一、获取数据
想弄一个数据库,由于需要一些人名,所以就去百度一下,然后发现了360图书馆中有很多人名
然后就像去复制一下,发现复制不了,需要登陆


此时f12查看源码是可以复制的,不过就算可以复制想要插入数据也是很麻烦的。既然复制走不通,于是我抱着探索知识的精神,打开了Visual Studio
首先我们需要先拿到整个页面的数据,此时的话可以使用WebClient对象来获取数据(HttpWebRequest方式稍微有点麻烦),然后使用byte数组来接受一下返回值
public static void GetData(String address) { WebClient wc = new WebClient(); byte[] htmlData = wc.DownloadData(address); }
此时需要将htmlData对象解码为String对象,然后我们在网站中f12看一下解码方式

可以看到charset=utf-8,说明需要用utf-8来解码,然后使用Encoding对象来解码
string html = Encoding.UTF8.GetString(htmlData);
我们输出一下html有没有值
static void Main(string[] args) { //将地址复制过来 GetData("http://www.360doc.com/content/18/1010/13/642066_793541226.shtml"); Console.ReadKey(); } public static void GetData(String address) { WebClient wc = new WebClient(); //地址由调用时传入 byte[] htmlData = wc.DownloadData(address); string html = Encoding.UTF8.GetString(htmlData); Console.WriteLine(html); }
输出:


二、Regex匹配
接下来就是匹配的问题了,首先看一下html文档的结构

就是说只需要匹配到所有的p标签,然后拿到其中的内容就行了
第一种想到的就是使用正则表达式匹配:
public static void GetData(String address) { WebClient wc = new WebClient(); //地址由调用时传入 byte[] htmlData = wc.DownloadData(address); string html = Encoding.UTF8.GetString(htmlData); //使用正则表达式匹配非空字符至少100个 Regex reg = new Regex("<[pP]>\\S{100,}"); //接受所有匹配到的项 MatchCollection result = reg.Matches(html); //循环输出 foreach (Match item in result) { Console.WriteLine(item.Value); } }
调用不变,启动:
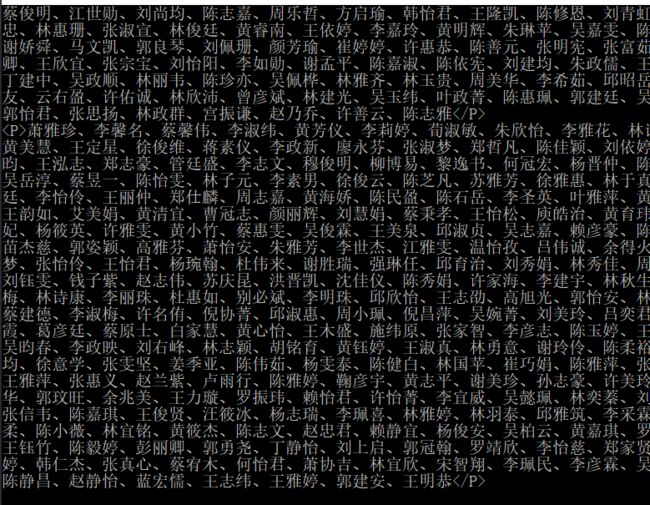
匹配到是匹配到了,但是我们把
标签也匹配出来了,所以把正则表达式改进一下,使用组匹配,将p标签中的内容单独匹配出来(当然也可以截取字符串)。也就是说在写正则表达式时,将想要单独匹配出来的数据用括号"(想要单独匹配出来的数据)"括起来,来看一下怎么写:Regex reg = new Regex("<[pP]>(\\S{100,})");
然后如果想要拿数据的话,需要使用Match对象的Groups属性通过索引来获取匹配到的组:
public static void GetData(String address) { WebClient wc = new WebClient(); //地址由调用时传入 byte[] htmlData = wc.DownloadData(address); string html = Encoding.UTF8.GetString(htmlData); //使用正则表达式组匹配(非空字符至少100个) Regex reg = new Regex("<[pP]>(\\S{100,})"); //接受所有匹配到的项 MatchCollection result = reg.Matches(html); //循环输出 foreach (Match item in result) { //0的话是整体匹配到的字符串对象 //1就是第一个匹配到的组(\\S{100,) Console.WriteLine(item.Groups[1]); } }
输出结果:

这次p标签就没有被匹配进入组中(如果通过item.Groups[0]拿到的回是和上面匹配到一样的数据,会带p标签)
匹配到了之后就可以使用item.Groups[1].Split('、')来将字符串分割为String数组,然后循环写入数据库,或者进行其他操作。
三、HTML解析器NSoup
虽然正则表达式也可以匹配,但是如果对正则表达式比较陌生的话,可能就不是友好了。如果有方法可以像用js操作html元素一样,用C#操作html字符串,就非常棒了。NSoup就是可以做到解析html字符串,变成可操作的对象。
首先使用前先在管理NuGet程序包中添加:NSoup,直接就可以搜索到,添加完成之后接下来就看一下如何使用
使用NSoupClient.Parse(放入html代码:....)创建一个声明Docuemnt文档对象:
//声明Document对象 Document doc = NSoupClient.Parse(html);
第二种就是使用Document doc = NSoupClient.Connect(放入url) .Get()/.Post(),然后他就会自动获取url地址的html代码,并且根据html代码加载一个Document对象
//通过url自动加载Document对象 Document doc = NSoupClient.Connect(address).Get();
当然还有其他方式获取,然后我们看一下如何使用Document对象
//通过id获取元素 //获取id为form的元素 Element form = doc.GetElementById("form"); //通过标签名获取元素 //获取所有的p标签 Elements p = doc.GetElementsByTag("p"); //通过类样式获取元素 //获取类样式为btn的元素 Elements c = doc.GetElementsByClass("btn"); //通过属性获取 //获取包含style属性的元素 Elements attr = doc.GetElementsByAttribute("style");
也可以自己组合一些其他的嵌套操作,例如:

获取id为artContent下的所有p标签
//使用链式编程 //获取id为artContent下的所有p标签 Elements ps = doc.GetElementById("artContent").GetElementsByTag("p"); //等同于 //Element artContent = doc.GetElementById("artContent"); //Elements ps = artContent.GetElementsByTag("p");
元素方法的使用:
//Elements是Element元素的集合 多了个s //Element对象的方法 Element id = doc.GetElementById("id"); //获取或设置id元素的文本 id.Text(); //获取或设置id元素的html代码 id.Html(); //获取或设置id元素的value值 id.Val();
都是像js操作html元素一样的方法,而且方法的名字也很人性,基本上一看就会知道方法是什么意思,方法也太多了就不一一讲了。
然后我们来使用NSoup获取所有的名字,来试一下就会发现很简单了:
方式一:
public static void GetData(String address) { WebClient wc = new WebClient(); byte[] htmlData = wc.DownloadData(address); string html = Encoding.UTF8.GetString(htmlData); Document doc = NSoupClient.Parse(html); //先获取id为artContent的元素,再获取所有的p标签 Elements p = doc.GetElementById("artContent").GetElementsByTag("p"); foreach (Element item in p) { Console.WriteLine(item.Text()); } }
方式二:
public static void GetData(String address) { //直接通过url来获取Document对象 Document doc = NSoupClient.Connect(address).Get(); //先获取id为artContent的元素,再获取所有的p标签 Elements p = doc.GetElementById("artContent").GetElementsByTag("p"); foreach (Element item in p) { Console.WriteLine(item.Text()); } }
运行结果都是一样的

总结:效率的话不太了解就不做评价了,就简单说一下优缺点:使用正则表达式的话,需要对正则表达式有一定的熟悉,然后匹配数据的话也是很方便的,但是修改、添加、删除的话就不是太方便了;使用HTMl解析器(HtmlAgilityPack、NSoup)的话操作起来明显更方便一些,如果对js有一定的基础,html解析器根本不需要大学习就可以熟练使用,然后对元素进行修改、添加、删除、获取都是非常方便的,不过如果对于未知的html结构就不是太友好了,例如:如果获取页面上所有的http://www.baidu.com这类的地址的话,使用正则就会更好一些。
