在hyperledger fabric的orderer中,目前发布的版本是使用kafka来做排序,并没有用到所谓的sbft。kafka作为一个消息中间件,来对orderer发过来的消息进行排序,这样所有的orderer可以当做consumer来去kafka上去取消息。kafka具体和fabric怎么合作,我们按下不表。这篇文章主要介绍kafka的工作原理,以及怎样和zookeeper合作。
Zookeeper的原理
1. Zookeeper是什么
ZooKeeper是一种为分布式应用所设计的高可用、高性能且一致的开源协调服务,它提供了一项基本服务:分布式锁服务。由于ZooKeeper的开源特性,后来我们的开发者在分布式锁的基础上,摸索了出了其他的使用方法:配置维护、组服务、分布式消息队列、分布式通知/协调等。
2. 为什么要用Zookeeper
分布式节点的各个节点的协调是分布式服务必须要解决的一个问题。举个例子来说明
为什么要使用分布式节点呢?是为了解决所谓的单点故障。什么是单点故障呢?如下图所示,一个主节点Master提供服务给其他机器,那么如果这个Master节点挂了呢?是不是Slave从节点就无法享受到该服务了呢?
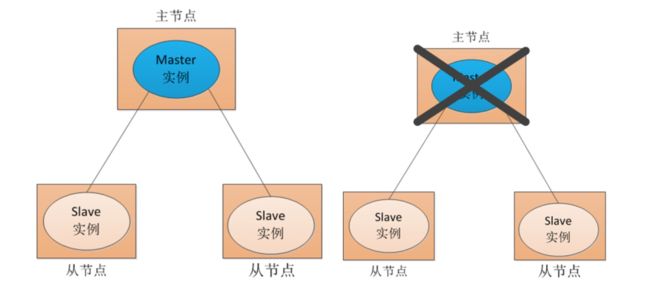
一般对这种单点故障的解决办法是双Master或者多集群。如下图所示,采用两个Master,一个为主节点,一个为备份节点。一旦发现主节点有问题(挂了或者出错),则立即切换到备份节点。
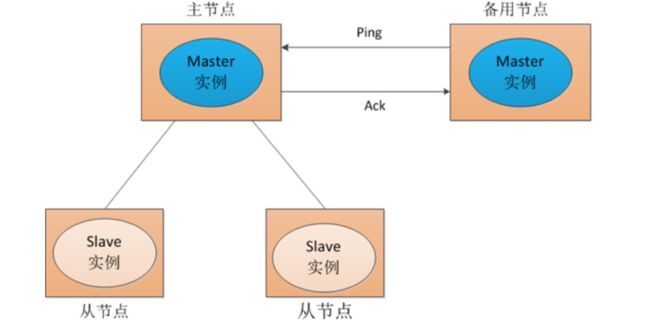
如下图所示,所有的slave在收到消息后,直接切换到备用节点。
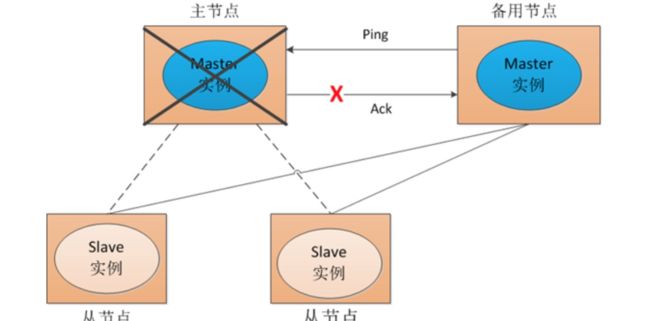
然而在有时候主节点没有宕机,然而Slave节点或者其他Master节点认为他宕机了,这样极其容易造成彼此之间的视图(对整个集群的理解)不一致。如下图所示:
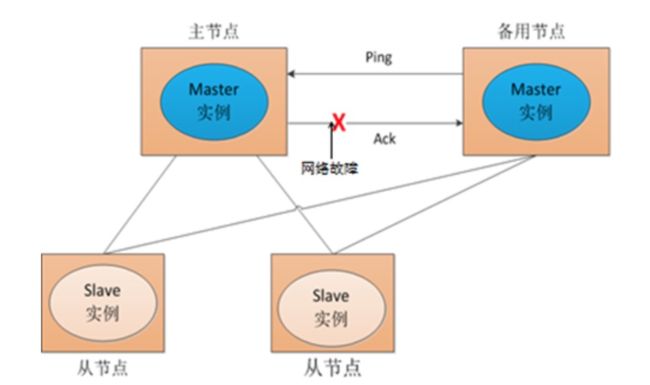
当集群中的节点出现对集群的理解不一致时,会对强一致性的程序产生很坏的影响,有可能会造成消息的乱序。所以一致性问题的解决有很多办法,比如PBFT,RAFT或者锁等等。每种办法都有各自的优劣。
那么Zookeeper的引入,怎么能解决这个全局视图保证一致呢?
如下图所示,主节点A和主节点B在启动的时候,都首先向Zookeeper节点注册,Zookeeper会将这两个节点写入到自己的文件系统内,并分配给每个节点一个id号。与此同时,Zookeeper节点会保持与两个Master节点的心跳,每隔几个tick(自己定义在配置文件里)与节点沟通一次,以此验证节点的状态。这样哪个节点宕机,哪个节点新加入等等都可以实时的反应在zookeeper上。Slave节点想知道连哪个主节点,根据自己的算法去选择。比如kafka就会根据topic随机选择leader。所有人都可以在zookeeper上设置监听,一旦某个主节点有变动,大家都会收到zookeeper的推送消息。

写到这里估计有人得问,你这不也会有单点故障的风险吗?比如这个zookeeper挂了怎么办?这个问题是个好问题。zookeeper可以设置集群,也就是几个zookeeper可以同时对外服务。那么zookeeper集群如何保证一致性的?怎样保证所有的zookeeper对外部世界的理解一致的?总不能这个zookeeper知道MasterA是正常的,那个zookeeper以为MasterA是不正常吧!
还是一致性的问题,这个zookeeper用了ZAB共识算法来保证各个zookeeper节点的一致性。
3. 怎样使用Zookeeper
zookeeper的启动需要配置如下的信息(本文以docker启动),太坑了,这里竟然不能用代码。
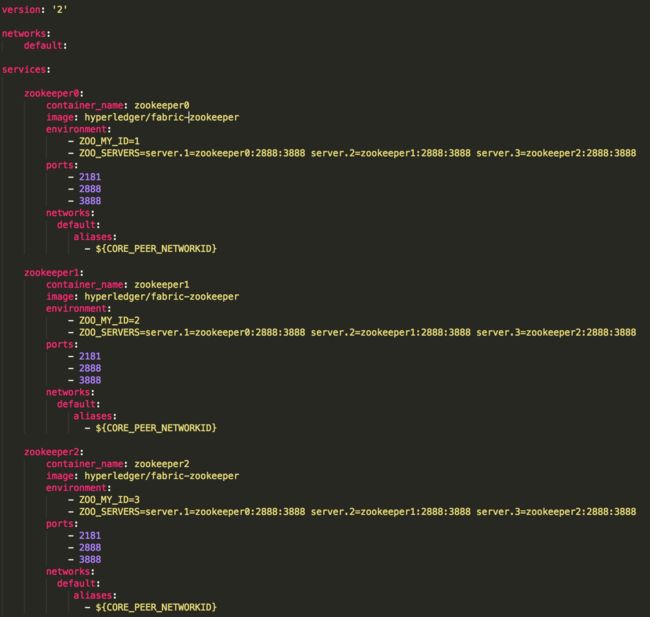
从上图可以看出ZOO_MY_ID为每个zookeeper的唯一id号,ZOO_SERVERS为集群的ip及端口。当zookeeper起来后,可以直接进入zookeeper所在的bin目录,查找zkCli.sh。通过该可执行脚本可以找到注册在zookeeper上的服务。zkCli.sh所在目录如下图所示:
执行该脚本后,进入zkCli的控制台,在该控制台可以查看注册到zookeeper的服务。本例以kafka来举例:
可以到brokers目录下查看注册的kafka节点数目。
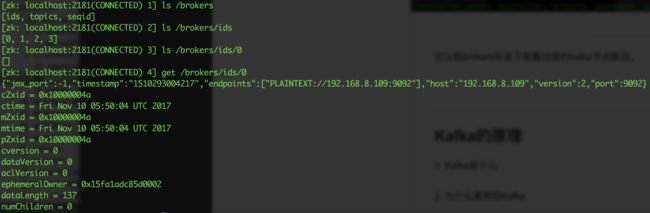
从上图中,可以看到注册到zookeeper的kafka有四个,id分别为0,1,2,3。其中0的注册信息可以通过 get /brokers/ids/0来获得。
各个字段的含义如下:
czxid.节点创建时的zxid.mzxid.节点最新一次更新发生时的
zxid.ctime.节点创建时的时间戳.
mtime.节点最新一次更新发生时的时间戳.
dataVersion.节点数据的更新次数.
cversion.其子节点的更新次数.
aclVersion.节点ACL(授权信息)的更新次数.
ephemeralOwner.如果该节点为ephemeral节点,ephemeralOwner值表示与该节点绑定的sessionid.如果该节点不是ephemeral节点,ephemeralOwner值为0.
dataLength.节点数据的字节数.
numChildren.子节点个数.
关于zxid的定义:ZooKeeper状态的每一次改变, 都对应着一个递增的Transaction id, 该id称为zxid. 由于zxid的递增性质, 如果zxid1小于zxid2, 那么zxid1肯定先于zxid2发生. 创建任意节点, 或者更新任意节点的数据, 或者删除任意节点, 都会导致Zookeeper状态发生改变, 从而导致zxid的值增加.
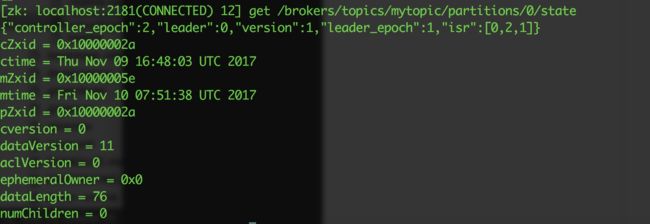
再举个例子,下图是kafka节点创建的mytopic,可以看到在0号分区的kafka主节点是0号,isr分别同步到0,1,2节点。而且通过dataVersion可以看到改变了11次,说明发了11条消息。
Kafka的原理
1. Kafka是什么
Kafka是一种分布式的,基于发布/订阅的消息系统。为什么要用的消息系统呢?因为利用消息系统有如下的好处:
a) 系统解耦。系统解耦带来的好处就是扩展性增强。
b) 事件分发。这样做的好处就是带来了异步通信,不用某个模块等待另外一个模块,而是将消息发送过去就不用管了,或者消费者只管去拉消息。
c) 消息回溯。举个简单的例子,在玩游戏的过程中,想要做视频回放,那么消息系统里做一次记录即可。开个不是玩笑的玩笑,现在很多人拿kafka当数据库来用。简单方便。
d) ......
2. 为什么要用到Kafka
a) 快速持久化,可以在O(1)的系统开销下进行消息持久化。这个经过本人的验证,的确太不可思议了,非常快,源于kafka良好的顺序写模式。
b) 高吞吐,我自己测的tps可以达到几十万;
c) 同时支持单播与广播。同一个topic的数据,会广播给不同的group;同一个group中的worker,只有一个worker能拿到这个数据
d) 支持存储。很多人把kafka当数据库来存储东西。
e) 支持分布式存储。kafka可以和其他的kafka节点形成kafka集群,通过kafka的isr模式,topic的分区可以分布于不同的节点。
f) ......
3. 怎样使用Kafka
先介绍一下kafka的相关概念。
Broker:指服务于Kafka的一个节点。
topic是一个逻辑概念,用于保证Producer以及Consumer能够通过该标示进行对接。
partition是消息的真实存放者。partition会实际存储在系统的某个目录。它Topic的一个子概念,
一个topic可具有多个partition,但Partition一定属于一个topic。
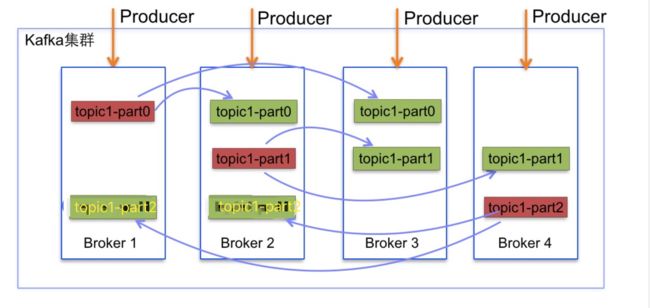
下列是一个kafka集群,从下图可以看出一共有四个节点,分别为Broker1, Broker2, Broker3, Broker4. 该集群一共有一个topic,该topic供有三个partition,分别为part0, part1, part2。其中part0分别存储在Broker1, Broker2, Broker3上。而part1分别存储在Broker2, Broker3, Broker4。part2分半存储在Broker1, Broker2, Broker4中。part0的三个Broker中,Broker1为主节点。part1的主节点为Broker2, part2的主节点为Broker4。三个partition均匀分布。
需要的环境:
docker--为啥需要这个呢,因为可以很容易的模拟多机部署,当然如果你是土豪,可以忽略这个,安装步骤在这里,当然你也可以参考别的文档来安装docker及docker-compose
1. 启动kafka和zookeeper节点
利用下面的docker-compose.yml来启动kafka与zookeeper,下面配置文件里启动了三个zookeeper和4个kafka节点,三个zookeeper组成了一个zookeeper集群,管理kafka节点。
三个zookeeper节点分别为zookeeper0,zookeeper1,zookeeper2
四个kafka节点分别为kafka0,kafka1,kafka2,kafka3
我的zookeeper节点是基于hyperledger/fabric-zookeeper的docker镜像来启动的,可以到zookeeper镜像地址下载。而kafka节点是基于hyperledger/fabric-kafka的docker镜像来启动的,可以到kafka镜像地址下载。
拷贝下面配置文件,并保存到docker-compose.yml文件中。
在docker-compose.yml所在的目录中,运行命令docker-compose up -d 命令来启动容器。
创建完成后,可以进入zookeeper容器检查kafka节点是否都已经注册成功。
运行docker ps命令,列举出所有的容器,如下:
进入其中的一个zookeeper容器,通过如下命令

运行zkCli.sh命令,来检查kafka节点有没有注册到zookeeper上。


检查其中的一个broker id 如下:
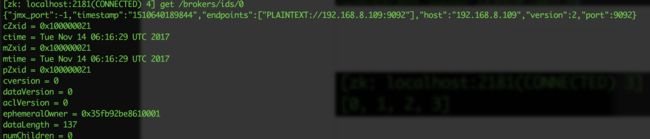
从中可以知道brokerid 0,1,2,3都已经注册到zookeeper集群上了,而详细brokerid 0的信息中可以得到其ip,端口等等。
具体kafka在zookeeper上的注册消息图如下,详细我找到了一个网页 ,可以参考

2. 创建topic
进入kafka节点,利用下述命令

运行下述命令,创建mytopic,该topic有一个分区,部署有三个副本。
可以进入zookeeper节点,用zkCli.sh查看topic下的信息如下。
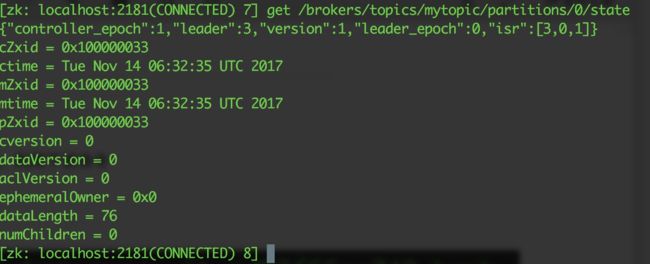
从中可以看出broker3为主节点,总共有3个副本,分别是broker0,broker1,broker3
3. 发送消息
进入kafka容器,利用该kafka自带脚本可以发送消息,如下即向本kafka节点的mytopic发送消息
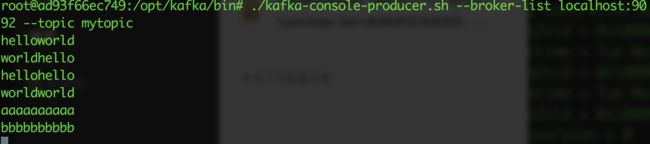
4. 消费消息
进入kafka容器,利用kafka自带脚本,可以对消息进行消费,如下即向kafka节点消费消息

到zookeeper中,启动zkCli.sh可以看到,消费者是在zookeeper中注册了消费者id,这样可以保障group单播。
本文参考:
https://www.cnblogs.com/wuxl360/p/5817471.html
http://blog.csdn.net/lizhitao/article/details/51718185
http://blog.csdn.net/lizhitao/article/details/23744675
http://blog.csdn.net/eric_sunah/article/details/46891901