第一章
主要内容:给特定网页发送GET请求,得到html数据然后简单地提取数据
- 小实验
from urllib.request import urlopen
html = urlopen("http://pythonscraping.com/pages/page1.html")
print(html.read())
在python2中有urllib和urllib2,在python3中urllib2变成了urllib,并且被分成几个子模块urllib.request,urllib.parse,urllib.error,urllib.robotparser等,urllib官方文档.
- BeautifulSoup简介
将HTML转化为代表XML结构的容易遍历的python对象。
from urllib.request import urlopen
from bs4 import BeautifulSoup
html = urlopen("http://www.pythonscraping.com/pages/page1.html")
bsObj = BeautifulSoup(html.read())
print(bsObj.h1)
网页的解构如下图所示:
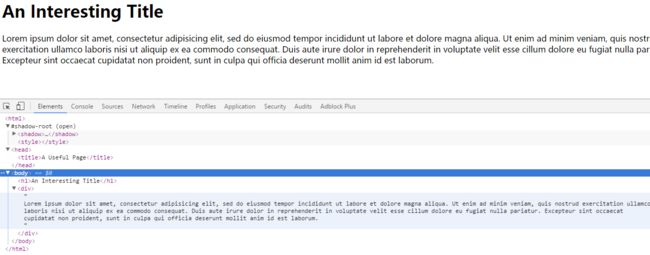
最终网页输出:
An Interesting Title
bs解析结果:
html → ......
— head → A Useful Page<title></head>
— title → <title>A Useful Page
— body → An Int...
Lorem ip...
— h1 → An Interesting Title
— div → Lorem Ipsum dolor...
虽然h1需要嵌套两层,但是我们还是可以用上诉语法找到h1(这里可能是递归查找,直到找到),我们也可以使用下面的语法找到h1
bsObj.html.body.h1
bsObj.body.h1
bsObj.html.h1
- 连接的健壮性
下面这句语句可能会出现两个错误(“404 Page Not Found,” “500 Internal Server Error”):
1.服务器找不到
2.这个页面找不到
html = urlopen("http://www.pythonscraping.com/pages/page1.html")
另外使用beautifulsoup的时候还会出现标签不存在的情况,因此需要对代码进行修改如下:
def getTitle(url):
try:
html = urlopen(url)
except HTTPError as e:
return None
try:
bsObj = BeautifulSoup(html.read())
title = bsObj.body.h1
except AttributeError as e:
return None
return title
def main():
title = getTitle("http://www.pythonscraping.com/pages/page1.html")
if title is None:
print("Title could not be found")
else:
print(title)
第二章-高级HTML解析
- 主要内容:解析HTML以得到我们想要的信息
以下代码我们可以提取出页面中class属性为green的标签,这里findAll的用法是:bsObj.findAll(tagName, tagAttributes)
getTitle("http://www.pythonscraping.com/pages/warandpeace.html")
def getTitle(url):
try:
html = urlopen(url)
except HTTPError as e:
return
try:
bsObj = BeautifulSoup(html)
nameList = bsObj.findAll("span", {"class": "green"})
for name in nameList:
print(name.get_text())
except AttributeError as e:
return
- find()和findAll()
findAll(tag, attributes, recursive=True, text, limit, keywords)
find(tag, attributes, recursive=True, text, keywords)
你可以这样:
.findAll({"h1","h2","h3","h4","h5","h6"})
你还可以这样:
.findAll("span", {"class":"green", "class":"red"})
参数recursive决定了递归的深度
text是用标签的内容来查找,假如我们想在文本当中找到包含'the prince'的内容的次数,用以下的代码:
nameList = bsObj.findAll(text="the prince")
print(len(nameList))
limit用来限制超找的个数,limit=1时,find()和findAll()是一样的。
keyword特定的属性,例子:
allText = bsObj.findAll(id="text")
print(allText[0].get_text())
下面两者是等价的
bsObj.findAll(id="text")
bsObj.findAll("", {"id":"text"})
个人随手练习-获取廖雪峰教程所有名称
-
转移树
有时我们需要根据标签的相对位置来得到其他的标签
像这个网站有大概如下的标签结构:

孩子与后代、兄弟姐妹、父母.....
孩子只有一层关系,孩子的孩子也是后代。正则表达式
|:一个或者零个
*:零个或者任意多个
+:至少出现一次
\:可选
[]:范围
():优先级
见P26
任意邮箱的正则表达式:[A-Za-z0-9._+]+@[A-Za-z]+.(com|org|edu|net)正则表达式和bs
怎么找出这些图片的链接地址,你可能会说,用findAll('img')啊!但是logo啊,其他的一些图片就进来了!!
image["src"]根据标签和属性得出属性的具体内容。
from urllib.request import urlopen
from bs4 import BeautifulSoup
from bs4 import re
def findPictureURI():
html = urlopen("http://www.pythonscraping.com/pages/page3.html")
bsObj = BeautifulSoup(html)
images = bsObj.findAll("img", {"src":re.compile("\.\.\/img\/gifts\/img.*\.jpg")})
for image in images:
print(image["src"])
返回:
../img/gifts/img1.jpg
../img/gifts/img2.jpg
../img/gifts/img3.jpg
../img/gifts/img4.jpg
../img/gifts/img6.jpg
- Lambda表达式
看看下面的例子,bs运行我们使用一个lambda表达式,参数必须是tag,输出必须是布尔变量。这里可以用lambda表达式代替正则表达式,只要你开心
soup.findAll(lambda tag: len(tag.attrs) == 2)
可能会返回的结果:
第四章-开始“爬”
主要内容:开始解决一些实际问题——从一个名人wiki页面到另外一个wiki页面最少要多少次点击?我选择李嘉诚和周杰伦。
- 首先实现爬取某个wiki页面全部链接
官方实现:
# retrieves an arbitrary Wikipedia page and produces a list of links on that page
def getlinks(url):
html = urlopen(url)
bsobj = BeautifulSoup(html)
for link in bsobj.findAll('a'):
if 'href' in link.attrs:
print(link['href'])
我用lambda表达式实现另外一个版本,结果是一样的
# retrieves an arbitrary Wikipedia page and produces a list of links on that page
def getlinks(url):
html = urlopen(url)
bsobj = BeautifulSoup(html,'lxml')
for link in bsobj.findAll(lambda tag: tag.name =='a' and 'href' in tag.attrs):
print(link['href'])
结果出来发现了一些情况:
有些我们不想要的
//wikimediafoundation.org/wiki/Privacy_policy
//en.wikipedia.org/wiki/Wikipedia:Contact_us
作者发现有我们想要的都在有一个属性id=bodyContent的标签里面:
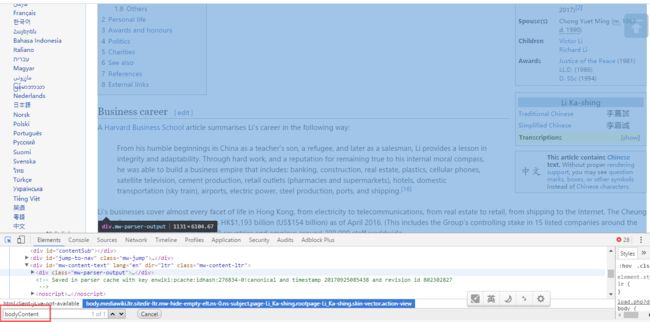
我们先加入这个限制
from urllib.request import urlopen
from bs4 import BeautifulSoup
import re
html = urlopen("http://en.wikipedia.org/wiki/Kevin_Bacon")
bsObj = BeautifulSoup(html)
for link in bsObj.find("div", {"id":"bodyContent"}).findAll("a",
href=re.compile("^(/wiki/)((?!:).)*$")):
if 'href' in link.attrs:
print(link.attrs['href'])
继续我们发现还有这些不要的链接,他们都没有/wiki/:
#cite_ref-1
#cite_ref-2
#cite_ref-KBE_3-0
#cite_ref-KBE_3-1
http://www.nndb.com/people/977/000161494/
https://www.forbes.com/profile/li-ka-shing/
http://www.london-gazette.co.uk/issues/55879/supplements/24
/wiki/Category:Businesspeople_from_Guangdong
/wiki/Category:Canadian_Imperial_Bank_of_Commerce_people
/wiki/Category:Cheung_Kong_Holdings
/wiki/Category:CK_Hutchison_Holdings
/wiki/Category:Commandeurs_of_the_L%C3%A9gion_d%27honneur
/wiki/Category:Hong_Kong_Affairs_Advisors
/wiki/Category:Hong_Kong_billionaires
/wiki/Category:Hong_Kong_BLDC_members
/wiki/Category:Hong_Kong_Buddhists
/wiki/Category:Hong_Kong_chairmen_of_corporations
/wiki/Category:Hong_Kong_emigrants_to_Canada
继续改进:1.没有:、2.要有/wiki/
^(/wiki/)((?!:).)*$表示一段随意字符+/wiki/+没有‘:’
# retrieves an arbitrary Wikipedia page and produces a list of links on that page
def getlinks(url):
html = urlopen(url)
bsobj = BeautifulSoup(html,'lxml')
content_in_body = bsobj.find('div',{'id':'bodyContent'})
for link in content_in_body.findAll('a',href=re.compile('^(/wiki/)((?!:).)*$')):
if 'href' in link.attrs:
print(link['href'])
这下干净了许多:
/wiki/Martin_Lee_Ka_Shing
/wiki/Chinese_name
/wiki/Chinese_surname
/wiki/Li_(surname_%E6%9D%8E)
/wiki/The_Honourable
/wiki/Grand_Bauhinia_Medal
/wiki/Order_of_the_British_Empire
/wiki/Justice_of_the_Peace
/wiki/Chaozhou
/wiki/Guangdong
/wiki/Republic_of_China_(1912%E2%80%931949)
/wiki/High_school_dropout
/wiki/CK_Hutchison_Holdings
/wiki/Cheung_Kong_Property_Holdings
/wiki/Li_Ka_Shing_Foundation
/wiki/US$
/wiki/Victor_Li_Tzar-kuoi
/wiki/Richard_Li
/wiki/Justice_of_the_Peace
/wiki/Doctor_of_law
/wiki/Doctor_of_Social_Science
/wiki/Traditional_Chinese_characters
/wiki/Simplified_Chinese_characters
/wiki/Standard_Chinese
/wiki/Hanyu_Pinyin
/wiki/Wu_Chinese
/wiki/Hakka_Chinese
/wiki/Guangdong_Romanization#Hakka
/wiki/Cantonese
/wiki/Jyutping
/wiki/Southern_Min
/wiki/Teochew_dialect
/wiki/Guangdong_Romanization#Teochew
/wiki/Chinese_language
/wiki/Specials_(Unicode_block)#Replacement_character
/wiki/Chinese_characters
/wiki/Grand_Bauhinia_Medal
/wiki/Order_of_the_British_Empire
/wiki/Justice_of_the_Peace
/wiki/Chaozhou
/wiki/Hong_Kong
/wiki/Chairman
/wiki/CK_Hutchison_Holdings
/wiki/Cheung_Kong_Holdings
/wiki/Hong_Kong_Stock_Exchange
/wiki/Forbes_family
/wiki/No_frills
/wiki/Seiko
/wiki/Deep_Water_Bay
/wiki/Hong_Kong_Island
/wiki/Superman
/wiki/Chaozhou
/wiki/Teochew_people
/wiki/Hong_Kong_Stock_Exchange
/wiki/Hongkong_Electric_Company
/wiki/Harvard_Business_School
/wiki/Artificial_flower
/wiki/Hong_Kong_1967_Leftist_Riots
/wiki/Cheung_Kong
/wiki/Yangtze_River
/wiki/Cheung_Kong_Holdings
/wiki/Hong_Kong_Stock_Exchange
/wiki/Hongkong_Land
/wiki/Cheung_Kong
/wiki/British_overseas_territory
/wiki/Bermuda
/wiki/HSBC
/wiki/Hutchison_Whampoa
/wiki/Cheung_Kong_Holdings
/wiki/Port_of_Hong_Kong
/wiki/Deltaport
/wiki/People%27s_Republic_of_China
/wiki/United_Kingdom
/wiki/Rotterdam
/wiki/Panama
/wiki/Bahamas
/wiki/Developing_countries
/wiki/A.S._Watson_Group
/wiki/Superdrug
/wiki/Kruidvat
/wiki/Watson%27s
/wiki/CK_Hutchison_Holdings
/wiki/Orange_SA
/wiki/Hutchison_Telecommunications
/wiki/Hutchison_Essar
/wiki/Vodafone
/wiki/Horizons_Ventures
/wiki/DoubleTwist
/wiki/Li_Ka_Shing_Foundation
/wiki/Facebook
/wiki/Spotify
/wiki/Siri_Inc.
/wiki/Nick_D%27Aloisio
/wiki/Bitcoin
/wiki/Australian_Tax_Office
/wiki/Cheung_Kong_Holdings
/wiki/SA_Power_Networks
/wiki/Cheung_Kong_Property_Holdings
/wiki/CK_Hutchison_Holdings
/wiki/Canadian_Imperial_Bank_of_Commerce
/wiki/Husky_Energy
/wiki/Alberta
/wiki/Canadian_dollar
/wiki/Canadian_Imperial_Bank_of_Commerce
/wiki/Li_Ka_Shing_Foundation
/wiki/Toronto
/wiki/The_Hongkong_and_Shanghai_Banking_Corporation
/wiki/HSBC_Holdings
/wiki/Victor_Li_Tzar-kuoi
/wiki/Richard_Li
/wiki/CK_Hutchison_Holdings
/wiki/PCCW
/wiki/Citizen_Watch_Co.
/wiki/Seiko
/wiki/Raymond_Chow
/wiki/Grand_Bauhinia_Medal
/wiki/Order_of_the_British_Empire
/wiki/L%C3%A9gion_d%27honneur
/wiki/Hutchison_Whampoa
/wiki/Henry_Tang
/wiki/Hong_Kong_Chief_Executive_election,_2012
/wiki/2014_Hong_Kong_protests
/wiki/2014%E2%80%9315_Hong_Kong_electoral_reform
/wiki/Shantou_University
/wiki/Chaozhou
/wiki/Guangdong_Technion-Israel_Institute_of_Technology
/wiki/Technion_%E2%80%93_Israel_Institute_of_Technology
/wiki/Shantou_University
/wiki/Hong_Kong_Polytechnic_University
/wiki/Cambridge
/wiki/Cancer_Research_UK
/wiki/Oncology
/wiki/Singapore_Management_University
/wiki/2004_Indian_Ocean_earthquake_and_tsunami
/wiki/University_of_Hong_Kong
/wiki/Li_Ka_Shing_Faculty_of_Medicine
/wiki/Kwok_Ka_Ki
/wiki/University_of_California,_Berkeley
/wiki/University_of_California,_Berkeley
/wiki/University_of_California,_San_Francisco
/wiki/University_of_California,_Berkeley
/wiki/Jennifer_Doudna
/wiki/Stanford_University
/wiki/Stanford_University_School_of_Medicine
/wiki/National_University_of_Singapore
/wiki/St._Michael%27s_Hospital,_Toronto
/wiki/University_of_Alberta
/wiki/2008_Sichuan_earthquake
/wiki/McGill_University
/wiki/Shantou_University
/wiki/University_of_California,_San_Francisco
/wiki/Tsz_Shan_Monastery
/wiki/The_Hongs
/wiki/List_of_Hong_Kong_people_by_net_worth
/wiki/Li%27s_field
/wiki/Wayback_Machine
/wiki/Techcrunch
/wiki/Horizons_Ventures
/wiki/Techcrunch
/wiki/Wayback_Machine
/wiki/Wayback_Machine
/wiki/UTC
/wiki/Wayback_Machine
/wiki/Cheung_Kong_Holdings
/wiki/Jao_Tsung-I
/wiki/Hong_Kong_order_of_precedence
/wiki/Yeung_Kwong
/wiki/Virtual_International_Authority_File
/wiki/Library_of_Congress_Control_Number
/wiki/Integrated_Authority_File
/wiki/Syst%C3%A8me_universitaire_de_documentation
Process finished with exit code 0
最终代码:有点粗糙,随机的走,后面会继续讲!!
def getlinks(url):
html = urlopen("http://en.wikipedia.org" + url)
bsobj = BeautifulSoup(html,'lxml')
content_in_body = bsobj.find('div',{'id':'bodyContent'})
return content_in_body.findAll('a',href=re.compile('^(/wiki/)((?!:).)*$'))
def main():
random.seed(datetime.datetime.now())
links = getlinks('/wiki/Li_Ka-shing')
while len(links) > 0:
newArticle = links[random.randint(0, len(links) - 1)].attrs["href"]
print(newArticle)
links = getlinks(newArticle)
爬下整个网站的好处:
1、可以生成一个网站地图
2、收集数据
- 网站去重
下面是爬取wiki的全部网页,首先从主页开始,找到一个页面,然后递归地调用,就像DFS。
pages = set()
def getLinks(pageUrl):
global pages
html = urlopen("http://en.wikipedia.org"+pageUrl)
bsObj = BeautifulSoup(html)
for link in bsObj.findAll("a", href=re.compile("^(/wiki/)")):
if 'href' in link.attrs:
if link.attrs['href'] not in pages:
#We have encountered a new page
newPage = link.attrs['href']
print(newPage)
pages.add(newPage)
getLinks(newPage)
getLinks("")
- 观察wiki页面的模式
1.h1标签下的内容就是标题
2.第一段在标签div,属性id=mw-content-text下面
3.编辑按钮在 - 下面
基于以上观察,爬取wiki的一些重要内容:
from urllib.request import urlopen
from bs4 import BeautifulSoup
import re
pages = set()
def getLinks(pageUrl):
global pages
html = urlopen("http://en.wikipedia.org"+pageUrl)
bsObj = BeautifulSoup(html)
try:
print(bsObj.h1.get_text())
print(bsObj.find(id ="mw-content-text").findAll("p")[0])
print(bsObj.find(id="ca-edit").find("span").find("a").attrs['href'])
except AttributeError:
print("This page is missing something! No worries though!")
for link in bsObj.findAll("a", href=re.compile("^(/wiki/)")):
if 'href' in link.attrs:
if link.attrs['href'] not in pages:
#We have encountered a new page
newPage = link.attrs['href']
print("----------------\n"+newPage)
pages.add(newPage)
getLinks(newPage)
getLinks("")
问题:
我们需要将这些数据放到数据库——第五章解决
这段代码实际还会跑到wiki以外的网站去一些问题:
1.爬虫要收集什么数据?是一些特殊网站的数据,还是全部网站的数据
2.DFS还是BFS
3.在哪些情况下我不会爬某个网站?非英文网站?
4.要遵守一些规则吗?还有几个程序是爬外链的,见这里
简短无力地介绍了Scrapy,作者建议大家去看官方的文档