Binder是一个类似于C/S架构的通信框架,有时候客户端可能想知道服务端的状态,比如服务端如果挂了,客户端希望能及时的被通知到,而不是等到再起请求服务端的时候才知道,这种场景其实在互为C/S的时候最常用,比如AMS与APP,当APP端进程异常退出的时候,AMS希望能及时知道,不仅仅是清理APP端在AMS中的一些信息,比如ActivityRecord,ServiceRecord等,有时候可能还需要及时恢复一些自启动的Service。Binder实现了一套”死亡讣告”的功能,即:服务端挂了,或者正常退出,Binder驱动会向客户端发送一份讣告,告诉客户端Binder服务挂了。
这个“讣告”究竟是如何实现的呢?其作用又是什么呢?对于Android而言,Binder“讣告”有点采用了类似观察者模式,因此,首先需要将Observer注册到目标对象中,其实就是将Client注册到Binder驱动,将来Binder服务挂掉时候,就能通过驱动去发送。Binder“讣告”发送的入口只有一个:在释放binder设备的时候,在在操作系统中,无论进程是正常退出还是异常退出,进程所申请的所有资源都会被回收,包括打开的一些设备文件,如Binder字符设备等。在释放的时候,就会调用相应的release函数,“讣告”也就是在这个时候去发送的。因此Binder讣告其实就仅仅包括两部分:注册与通知。
Binder"讣告"的注册入口
这里拿bindService为例子进行分析,其他场景类似,bindService会首先请求AMS去启动Service,Server端进程在启动时,会调用函数open来打开设备文件/dev/binder,同时将Binder服务实体回传给AMS,AMS再将Binder实体的引用句柄通过Binder通信传递给Client,也就是在AMS回传给Client的时候,会向Binder驱动注册。其实这也比较好理解,获得了服务端的代理,就应该关心服务端的死活 。当AMS利用IServiceConnection这条binder通信线路为Client回传Binder服务实体的时候,InnerConnection就会间接的将死亡回调注册到内核:
private static class InnerConnection extends IServiceConnection.Stub {
final WeakReference mDispatcher;
public void connected(ComponentName name, IBinder service) throws RemoteException {
LoadedApk.ServiceDispatcher sd = mDispatcher.get();
if (sd != null) {
sd.connected(name, service);
}
}
}
ServiceDispatcher函数进一步调用 doConnected
public void doConnected(ComponentName name, IBinder service) {
ServiceDispatcher.ConnectionInfo old;
ServiceDispatcher.ConnectionInfo info;
synchronized (this) {
if (service != null) {
mDied = false;
info = new ConnectionInfo();
info.binder = service;
info.deathMonitor = new DeathMonitor(name, service);
try {
service.linkToDeath(info.deathMonitor, 0);
}
}
看关键点点1 ,这里的IBinder service其实是AMS回传的服务代理BinderProxy,linkToDeath是一个Native函数,会进一步调用BpBinde的linkToDeath:
status_t BpBinder::linkToDeath(
const sp& recipient, void* cookie, uint32_t flags){
IPCThreadState* self = IPCThreadState::self();
self->requestDeathNotification(mHandle, this);
self->flushCommands();
}
最终调用IPCThreadState的requestDeathNotification(mHandle, this)向内核发送BC_REQUEST_DEATH_NOTIFICATION请求:
status_t IPCThreadState::requestDeathNotification(int32_t handle, BpBinder* proxy)
{
mOut.writeInt32(BC_REQUEST_DEATH_NOTIFICATION);
mOut.writeInt32((int32_t)handle);
mOut.writeInt32((int32_t)proxy);
return NO_ERROR;
}
最后来看一下在内核中,是怎么登记注册的:
int
binder_thread_write(struct binder_proc *proc, struct binder_thread *thread,
void __user *buffer, int size, signed long *consumed)
{
...
case BC_REQUEST_DEATH_NOTIFICATION:
case BC_CLEAR_DEATH_NOTIFICATION: {
...
ref = binder_get_ref(proc, target);
if (cmd == BC_REQUEST_DEATH_NOTIFICATION) {
...关键点1
death = kzalloc(sizeof(*death), GFP_KERNEL);
binder_stats.obj_created[BINDER_STAT_DEATH]++;
INIT_LIST_HEAD(&death->work.entry);
death->cookie = cookie;
ref->death = death;
if (ref->node->proc == NULL) {
ref->death->work.type = BINDER_WORK_DEAD_BINDER;
if (thread->looper & (BINDER_LOOPER_STATE_REGISTERED | BINDER_LOOPER_STATE_ENTERED)) {
list_add_tail(&ref->death->work.entry, &thread->todo);
} else {
list_add_tail(&ref->death->work.entry, &proc->todo);
wake_up_interruptible(&proc->wait);
}
}
}
}
看关键点1 ,其实就是为Client新建binder_ref_death对象,并赋值给binder_ref。在binder驱动中,binder_node节点会记录所有binder_ref,当binder_node所在的进程挂掉后,驱动就能根据这个全局binder_ref列表找到所有Client的binder_ref,并对于设置了死亡回调的Client发送“讣告”,这是因为在binder_get_ref_for_node向Client插入binder_ref的时候,也会插入binder_node的binder_ref列表。
static struct binder_ref *
binder_get_ref_for_node(struct binder_proc *proc, struct binder_node *node)
{
struct rb_node *n;
struct rb_node **p = &proc->refs_by_node.rb_node;
struct rb_node *parent = NULL;
struct binder_ref *ref, *new_ref;
if (node) {
hlist_add_head(&new_ref->node_entry, &node->refs);
}
return new_ref;
}
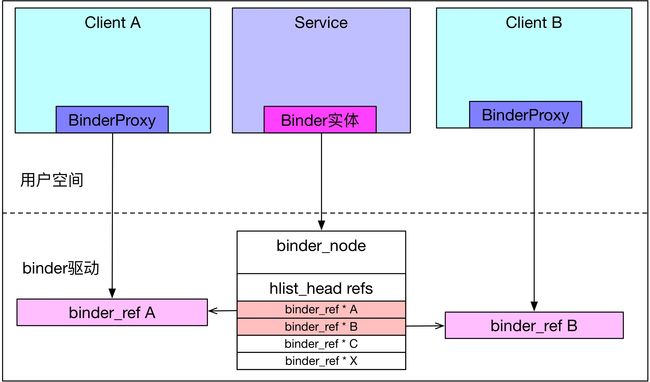
如此,死亡回调入口就被注册到binder内核驱动,之后,等到进程结束要释放binder的时候,就会触发死亡回调。

死亡通知的发送
在调用binder_realease函数来释放相应资源的时候,最终会调用binder_deferred_release函数。该函数会遍历该binder_proc内所有的binder_node节点,并向注册了死亡回调的Client发送讣告,
static void binder_deferred_release(struct binder_proc *proc)
{ ....
if (ref->death) {
death++;
if (list_empty(&ref->death->work.entry)) {
ref->death->work.type = BINDER_WORK_DEAD_BINDER;
list_add_tail(&ref->death->work.entry, &ref->proc->todo);
// 插入到binder_ref请求进程的binder线程等待队列????? 天然支持binder通信吗?
// 什么时候,需要死亡回调,自己也是binder服务?
wake_up_interruptible(&ref->proc->wait);
}
...
}
死亡讣告被直接发送到Client端的binder进程todo队列上,这里似乎也只对于互为C/S通信的场景有用,当Client的binder线程被唤醒后,就会针对“讣告”做一些清理及善后工作:
static int
binder_thread_read(struct binder_proc *proc, struct binder_thread *thread,
void __user *buffer, int size, signed long *consumed, int non_block)
{
case BINDER_WORK_DEAD_BINDER:
case BINDER_WORK_DEAD_BINDER_AND_CLEAR:
case BINDER_WORK_CLEAR_DEATH_NOTIFICATION: {
struct binder_ref_death *death = container_of(w, struct binder_ref_death, work);
uint32_t cmd;
if (w->type == BINDER_WORK_CLEAR_DEATH_NOTIFICATION)
cmd = BR_CLEAR_DEATH_NOTIFICATION_DONE;
else
cmd = BR_DEAD_BINDER;
...
}
这里会向用户空间写入一个BR_DEAD_BINDER命令,并返回talkWithDriver函数,返回后,IPCThreadState会继续执行executeCommand,
status_t IPCThreadState::executeCommand(int32_t cmd)
{
// 死亡讣告
case BR_DEAD_BINDER:
{
BpBinder *proxy = (BpBinder*)mIn.readInt32();
proxy->sendObituary();
mOut.writeInt32(BC_DEAD_BINDER_DONE);
mOut.writeInt32((int32_t)proxy);
} break;
}
看关键点1,Obituary直译过来就是讣告,其实就是利用BpBinder发送讣告,待讣告处理结束后,再向Binder驱动发送确认通知。
void BpBinder::sendObituary()
{
ALOGV("Sending obituary for proxy %p handle %d, mObitsSent=%s\n",
this, mHandle, mObitsSent ? "true" : "false");
mAlive = 0;
if (mObitsSent) return;
mLock.lock();
Vector* obits = mObituaries;
if(obits != NULL) {
IPCThreadState* self = IPCThreadState::self();
self->clearDeathNotification(mHandle, this);
self->flushCommands();
mObituaries = NULL;
}
mObitsSent = 1;
mLock.unlock();
if (obits != NULL) {
const size_t N = obits->size();
for (size_t i=0; iitemAt(i));
}
delete obits;
}
}
看关键点1,这里跟注册相对应,将自己从观察者列表中清除,之后再上报
void BpBinder::reportOneDeath(const Obituary& obit)
{
sp recipient = obit.recipient.promote();
ALOGV("Reporting death to recipient: %p\n", recipient.get());
if (recipient == NULL) return;
recipient->binderDied(this);
}
进而调用上层DeathRecipient的回调,做一些清理之类的逻辑。以AMS为例,其binderDied函数就挺复杂,包括了一些数据的清理,甚至还有进程的重建等,不做讨论。

Android后台杀死系列之一:FragmentActivity及PhoneWindow后台杀死处理机制
Android后台杀死系列之二:ActivityManagerService与App现场恢复机制
Android后台杀死系列之三:LowMemoryKiller原理(4.3-6.0)
Android后台杀死系列之四:Binder讣告原理
Android后台杀死系列之五:Android进程保活-自“裁”或者耍流氓
作者:看书的小蜗牛
原文链接: Android后台杀死系列之四:Binder讣告原理
参考文档
Android Binder 分析——死亡通知(DeathRecipient)