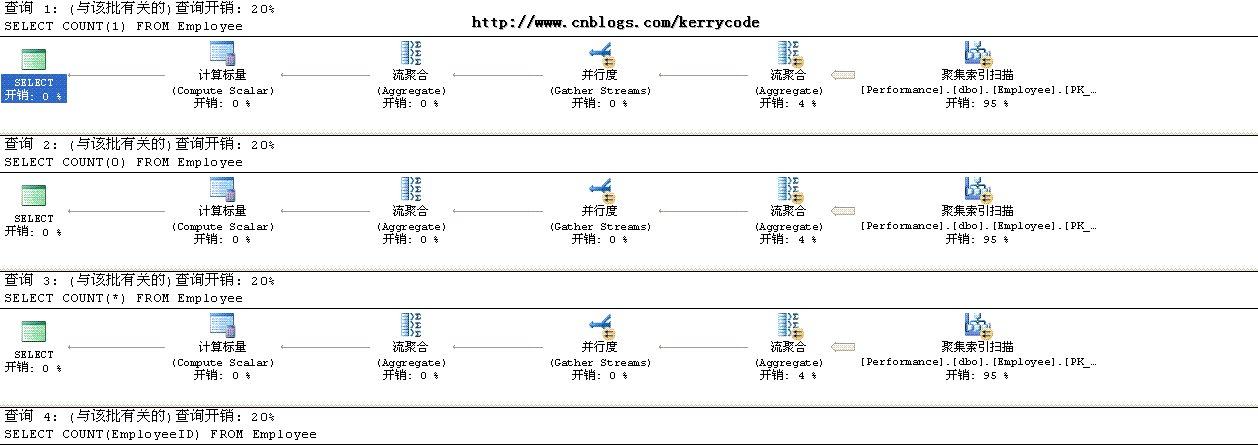
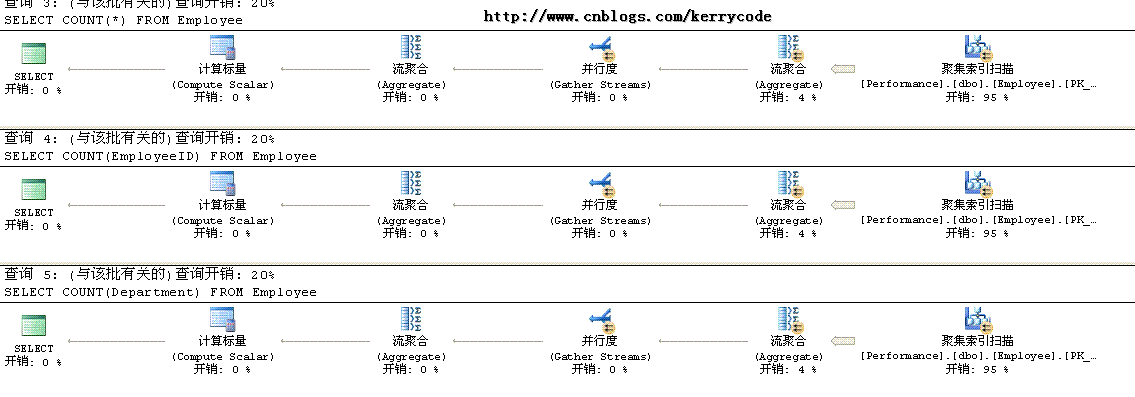
我很纳闷为什么执行计划都是一样的,希望有高手能解答。
接下来,那么我们把上面的脚本执行10次,把每次得到的数据记录下来,然后我们依次用
SELECT COUNT(1) FROM Employee、 SELECT COUNT(*) FROM Employee
等替换SELECT COUNT(0) FROM Employee 脚本,如下所示
DBCC DROPCLEANBUFFERS;
DBCC FREEPROCCACHE;
SET STATISTICS TIME ON;
SELECT COUNT(1) FROM Employee
SET STATISTICS TIME OFF;
依葫芦画瓢每段脚本执行10次,最后我们求得到的结果的平均值,为了形象显示,我用Excel把数据显示如下:
SELECT COUNT(1) FROM Employee
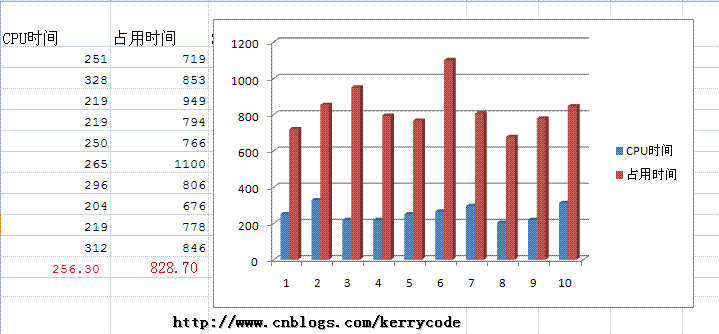
SELECT COUNT(0) FROM Employee

SELECT COUNT(*) FROM Employee
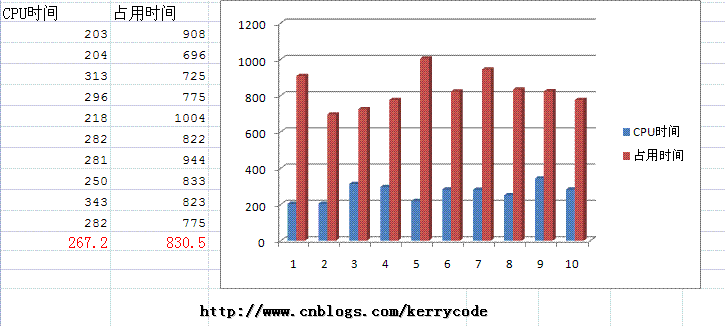
SELECT COUNT(EmployeeName) FROM Employee
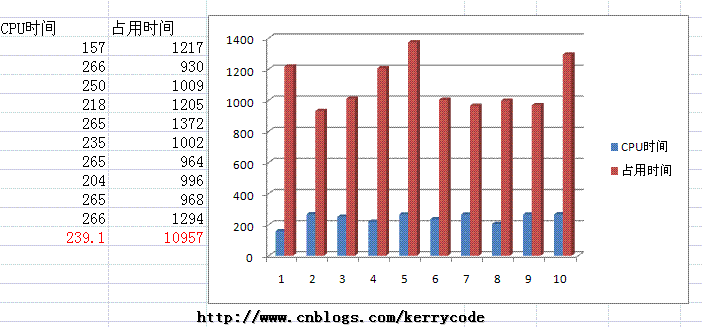
从实验结果来看,执行快慢的顺序为: COUNT(EmployeeName) > COUNT(0) ~= COUNT(1) > COUNT(*);从实验结果来看,我们至少验证了 COUNT(0) ~= COUNT(1) > COUNT(*)的结论,网上有篇帖子《SQL Server 索引结构及其使用》篇所下的结论count(*)不比count(字段)慢 显然是不严谨的,他只做了一次实验,而我们这里是10次结果的平均值。那么现在问题来了,为什么COUNT(EmployeeName)要快于COUNT(0) >= COUNT(1),它如果不是主键、字段没有索引呢?网上不是有些资料显示COUNT(1)效率最高,速度最快吗? 我们10次得到平结值有没有误差呢?抽样能否反映事实呢?下面我用这个方法来大量获得语句执行时间,然后求平均值,(我觉得这方法应该是可以反映实际CPU时间的)如果有不妥的地方,也希望大家指正。 创建下面一个表
CREATE TABLE ExcuteTime
(
[Type] VARCHAR(10), --不同COUNT类型
[CpuTime] FLOAT --语句执行的毫秒
)
--得到COUNT(1)100次的执行时间
DECLARE @BeginTime DATETIME;
DECLARE @Num INT;
SET @Num = 1;
WHILE @Num <= 100
BEGIN
SET @BeginTime = GETDATE();
SELECT COUNT(1) FROM Employee;
INSERT INTO ExcuteTime
VALUES('Count(1)', DATEDIFF(ms, @BeginTime,GETDATE()));
SET @Num = @Num + 1;
END
GO
然后也依次得到其它几种SQl 的执行时间,另外我们也把COUNT(Department)得数据加入进来,下面是我得到的实验结果的平均值
| COUNT(1) | COUNT(0) | COUNT(*) | COUNT(EmployeeName) | COUNT(Department) |
| 100.09 | 99.27 | 100.28 | 65.95 | 134.13 |
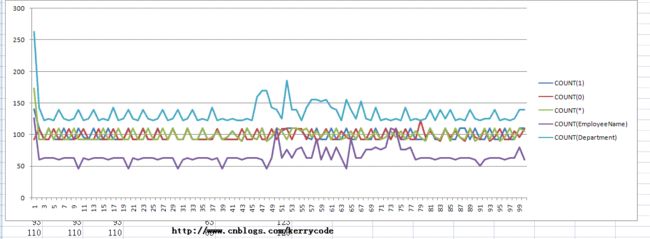
数据显示也与上面的测试结果相一致,虽然得到了这些结果,由于统计偏差缘故,COUNT(0)比 COUNT(1) 稍稍快些,这个是完全可以忽略,因为我统计的次数比小,很容易造成偏差,COUNT(*) 接近于COUNT(1),估计是由于数据缓存缘故,其实我们从实验结果可以看出统计数据的速度: 对索引字段统计要快于COUNT(1),原因是COUNT(1)是要走全表扫描,而COUNT(1) 快于COUNT(*) ,是因为COUNT(*)走全表扫描的开销要大于COUNT(1), 至于统计非索引字段COUNT(Department),比较偏大的,则让我有点纳闷,估计是统计偏差缘故。