转载自:https://www.cnblogs.com/vice/p/9163241.html
操作系统是Windows2008R2 ,数据库是SQL2014 64位。
近阶段服务器出现过几次死机,管理员反馈机器内存使用率100%导致机器卡死。于是做了个监测服务器的软件实时记录CPU数据,几日观察得出数据如下:
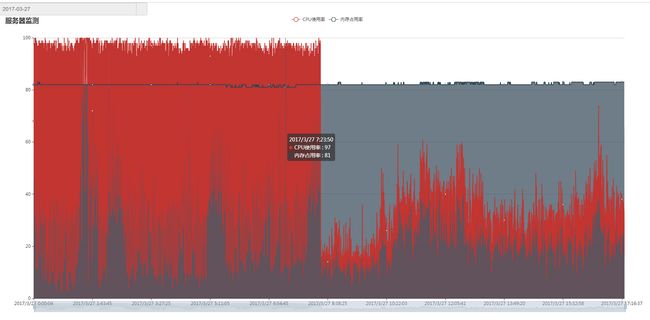
SQL优化方法:
1、查看连接对象
1 USE master 2 GO 3 --如果要指定数据库就把注释去掉 4 SELECT * FROM sys.[sysprocesses] WHERE [spid]>50 --AND DB_NAME([dbid])='gposdb'

当前连接对象有67个其中‘WINAME’的主机名,‘jTDS’的进程名不属于已知常用软件,找到这台主机并解决连接问题。在360流量防火墙中查看有哪个软件连接了服务器IP,除之。

2、然后使用下面语句看一下各项指标是否正常,是否有阻塞,正常情况下搜索结果应该为空。
按 Ctrl+C 复制代码
按 Ctrl+C 复制代码
查看是哪些SQL语句占用较大可以使用下面代码
按 Ctrl+C 复制代码
按 Ctrl+C 复制代码
3、如果SQLSERVER存在要等待的资源,那么执行下面语句就会显示出会话中有多少个worker在等待
1 SELECT TOP 10 2 [session_id], 3 [request_id], 4 [start_time] AS '开始时间', 5 [status] AS '状态', 6 [command] AS '命令', 7 dest.[text] AS 'sql语句', 8 DB_NAME([database_id]) AS '数据库名', 9 [blocking_session_id] AS '正在阻塞其他会话的会话ID', 10 der.[wait_type] AS '等待资源类型', 11 [wait_time] AS '等待时间', 12 [wait_resource] AS '等待的资源', 13 [dows].[waiting_tasks_count] AS '当前正在进行等待的任务数', 14 [reads] AS '物理读次数', 15 [writes] AS '写次数', 16 [logical_reads] AS '逻辑读次数', 17 [row_count] AS '返回结果行数' 18 FROM sys.[dm_exec_requests] AS der 19 INNER JOIN [sys].[dm_os_wait_stats] AS dows 20 ON der.[wait_type]=[dows].[wait_type] 21 CROSS APPLY 22 sys.[dm_exec_sql_text](der.[sql_handle]) AS dest 23 WHERE [session_id]>50 24 ORDER BY [cpu_time] DESC
4、查询CPU占用最高的SQL语句
1 SELECT TOP 10 2 total_worker_time/execution_count AS avg_cpu_cost, plan_handle, 3 execution_count, 4 (SELECT SUBSTRING(text, statement_start_offset/2 + 1, 5 (CASE WHEN statement_end_offset = -1 6 THEN LEN(CONVERT(nvarchar(max), text)) * 2 7 ELSE statement_end_offset 8 END - statement_start_offset)/2) 9 FROM sys.dm_exec_sql_text(sql_handle)) AS query_text 10 FROM sys.dm_exec_query_stats 11 ORDER BY [avg_cpu_cost] DESC
5、索引缺失查询
1 SELECT 2 DatabaseName = DB_NAME(database_id) 3 ,[Number Indexes Missing] = count(*) 4 FROM sys.dm_db_missing_index_details 5 GROUP BY DB_NAME(database_id) 6 ORDER BY 2 DESC; 7 SELECT TOP 10 8 [Total Cost] = ROUND(avg_total_user_cost * avg_user_impact * (user_seeks + user_scans),0) 9 , avg_user_impact 10 , TableName = statement 11 , [EqualityUsage] = equality_columns 12 , [InequalityUsage] = inequality_columns 13 , [Include Cloumns] = included_columns 14 FROM sys.dm_db_missing_index_groups g 15 INNER JOIN sys.dm_db_missing_index_group_stats s 16 ON s.group_handle = g.index_group_handle 17 INNER JOIN sys.dm_db_missing_index_details d 18 ON d.index_handle = g.index_handle 19 ORDER BY [Total Cost] DESC;
找到索引缺失的表,根据查询结果中的关键次逐一建立索引。
做完这些测试,基本能找到问题。