背景
基于公司目前积极拓展新业务以及多数据中心的需求,老数据中心各种不稳定的情况也面临着逐渐被新数据中心淘汰。而当新的数据中心主要以秉持简化IT管理、节约成本、提高资源利用率和快速交付等原则理念时,建设一套公司自己的私有云平台显得具有重大价值。过去几年中OpenStack作为开源界增长最迅速且最亮眼的项目,得益于各大IT巨头和运营商的支持,目前OpenStack事实上已经成为业界建设私有云的标准。也鉴于如此,OpenStack每年吸引了大量开发者和厂商将自己产品融入到其架构中来,其中有名如思科、华为等大厂将自己设备驱动集成到代码,也有99cloud这种专业做OpenStack解决方案的厂商。正因如此,每年OpenStack Summit峰会总有让人眼前一亮的项目,同时每年OpenStack发布两个Release版本也快速迭代着目前市场急需解决的问题。所以当我们在考虑建设私有云项目时,选择OpenStack不失为一个从技术、成本和管理角度上的最优抉择。
OpenStack现状
关于OpenStack,我们已经在亦庄的数据中心推广了近半年时间,就现在运行状态来看平台已经非常稳定。目前我们OpenStack采用了Mutil-Region方案,整合了亦庄和兆维两个数据中心的物理机资源。其中亦庄控制节点作为主要的授权认证中心,为两个机房的OpenStack环境提供支持,用户在创建虚拟机时自由的选择其数据中心。
目前OpenStack项目所使用的物理机总共占有87台(亦庄60台,兆维17台),其上共计运行726台虚拟机(亦庄537台,兆维189台)。就现状来看虚拟机平时的资产比已经约占总资产的40%。而物理机的总体利用率尚且还有提升空间。这说明在虚拟化这块我们仍然还有很多地方做得不够好。
不足之处
- 资源利用率
服务器内存瓶颈,目前亦庄和兆维的计算节点为节约成本考虑,开启内核KSM特性。操作系统需要消耗大量计算资源用于计算内存的共享页面。
同时由于计算节点存在内存超售情况,虚拟机存在OOM的风险,而不得不关闭宿主机资源调度服务。也正因如此,前面说到的物理机整体利用率尚且还有提升空间就是说的这里的内存瓶颈。目前从上线半年多的监控来看,在计算节点CPU和内存超售的情况下,CPU的利用率平均idle也只是90%左右。如下图说示:

所以,目前内存空间已经成为制约资源利用率的一个关键因素。而现在市场上服务器的内存价格正不断降低,能有效的扩展计算节点内存,将为能现在的服务器资源利用率提高一定空间。
- 管理成本
现阶段我们的OpenStack环境为了方便管理,账号是下发到每一个运维手里。运维可以自行在Horizon界面上自助开通虚拟机资源,而每个运维的配额则由管理员分配与回收。
这种方式虽然解放了由管理员集中开通的麻烦,但是由于权限下放,所开通的虚拟机资源便不可控。目前虚拟机的规格就多达14种,更有甚者的是开通了大规格的虚拟机,至于合不合理,云平台不好说。
鉴于如此,我们计划将OpenStack接入资产系统,利用资产现有的账号系统,统一调度账号的虚拟资源。而OpenStack资源对资产全开,虚拟机调度由OenStack自身完成,用户配额以及权限管理由资产系统完成。
- 集群和可扩展性
由于亦庄机房在设计之初只是用来承担兆维机房虚拟机迁移和测试环境项目,所以在集群方面并没有引入高可用和扩展方案。目前控制节点仍然是一个单点在运行。由于OpenStack是无状态的服务,从某种角度上说是数据库数据在,OpenStack就在。所以现在的控制节点只做了数据库的数据备份。而自从兆维机房的OpenStack环境的加入,亦庄的控制节点的作用就显得格外重要。随着计算节点的不断扩容,控制节点的负载逐渐开始上升,可扩展的特性也开始局限。
目前存在的风险是即便数据做了备份,一旦控制节点宕机恢复起来仍然需要相当一段时间。
在新机房建设方案里,OpenStack集群将被重新设计,一方面会保证没有单点故障,另一方也会为OpenStack在大规模环境下重新设计框架。
- 硬件成本
磁盘方面
虚拟机采用本地盘文件模拟硬盘方式提供存储,在某些时刻存在单一虚拟机占用操作系统大量读写IO,造成这段时间宿主机上出现资源抢占的问题。目前还无法做到良好的解决方案。
虚拟机数据卷通过OpenStack集群内的每一台计算节点提供自己的/dev/sdb设备做数据存储。通过
lvm + iscsi挂载给虚拟机使用。所以集群内每一台计算节点都在为其他计算节点的虚拟机提供数据存储服务。一旦其中一台计算节点宕机,影响的不止本机上的虚拟机,还影响连接这台物理机上数据卷的其它虚拟机。
网络方面
计算节点上的虚拟机网络采用的Bond1方式保证虚拟机网络冗余,而管理网络和数据存储网络分别是单块网卡,对于网络的冗余性仍然无法保证。
新的设计方案会摒弃以前的数据卷的单点方案,将会采用Ceph系统集中提供数据服务。同时,网络方面,特别是网卡仍然还有提升空间。
- 网络管理
目前OpenStack仍然采用的是传统的二层Vlan解决方案,链路访问必须依赖三层交换机的路由机制。一方面局限了虚拟机的网络规划,另一方面也需要大量的人为操作配置来保证接入层的网络和OpenStack网络的适配。
目前基于Vxlan的SDN网络正在普及,而且主流的大部分接入层交换机支持流表策略,对于OpenStack来说,引入SDN/NFV对于网络的管理将提高一个层次。
新机房OpenStack建设方案
为了解决目前OpenStack的不足之处,以及考虑到以后容器化平台和SDN项目的的推进。目前对新机房的OpenStack进行了重新设计。对于OpenStack也采用最新的Release版本Ocata。相比Mitaka版本,Ocata此次更新带来了一些新的特性,也带来一个稳定的发行版,其中包括Keystone采用全新的v3框架,Fernet成为默认的Token Provider,相比v2版本,数据库的压力更小、Nova引入了全新的Cell v2设计、Cinder增强了对Ceph的支持等等。
本次新机房的建设的方案也是基于Ocata版本,其中方案主要涉及到以下项目:
集群高可用
网络规划
资源池规划
存储规划
Vxlan/SDN接入
集群高可用
OpenStack集群的高可用方案详情如下:

数据库集群
采用MariaDB + Galera组成三个Active节点,外部访问通过Haproxy的active + backend方式代理。平时主库为A,当A出现故障,则切换到B或C节点。

RabbitMQ集群
RabbitMQ采用原生Cluster集群,所有节点同步镜像队列。三台物理机,其中2个Mem节点主要提供服务,1个Disk节点用于持久化消息,客户端根据需求分别配置主从策略。

OpenStack集群
三台物理机分别部署OpenStack服务,共享数据库和消息队列,由前端haproxy轮训请求到后端处理。
前端代理
前端代理采用Haproxy + KeepAlived方式,代理数据库服务和OpenStack控制节点各服务,对外暴露VIP提供API访问。
网络规划
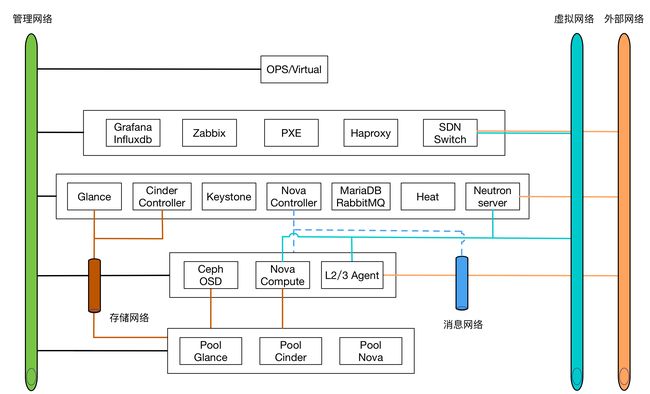
根据目前的网络规划,解释如下:
管理网络(必须):承担OpenStack各组件API调用,以及对外API暴露的网络。同时,装机的PXE、监控和负载均衡器所在的网络也会和管理网络互通。
消息网络(非必须): OpenStack组件内部的消息通信网络。之所以要和管理网络分离是因为考虑到后期对外的API网络和消息网络混用的安全风险。
虚拟网络(必须):主要为虚拟机、负载均衡器以及虚拟路由器等提供网络支持,同时与SDN交换机的网络打通。
外部网络(必须):承担虚拟机对外部实体网络的访问与互通,也会与SDN交换机打通。
存储网络(必须):承担Ceph系统的数据同步已经业务数据卷服务,同时承担部分测试环境虚拟机的系统盘业务。
对于服务器的网卡规划有如下推荐:
管理网卡: 一块1000Mbps网卡
消息网卡: 一块1000Mbps网卡
业务网卡: 两块1000Mbps网卡,做bond4或者bond6
外部网卡: 两块1000Mbps网卡,做bond4或者bond6
存储网卡: 两块1000Mbps网卡,一块客户端网卡,一块数据同步网卡
对于网卡的需求是相对的,我们总是在成本和高可用之间寻找平衡点。目前一台服务器默认是4块网卡,对于OpenStack来说会优先满足虚拟机网络的高可用,其它网络都可以相对混合部署。
资源池规划
对于OpenStack的扩展性,目前采用Nova的Cell V2版本设计。顶层由API负载维护全局的Cell节点关系映射表。而具体的调度则由scheduler服务选择合适cells创建虚拟机。
备注:目前Ocata只支持一个Cells,multi-cells将在下个发行版Pike中被支持,这里可以平滑的升级到新版本。
根据目前的设计,一个Cell空间可支撑80-120个计算节点。后期升级到Pike便可理论上支持1000+服务器。

存储规划
新机房的存储系统采用Ceph分布式存储系统,根据OpenStack集群规模,设计一个Cell环境一套本地Ceph环境。
根据设计图和服务器的硬盘现状,每个计算节点的两块硬盘分别承担两个OSD进程,每个OSD进程采用Cgroup做资源隔离,根据官方的建议每个OSD进程的资源为1C2G。而这个成本对计算节点来说是可以接受的。

Ceph集群主要提供三个存储池,pool glance、pool cinder和pool nova。
- pool glance 主要提供镜像存储
- pool cinder 主要提供集群的数据卷存储
- pool nova 主要提供一部分测试环境虚拟机的支撑
存储数据冗余3份,存储对象离散到集群大部分节点上,保证数据的安全性。
每个Cell的Ceph为独立的一套集群环境。pool glance的镜像会定时做镜像同步,而pool cinder和pool nova里面的数据相对独立,依赖OpenStack上层资源调度。每个Cell存储池里面的资源只对Cell内的节点负载。不允许出现跨资源池的调用Ceph资源。
Vxlan和SDN接入
vxlan
传统网络架构以三层为主,主要是以控制南北数据流量为主,由于数据中心虚拟机的大规模使用,虚拟机迁移的特点以东西流量为主,在迁移后需要其IP地址、MAC地址等参数保持不变,如此则要求业务网络是一个二层网络。但已有二层技术存在下面问题。
- 生成树(STP Spanning Tree Protocol)技术,部署和维护繁琐,网络规模不宜过大,限制了网络的扩展;
- 各厂家私有的IRF/vPC等网络虚拟化技术,虽然可以简化部署,但是对于网络的拓扑架构有严格要求,同时各厂家不支持互通,在网络的可扩展性上有所欠缺;
- 新出现的大规模二层网络技术TRILL/SPB/FabricPath等,虽然能支持二层网络的良好扩展,但对网络设备有特殊要求,网络中的设备需要软硬件升级才能支持此类新技术,带来部署成本的上升。
针对目前的问题,我们决定有必要采用overlay的方式来封装二层协议,并借助业界已经成熟的Vxlan来支撑私有云平台的网络模型。
而对于我们的需求,主要为私有云的私有vxlan网络与外部真实网络的打通问题,因此对于vxlan的混合部署是满足我们需要的。方案如下:

- 核心设备主要提供VXLAN 网关功能,支持VXLAN报文的封装与解封装,并根据内层报文的IP头部进行三层转发,支持跨VXLAN之间的转发,支持VXLAN和传统VLAN之间的互通。
- ovs主要提供虚拟化VXLAN 隧道封装功能,支撑VM接入Overlay网络,支持VXLAN报文的封装与解封装,支持跨VXLAN之间的转发。
- 物理接入网络设备主要提供VXLAN 隧道封装功能,支撑物理服务器接入Overlay网络,支持VXLAN报文的封装与解封装,并根据内层报文的MAC头部进行二层转发。
SDN
在Neutron中的SDN控制器(采用了OpenFlow协议),可以控制流量转发以实现不同虚拟路由器(DVR)的流量负载,通过匹配流表项的方式来实现数据包按照自定义的OpenFlow规则实现Qos功能,不同的应用业务,使用不同的流转发方式,Normal或Flow。
目前,已知的Neutron和SDN控制器集成现状,如下所示:
| 项目 | 描述 | 主导团队 |
|---|---|---|
| Networking-odl | Odl专注于SDN Controller方面 | 众多第三方网络提供商 |
| Networking-onos | Onos专注于sdn controller方面,ml2、ml3均实现集成 | 华为 |
| Networking-ofagent(ryu) | ryu专注于sdn controller方面,该项目已很久未更新 | 日本NTT公司 |
至于目前新机房的网络设备接入层的vxlan设备尚未明确,具体的SDN接入还无法给出明确的方案。并且Neutron与SDN的集成还需要网络硬件厂商的驱动支持,所以在选型的时候可以和设备厂商做详情沟通。