再次附上我的github https://github.com/BudSpore
该文章由全栈工程师,开源博主韩大师推荐。
本系列文章都有点长,主要讲解AndroidUI显示的大致流程,并结合项目对视图,流畅度进行性能优化,最后会合成一个大的项目,认真读完,您一定有所收获。

Android系统在2.3只支持软件加速,后来在4.x,5.x就支持了硬件加速,OpenGL加速,Android视图显示整体流程是先绘制(CPU的工作)再渲染(GPU的工作),本篇文章讲CPU剩下的工作和GPU做的事情,实现代码都在native层,代码极其复杂,该文章我只聊思想,以后有时间再去分析~
我们对整体渲染流程来了解一下
一、整体渲染流程
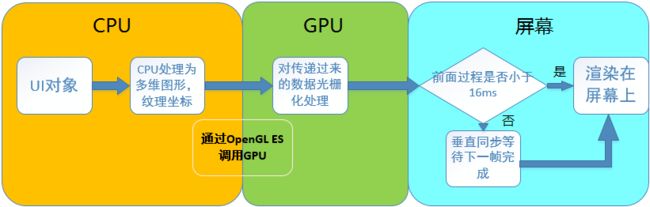
CPU负责把UI组件计算成Polygons,Texture纹理,然后交给GPU进行栅格化渲染。每次从CPU转移到GPU很麻烦,可是OpenGL ES可以把那些需要渲染的纹理保存在GPU Memory里面,在下次需要渲染的时候直接从中取出进行操作。所以如果你更新了GPU保存住的纹理内容,那么之前保存的状态就会丢失。
我们先对相关概念进行讲解,然后讲解Android渲染Surface的过程。
Surface
Surface位于Native层,我们在屏幕上看到的每一个window(如对话框、全屏的activity、状态栏)都有唯一一个自己的surface,注意TextView,ImageView等视图控件共用的一个surface,而surfaceView使用的单独的surface,应用使用Canvas或OpenGL在上面作画, 画完以后,SurfaceFlinger会将各个应用窗口的Surface进行合成,根据各个surface在Z轴上的顺序(Z-order)混合,输出到FrameBuffer中,将它们渲染到最终的显示屏上。每个Surface都是双缓冲,它有一个backBuffer和一个frontBuffer,UI先在Back Buffer中绘制,然后再和Front Buffer交换,渲染到屏幕上。(Surface类使用的图形缓冲区一般是在匿名共享内存中分配)
Surface创建Canvas对象,View在Canvas绘制完以后,再把内容画到Surface上。最顶层的View容器(都是DecorView,它包含了View树所有节点)的Canvas的数据信息会转换到一个Surface上。Surface是纵深排序(Z-ordered)的,它总在自己所在窗口的后面实屏幕上。
SurfaceHolder是Surface的监听器,通过回调方addCallback(SurfaceHolder.Callback callback )监听Surface的创建,通过获取Surface中的Canvas对象,并锁定之。所得到的Canvas对象 ,Canvas会遍历传递给每一个view,让每个view绘制自己的UI部分,传递给Surface,Surface中的数据完成后,释放同步锁,并提交改变Surface的状态及图像,将刚刚绘制好的缓冲区交换到前台,然后让Surface Flinger利用该缓冲区的数据渲染在屏幕上。Callback 中的surfaceCreated 和surfaceDestroyed 就成了绘图处理代码的边界。
(同步锁机制是为了在绘制的过程中,Surface中的数据不会被改变。lockCanvas是为了防止同一时刻多个线程对同一canvas写入)
SurfaceFlinger
SurfaceFlinger位于Native层,作者觉得这个类的功能极其强大,可以说是Android渲染体系的核心,SurfaceFlinger服务启动时,我们要接触三大线程,分别是Binder线程,UI渲染线程,控制台事件监控线程。SurfaceFlinger服务的作用就是被Android应用程序调用,把绘制(测量,布局,绘制)后的窗口(Surface)渲染到手机屏幕上,它管理Android系统的帧缓冲区(手机屏幕被抽象成了Frame Buffer),Android把UI绘制在帧缓冲区上面。SurfaceFlinger服务在渲染Android应用程序窗口时,首先会将它们的图形缓冲区合成到自己的图形缓冲区来,然后再渲染到硬件帧缓冲区上去,这些都在UI渲染线程执行。
有人会有疑问,UI绕过SurfaceFlinger直接渲染到屏幕上不可以吗,这样确实效率提高了,可是那么多App,如果都这样的渲染,可能前一个App的内容会被其他的App内容覆盖掉。
(实际上就是两个线程,一个渲染线程,一个UI更新线程,当应用正在一个缓冲区中绘制自己下一个UI状态时,Surface Flinger可以将另一个缓冲区中的数据合成显示到屏幕上,而不用等待应用绘制完成。)
Android应用程序窗口使用的图形缓冲区是在匿名共享内存中分配,而SurfaceFlinger服务使用的图形缓冲区是在硬件帧缓冲区上分配。
SurfaceFlinger三个线程的关系
Binder线程池用来让Android应用程序进程与SurfaceFlinger服务进行Binder进程间通信的,有一部分通信所执行的操作就是让UI渲染线程更新系统的UI。控制台事件监控线程是为了轮询监控屏幕(硬件帧缓冲区)的睡眠/唤醒状态切换事件的。一旦硬件帧缓冲区要进入睡眠或者唤醒状态,控制台事件监控线程都需要通知UI渲染线程,以便UI渲染线程可以执行关闭或者启动显示屏的操作,下面我们会接触到这些。
帧
我们看到的动画效果,其实是由很多个图片快速、连续显示造成的,每一幅图片就是一帧
FPS:每秒渲染了多少帧,Android屏幕刷新列率为60Hz,相应的,FPS应该也要达到60, 小了会卡顿,大了会画面撕裂,SurfaceFlinger把z轴不同顺序的Surface合成一张图,就是一帧。
Hz:屏幕刷新频率
每秒要加载60帧,每一帧的渲染时间是 1000/60 = 16.67 (ms)≈16ms
我们看一看Android应用程序和SurfaceFlinger服务的交互框架
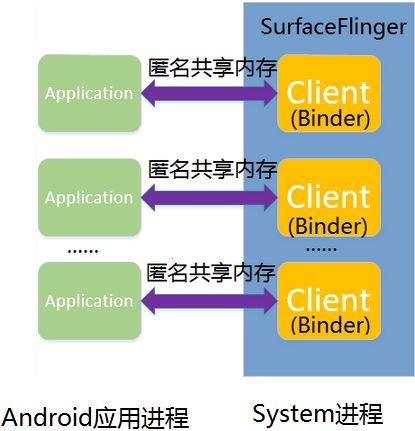
Android应用程序成功连接到SurfaceFlinger服务后,就可以获得一个对应的Client对象的Binder代理接口了(单例模式)。应用程序使用这些Binder代理接口就可以通知SurfaceFlinger服务来绘制自己的UI了(代理模式),SurfaceFlinger服务的UI渲染线程有一个消息队列。当消息队列为空时,SurfaceFlinger服务的UI渲染线程就会进入睡眠等待状态。一旦SurfaceFlinger服务的Binder线程接收到其它进程发送过来的渲染UI的请求时,它就会往SurfaceFlinger服务的UI渲染线程的消息队列中发送一个消息,以便可以将SurfaceFlinger服务的UI渲染线程唤醒起来执行渲染的操作。
AndroidUI元素的数据与SurfaceFlinger服务的传递是通过匿名共享内存机制实现,匿名共享内存用来保存设备显示屏的属性信息,例如,宽度、高度、密度和每秒多少帧等信息,匿名共享内存最终是被结构化为一个SharedClient对象来访问,(每一个Android应用程序通过Binder代理对应一个SharedClient对象),里面包含多个SharedBufferStack。
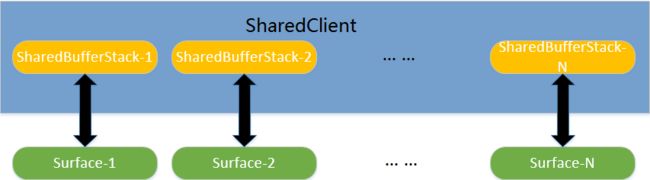
通过上图我们就能够理解了, 为什么每一个SharedClient里面包含的是多个SharedBufferStack而不是1个SharedBufferStack,因为每一个SharedBufferStack都对应1个Surface(窗口),这也是单例模式,1个SharedClient对应一个Android应用程序,而一个Android应用程序可能包含有多个窗口(Surface),一个Android应用程序可以包含多个Surface。
接下来我讲解一下SharedBufferStack.
SharedBufferStack

Android系统分别使用SharedBufferClient和SharedBufferServer来描述SharedBufferStack,其中,SharedBufferClient用来管理空闲缓冲区列表,而SharedBufferServer用来在SurfaceFlinger服务这一侧访问SharedBufferStack的排队缓冲区列表(head~queue_head)。
图中Buffer1,Buffer2区域属于已用缓冲区,Buffer3,Buffer4属于空闲缓冲区列表(Buffer1-2共同组成待渲染队列),目前只使到了Buffer1 Buffer2 UI元数据缓冲区,因此,只有它们才有对应的图形缓冲区,而Buffer3,Bffer4I元数据缓冲区没有。指针queue_head指向排队缓冲区列表(待渲染队列)的尾部,从指针tail到head之间的Buffer即为空闲缓冲区表,从指针head到queue_head之间的Buffer即为已经使用了的缓冲区列表,已用缓冲区列表和空闲缓冲区列表是可以循环使用的,SurfaceFlinger服务缓制Buffer-1和Buffer-2的时候,就会找到与它们所对应的GraphicBuffer,这样就可以将对应的UI绘制出来了。
当Android应用程序需要更新一个Surface的时候,它就会找到与它所对应的SharedBufferStack,并且从它的空闲缓冲区列表的尾部取出一个空闲的Buffer,并为它编号,接下来Android应用程序就请求SurfaceFlinger服务为这个Buffer分配一个图形缓冲区GraphicBuffer并为它编号(比如韩文凯),然后再将这个图形缓冲区GraphicBuffer返回给Android应用程序。Android应用程序得到了SurfaceFlinger服务返回的图形缓冲区GraphicBuffer之后,就在里面写入UI数据。写完之后,就将与它所对应编号的空闲缓冲区,插入到对应的SharedBufferStack的已经使用了的缓冲区列表的头部去。这一步完成了之后,Android应用程序就通知SurfaceFlinger服务去绘制那些保存在已经使用了的缓冲区所描述的图形缓冲区GraphicBuffer了,当一个已经被使用了的Buffer被绘制了之后,它就重新变成一个空闲的Buffer了。
SharedBufferStack是在Android应用程序和SurfaceFlinger服务之间共享的
GraphicBuffer
GraphicBuffer它是一块指定大小、像素格式以及用用途的图形缓冲区~GraphicBuffer内部都包含有一块用来保存UI数据的缓冲区,而这个图形缓冲区由系统帧缓冲区(FrameBuffer)或者匿名共享内存分配。GraphicBuffer既可以作为一个Front Buffer,也可以作为一个Back Buffer,也就是所谓的双缓冲技术。
双缓冲技术
SurfaceFlinger服务是在Frame Buffer中分配GraphicBuffer的,而Android应用程序是从匿名共享内存中分配GraphicBuffer的,即SurfaceFlinger服务使用的是硬件上的双缓冲技术,而Android应用程序使用的是软件上的双缓冲技术。Android应用程序最终需要通过SurfaceFlinger服务来将它的GraphicBuffer的内容渲染到Frame Buffer中去。并且Android应用程序中的每一个Surface对应的是一系列GraphicBuffer,而不是只有一个GraphicBuffer。Surface 就是双缓冲技术中的第一层,Surface的混合操作是由SurfaceFlinger服务来做的。当Surface改变,GraphicBuffer也会改变。
双缓冲的工作原理是:先把需要呈现的所有元素都画在一张图上(第一层),再把这张图整个投放到屏幕上去(第二层)
双缓冲的优点如下:
防止频闪(记得很久以前写java坦克大战项目时,如果直接把页面元素投放到屏幕上,会非常的不连贯,造成人眼可识别的卡顿)
某一具体的帧在投放到屏幕上可见之前,是有一层缓冲的渲染时间,这个时间让 CPU和GPU能更好的协调工作。
OpenGL
OpenGL用来将要绘制的图形通过调用FramebufferNativeWindow类的函数(包含点密度,刷新频率等)渲染到帧缓冲区硬件设备中去,即显示在实际屏幕上.
DisplayList
Android需要把XML布局文件转换成GPU能够识别并绘制的对象。这个操作是在DisplayList的帮助下完成的。DisplayList持有所有将要交给GPU绘制到屏幕上的数据信息。
请注意:任何时候View中的绘制内容发生变化时,都会需要重新创建DisplayList,渲染DisplayList,更新到屏幕上等一系列操作。这个流程的表现性能取决于你的View的复杂程度,View的状态变化以及渲染管道的执行性能。举个例子,假设某个Button的大小需要增大到目前的两倍,在增大Button大小之前,需要通过父View重新计算并摆放其他子View的位置。修改View的大小会触发整个HierarcyView的重新计算大小的操作。如果是修改View的位置则会触发HierarchView重新计算其他View的位置。如果布局很复杂,这就会很容易导致严重的性能问题。
屏幕旋转原理
SurfaceFlinger类关联GraphicPlane类,在GraphicPlane里面有两个变换矩阵,分别是初始化旋转方向变换矩阵和实际旋转方向的变换矩阵,各自都由宽度,高度,旋转模式组成,首先二者相等,当屏幕旋转,实际旋转方向矩阵的旋转模式也会变化,实际旋转方向变换矩阵里面宽和高互换,匹配硬件帧缓冲区旋转方向,最后初始化矩阵和实际旋转矩阵相乘,得到全局变换矩阵,渲染UI的时候,任意点向量×全局变换矩阵就得到它的实际位置。
屏幕睡眠、唤醒原理
SurfaceFlinger类包含DisplayHardware成员,DisplayHardware类的父类会通过一个控制台事件监控线程来监控显示屏的唤醒/睡眠状态切换,线程运行起来轮询监控屏幕状态,这个线程有两种类型,分别对应屏幕的睡眠和唤醒状态,当硬件帧缓冲区的控制台被打开和关闭时,分别对应不同的线程类型,通过这种方式控制SurfaceFlinger访问屏幕,控制台事件监控线程发现硬件帧缓冲区即将要进入睡眠或者唤醒状态时,它就会往SurfaceFlinger服务的UI渲染线程的消息队列中发送一个消息,以便SurfaceFlinger服务的UI渲染线程可以执行冻结或者解冻显示屏的操作
概念讲完了,我们切入正题。
二、Surface渲染过程
Android应用程序渲染一个Surface的过程大致如下所示:
- 在SurfaceFlinger类里有一个GraphicPlane对象,GraphicPlane类内部聚合一个DisplayHardware对象,这个对象描述当前活动的显示屏,GraphicPlane首先设置显示屏的初始大小和方向,详情请看屏幕旋转原理,然后DisplayHardware初始化FramebufferNativeWindow对象,FramebufferNativeWindow类使用的图形缓冲区是直接在硬件帧缓冲区分配的,并且它可以直接将这些图形缓冲区渲染到硬件帧缓冲区中去,这样可以获得硬件帧缓冲区的点密度和刷新频率等信息,并再加载HAL层中的overlay模块,接着初始化EGL、OpenGL库,保存之前获得的帧缓冲区信息到EGLConfig里,然后再硬件帧缓冲区创建系统主绘图表面,这个表面用来合成和渲染所有Application的UI,获得主绘图表面的宽,高,点密度,颜色分量的大小等信息,再获得绘图contenxt,这样 DisplayHardware对象初始化完成,以上都是在SurfaceFlinger服务的UI渲染线程中创建的,紧接着,SurfaceFlinger类会把绘图表面和context设置为UI渲染线程的绘图表面和context,并获得空闲的数据缓冲区,硬件帧缓冲区初始化完毕。
- 从SharedBufferStack中出栈一个空闲的UI元数据缓冲区,(相对于SharedBufferClient来讲tail栈尾指针往前移一位,对于SharedBufferServer来讲,指针head向前移一步)减少空闲缓冲区列表的值;
- 请求SurfaceFlinger服务为这个数据缓冲区分配一个图形缓冲区(GraphicBuffer);
- OpenGL通过FramebufferNativeWindow类得到图形缓冲区,在图形缓冲区上面绘制填充好UI(当前正在操作的Surface的裁剪区域、纹理坐标,像素格式,旋转方向等信息)之后,OpenGL就会调用Surface,将前面得到的空闲UI元数据缓冲区添加到SharedBufferStack中的待渲染队列的尾部,来向一个UI元数据缓冲区堆栈的待渲染队列增加一个缓冲区,即指针queue_head右移一个位置(所有需要加入到这个待渲染队列的UI元数据缓冲都保存在queue_head的下一个位置上);
- 应用程序请求SurfaceFlinger服务渲染前面已经准备好了图形缓冲区的Surface;
- SurfaceFlinger服务从即将要渲染的Surface的SharedBufferStack的待渲染队列中找到待渲染的UI元数据缓冲区;
- SurfaceFlinger服务得到了待渲染的UI元数据缓冲区之后,接着再找到在前面第2步为它所分配的图形缓冲区,最后就可以将这些图形缓冲区合成在一起渲染到设备显示屏上去(帧缓冲区),最后我们就可以在设备显示屏上看到系统的UI了。
接下来我们讲解GPU和硬件帧缓冲区在上述渲染过程中所做的工作。
GPU职责
GPU的主要功能就是把CPU通过OpenGL传递过来的UI数据光栅化处理并对数据进行缓存。
光栅化将UI矢量数据转化为一像素点的像素图,显示到屏幕上,XML布局文件需要在CPU中首先转换为多边形或者纹理,然后再传递给GPU进行格栅化,这是一个耗时的操作,如图:

屏幕职责
根据整体渲染流程图我们对以下进行分析:
垂直同步VSYNC:让显卡的运算和显示器刷新率一致以稳定输出的画面质量。它告知GPU在载入新帧之前,要等待屏幕绘制完成前一帧。下面的三张图分别是GPU和硬件同步所发生的情况,Refresh Rate:屏幕一秒内刷新屏幕的次数,由硬件决定,例如60Hz.而Frame Rate:GPU一秒绘制操作的帧数,单位是30fps,正常情况过程图如下
如果帧渲染时间太快,可以防止FPS比屏幕刷新率高而导致的画面撕裂。
当GPU渲染速度过慢,就会导致如下情况,某些帧显示的画面内容就会与上一帧的画面相同
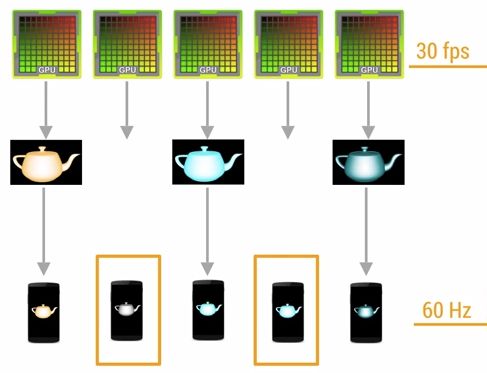
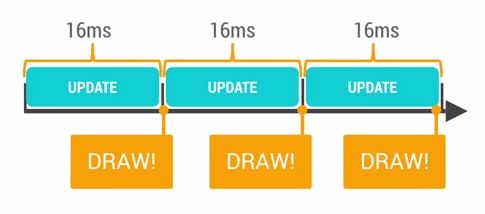
Android系统每隔16ms发出VSYNC信号,触发对UI进行渲染,如图:

当CPU和GPU处理时间都很慢,或因为其他的原因,如在主线程中干活太多,那么就会出现如下图这样的状况:
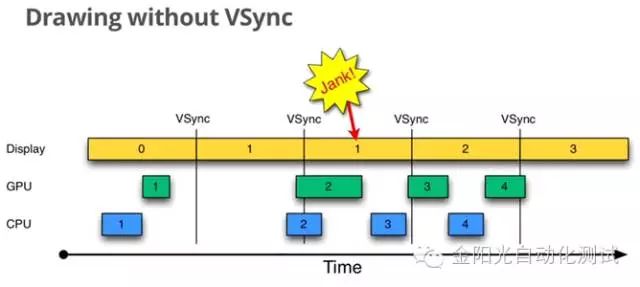
第2帧的计算还没有完成,所以只能继续显示第一帧,这就相当于你盯着一幅图看了32毫秒,这就是掉帧(jank),jank多了,人眼就能识别卡顿。
现在的三缓冲机制

正常情况下A显示时计算B,B显示时计算A,如果不正常情况下,会出现下面情况

在VSync下,在B渲染慢,A就只能在下下个脉冲开始计算,这样就导致一帧渲染延迟,每一帧都会渲染延迟,三缓冲用来解决这个问题。

在B慢了之后,A在下下次脉冲加载之前,趁着这个空闲的时间,计算C,CPU就一直不会闲着了,这样在脉冲到来时,可能就已经完成了B和C的计算,B,C都待投放到屏幕,多了个缓冲,解决了一帧慢,帧帧慢的问题。
但需要重点说明一下的是: 垂直同步机制是Android一直都有的,除了三缓冲,因为三缓冲会导致某一帧(比如C)在计算完很久之后才被选中投放到屏幕,即帧延后现象。而且选择C去这个过程本身也是一系列计算,所以三缓冲是选择性开启,当双缓冲造成的jank现象越来越严重,就开启去调节一下。
渲染的整体流程最好要限制在16ms内,如果大于16ms,会造成App的卡顿等性能问题,渲染造成的问题我们就要想办法进行优化,下一篇文章我将详细讲解Android视图的性能优化。
请UIT和广大读者的审阅。
以此篇文章感激即将21岁的我还在努力着。