一、总体流程
caffe主要有四个功能模块。
a) Blob 主要用来表示网络中的数据,包括训练数据,网络各层自身的参数(包括权值、偏置以及它们的梯度),网络之间传递的数据都是通过 Blob 来实现的,同时 Blob 数据也支持在 CPU 与 GPU 上存储,能够在两者之间做同步。
b) Layer 是对神经网络中各种层的一个抽象,包括我们熟知的卷积层和下采样层,还有全连接层和各种激活函数层等等。同时每种 Layer 都实现了前向传播和反向传播,并通过 Blob 来传递数据。
c) Net 是对整个网络的表示,由各种 Layer 前后连接组合而成,也是我们所构建的网络模型。
d) Solver 定义了针对 Net 网络模型的求解方法,记录网络的训练过程,保存网络模型参数,中断并恢复网络的训练过程。自定义 Solver 能够实现不同的网络求解方式。
整体的框架是以layer为主,不同的layer完成不同的功能,如卷积,反卷积等。net是管理layer的,solver是做训练用的,而核心的创新就是blob数据了,以一个四元组完成了各种数据的传输,同时解决了cpu和gpu共享数据的问题。
二. 卷积操作
对图像(不同的数据窗口数据)和滤波矩阵(一组固定的权重:因为每个神经元的多个权重固定,所以又可以看做一个恒定的滤波器filter)做内积(逐个元素相乘再求和)的操作就是所谓的『卷积』操作,也是卷积神经网络的名字来源。
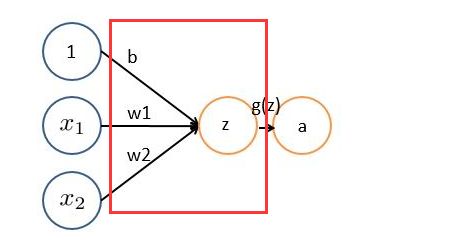
(上图可以看作一个滤波器filter,多个filter构成一个卷积层)
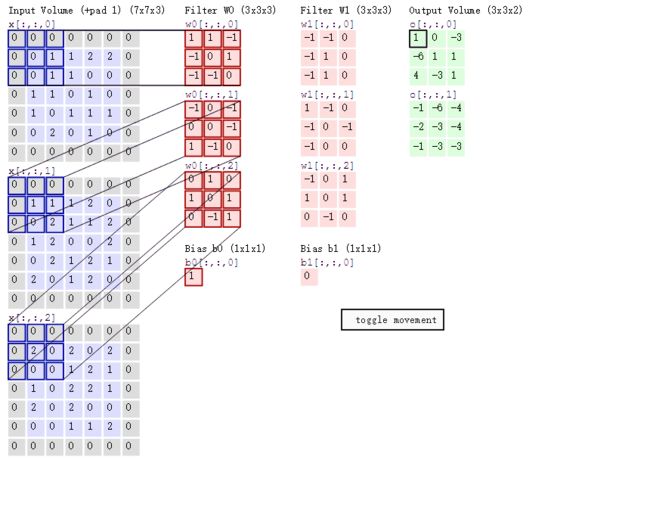
3. caffe中的数学函数
A) caffe_cpu_gemm 函数:
void caffe_cpu_gemm(const CBLAS_TRANSPOSE TransA, const CBLAS_TRANSPOSE TransB, const int M, const int N, const int K, const float alpha, const float* A, const float* B, const float beta, float* C)
功能: C=alpha*A*B+beta*C
A,B,C 是输入矩阵(一维数组格式)
CblasRowMajor :数据是行主序的(二维数据也是用一维数组储存的)
TransA, TransB:是否要对A和B做转置操作(CblasTrans CblasNoTrans)
M: A、C 的行数
N: B、C 的列数
K: A 的列数, B 的行数
lda : A的列数(不做转置)行数(做转置)
ldb: B的列数(不做转置)行数(做转置)
这个函数主要是用了库函数的运算公式进行矩阵相乘,那接下来就是怎么将卷积运算转化为矩阵相乘的问题了,这就需要用到image2col的函数了。
B) image2col 函数:
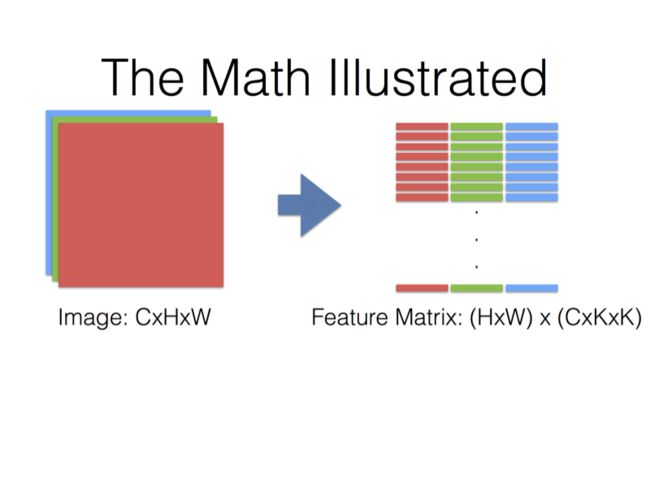
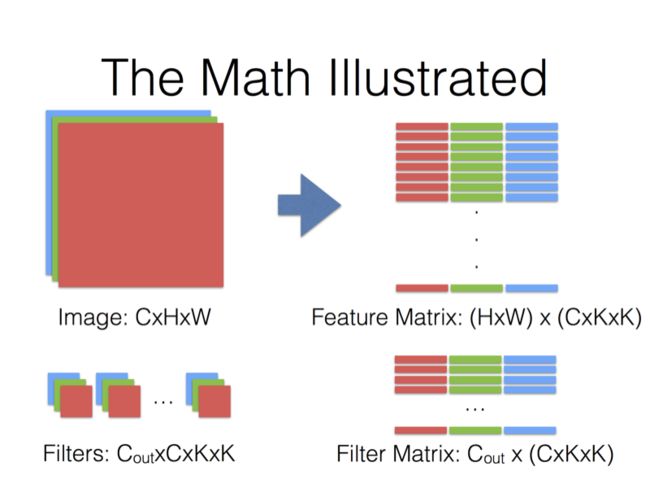
最终:Filter Matrix乘以Feature Matrix,得到输出矩阵Cout x (H x W)。
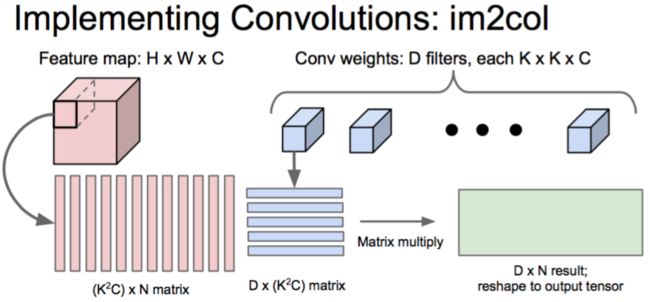
再说的详细点:

如上图
(1)在矩阵A中
M为卷积核个数,K=k*k,等于卷积核大小,即第一个矩阵每行为一个卷积核向量(是将二维的卷积核转化为一维),总共有M行,表示有M个卷积核。
(2)在矩阵B中
因此,N为输出图像大小的长宽乘积,也是卷积核在输入图像上滑动可截取的最大特征数。
K=k*k,表示利用卷积核大小的框在输入图像上滑动所截取的数据大小,与卷积核大小一样大。
(3)在矩阵C中
矩阵C为矩阵A和矩阵B相乘的结果,得到一个M*N的矩阵,其中每行表示一个输出图像即feature map,共有M个输出图像(输出图像数目等于卷积核数目)
Caffe中的卷积计算是将卷积核矩阵和输入图像矩阵变换为两个大的矩阵A与B,然后A与B进行矩阵相乘得到结果C。
C)im2col_cpu分析
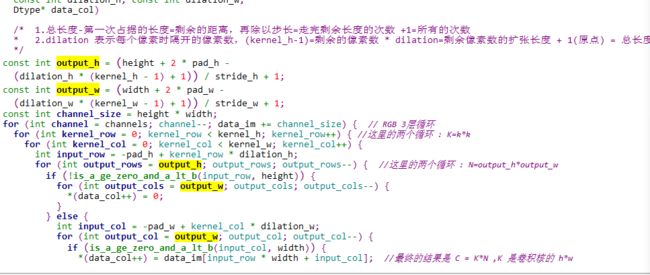
1.结合代码分析以下公式的由来
int output_h = (height + 2 * pad_h - (dilation_h * (kernel_h - 1) + 1)) / stride_h + 1;
int output_w = (width + 2 * pad_w -(dilation_w * (kernel_w - 1) + 1)) / stride_w +1;
2.先不要dilation_h 和dilation_w ,如下:
N=((image_h + 2*pad_h – kernel_h)/stride_h+ 1)*((image_w +2*pad_w – kernel_w)/stride_w + 1)
这里要结合动态stride滑动卷积图
原理: N = H*W
H: 在image高度方向上滑动的总次数。W:在image宽度方向上滑动的次数
D)Dilation分析
1.由于池化层的存在,响应张量的大小(长和宽)越来越小。
2.池化层去掉随之带来的是网络各层的感受野(receptive field)变小,这样会降低整个模型的预测精度。
3. Dilated convolution 的主要贡献就是,如何在去掉池化下采样操作的同时,而不降低网络的感受野。
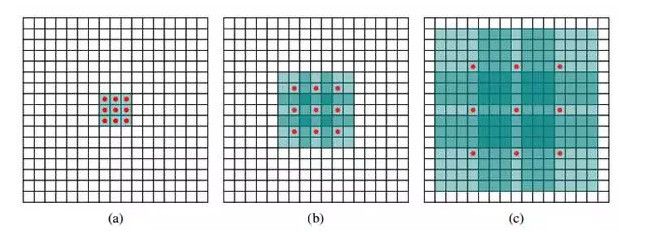
结合这个图再推倒一下output_h 和output_w的公式
Dilation :表示每个元素的相隔距离,如果相邻,dilation=1
运算公式: (除去原点的长度)×dilation(扩张系数)+ 1(原点)
即: kernel_h_new = (kernel_h-1)*dilation_h +1
kernel_w_new = (kernel_w-1)*dilation_w +1
E)im2col_cpu整体分析
F)Forward_cpu的整体分析
1. forward_cpu_gemm:
这个主要是处理处理Wx 的函数,里面分为两个步骤:
a)conv_im2col_cpu:将image转为矩阵
b) caffe_cpu_gemm: 将A中的矩阵和卷积核的矩阵相乘,得到特征图像的矩阵。
2. forward_cpu_bias:
这个主要是处理偏置数据。
G)Conv_layer的整体分析
1. Forward_cpu
2. Backward_cpu
F)BP流程
Backward_cpu函数的代码,整个更新过程大概可以分成三步
1. caffe_cpu_gemm(CblasTrans, CblasNoTrans, N_, K_, M_, (Dtype)1., top_diff, bottom_data, (Dtype)1., this->blobs_[0]->mutable_cpu_diff());
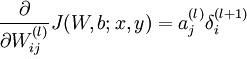
其中的bottom_data对应的是a,即输入的神经元激活值,维数为K_×N_,top_diff对应的是delta,维数是M_×N_,而caffe_cpu_gemm函数是对blas中的函数进行封装,实现了一个N_×M_的矩阵与一个M_×K_的矩阵相乘(注意此处乘之前对top_diff进行了转置)。相乘得到的结果保存于blobs_[0]->mutable_cpu_diff(),对应dW。
2. caffe_cpu_gemv(CblasTrans, M_, N_, (Dtype)1., top_diff, bias_multiplier_.cpu_data(), (Dtype)1., this->blobs_[1]->mutable_cpu_diff());

caffe_cpu_gemv函数实现了一个M_×N_的矩阵与N_×1的向量进行乘积,其实主要实现的是对delta进行了一下转置,就得到了db的值,保存于blobs_[1]->mutable_cpu_diff()中。此处的与bias_multiplier_.cpu_data()相乘是实现对M_个样本求和,bias_multiplier_.cpu_data()是全1向量,从公式上看应该是取平均的,但是从loss传过来时已经取过平均了,此处直接求和即可。
3.3 . caffe_cpu_gemm(CblasNoTrans, CblasNoTrans, M_, K_, N_, (Dtype)1., top_diff, this->blobs_[0]->cpu_data(), (Dtype)1., bottom[0]->mutable_cpu_diff());
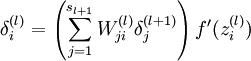
主要Inner_product层里面并没有激活函数,因此没有乘f’,与f’的相乘写在ReLU层的Backward函数里了,因此这一句里只有W和delta_l+1相乘。blobs_[0]->cpu_data()对应W,维度是N_×K_,bottom[0]->mutable_cpu_diff()是本层的delta_l,维度是M_×K_。
caffe里的反向传播过程只是计算每层的梯度的导,把所有层都计算完之后,在solver.cpp里面统一对整个网络进行更新。
先写到这里吧,学无止境,且学且记录。
END