(原文献链接:Arbitrary-Oriented Scene Text Detection via Rotation Proposals
Tags: 文本检测 旋转候选框 任意方向
摘要
本文介绍了一种新型的基于旋转的框架,用于自然场景图像中任意方向文本检测。 我们提出了旋转区域候选网络(RRPN),旨在生成具有文本方向角信息的倾斜候选框。然后,角度信息适用于边界框回归,使得候选框更准确地适应文本区域的方向。提出了旋转感兴趣区域(RRoI)池层将任意导向的建议投影到文本区域分类器的特征图。整个框架建立在基于区域提案的架构上,与以前的文本检测系统相比,确保了任意方向文本检测的计算效率。我们在三个现实世界的场景文本检测数据集中使用基于旋转的框架进行实验,并展示了其在以前方法方面的有效性和效率方面的优势。
1 介绍
文本检测是许多计算机视觉和文档分析问题的重要前提,其目的是识别给定图像的文本区域。虽然有一些商业OCR系统用于文件文本或互联网内容,但是由于照明不均匀,毛刺,透视变形,方向等困难的情况,自然场景图像中的文本检测是有挑战性的。
在过去的几年中,文本检测任务已经引起很多关注[3,22,7,35,23,1,15,12,13]。虽然这些方法已经显示出期望的结果,但大多数方法依赖于水平或近似水平的注释并返回水平区域的检测。然而,在现实世界的应用中,大量的文本区域不是水平的,即使应用非水平对齐的文本行作为轴对齐的候选框可能不准确,因此水平特定的方法不能被广泛应用在实践中。
近来,已经提出了一些工作来解决任意方向的文本检测[44,39,10]。一般来说,这些方法的任务主要包括两个步骤,如全卷积的分割网络(FCN),用于生成文本预测图和倾斜候选框的几何方法。然而,先决条件分割通常是耗时的。此外,一些系统需要几个后处理步骤来生成具有定向性的最终文本区域候选框,其不如基于直接检测网络那样高效。

图1:文本检测概览。第一行:基于水平边框的文本检测。第二行:使用旋转区域候选框进行检测。
在本文中,我们提出了一种基于旋转的方法和一种用于任意方向文本检测的端到端文本检测系统。特别地,结合方向,使得检测系统可以产生用于任意方向的候选框。以前的基于水平的方法与我们之间的比较如图1所示。我们提出了旋转区域候选网络(RRPN),其设计用于生成具有文本方向角信息的倾斜候选框。然后,角度信息适用于边界框回归,使候选框更准确地适应文本区域。提出了旋转感兴趣区域(RRoI)池化层将面向任意方向的候选框投影到特征图。最后,部署两层网络将区域分类为文本或背景。本文的主要贡献包括:
- 与以前的基于分割的框架不同,我们有能力使用基于候选区域的方法来预测文本行的方向,使得候选框可以更好地适应文本区域,并且可以容易地修正长文本区域,并且更方便文本阅读。
- 该框架将新的组件结合到基于候选区域的架构[8]中,与基于分割的文本检测系统相比,确保文本检测的计算效率。
- 我们还提出了以任意方向选择候选区域的新策略,以提高任意文本检测的性能。
- 我们在三个真实世界的文本检测数据集(即MSRA-TD500 [38],ICDAR2013 [19]和ICDAR2015 [18]上执行基于旋转的框架,发现它比以前的方法准确而且显着更有效。
2 相关工作
过去几十年来,自然场景文本的读取已经被研究,综合调查可以在[2,16,33,40]中找到。基于滑动窗口的方法,连接组件和自下而上的策略被设计为处理基于水平的文本检测。基于窗口的滑动方法[20,4,35,24,15]倾向于使用固定大小的滑动窗口来滑动文本区域,并找到最有可能存在文本的区域。为了考虑更多的文本存在风格,[15,36]将多尺度和多比例应用于滑动窗口方法。然而,滑动窗口的过程导致大的计算成本并且导致低效率。相关组件类似行程宽度变换(SWT)[7]和最大稳定极值区域(MSER)[22]的代表性方法在ICDAR 2011 [29]和ICDAR 2013 [19]强大的文本检测竞赛中处于领先地位。它们通过边缘检测或极端区域提取检测字符,然后将子MSER分量合并成一个单词或文本区域,主要集中在图像的边缘和像素点上。这些方法的努力在一些困难的情况下是有限的,例如多个连接的字符,分割笔画字符和不均匀的照明[43]。
自然场景文本通常与实际应用中的任何方向对齐,需要任意方向的方法。例如,[28]使用互相对称和渐变向量对称来识别文本候选像素,而不管包括自然场景图像的曲线的任何方向,以及[5]通过采用图像边缘和文本之间的相似性来设计Canny文本检测器来检测文本边缘像素和文本位置。最近,提出了基于卷积网络的方法来执行文本检测,例如Text-CNN [11],首先使用优化的MSER检测器来找到文本的近似区域,然后将区域特征发送到基于字符的水平文本CNN分类器进一步识别字符区域。 Yao等人在分割模型中采用方向因子[39]。他们的模型试图用明确的文本分割方式预测更准确的方向,并在ICDAR2013 [19],ICDAR2015 [18]和MSRA-TD500 [38]基准上表现出色。
类似于文本检测的技术都是通用对象检测。如果候选框数量大大降低,则检测过程可以更快。候选区域方法有各种各样的方法,如边框[46],选择搜索[34]和区域候选网络(RPN)[27]。例如,Jaderberg等 [13]扩展候选区域方法并应用边框方法[46]来执行文本检测。他们的文本识别系统在几个文本检测基准上取得了突出的成果。连接主义文本候选网络(CTPN)[32]也是通过采用LSTM CNN网络的图像特征来预测文本区域并生成鲁棒候选框的基于检测的场景文本检测框架。
这项工作的灵感来自于Fast-RCNN [8]和RPN检测流水线。RPN可以与Fast-RCNN框架相结合,进一步加快候选过程,并实现像ImageNet [6]等竞争对手的最先进的检测性能。这个想法也受到空间变压器网络(STN)的启发[14],这表明神经网络模型可以学习以角度来转换图像;这里我们尝试将角度信息添加到面向多个文本的检测模型中。也许与我们最相关的工作是[45],作者提出了Inception-RPN,并进行了进一步的文本检测特定优化来适应文本检测。与以前的作品相比,我们将旋转因素并入区域候选网络,以便能够生成面向任意方向的候选框。我们还将RoI池化层扩展到旋转RoI(RRoI)池化层,并在我们的框架中应用角度回归来执行整改过程,最终实现了非常好的结果。
3 方法
我们现在详细说明了以旋转为基础的框架的建设。该架构如图2所示;各阶段的细节将在以下部分进行描述。
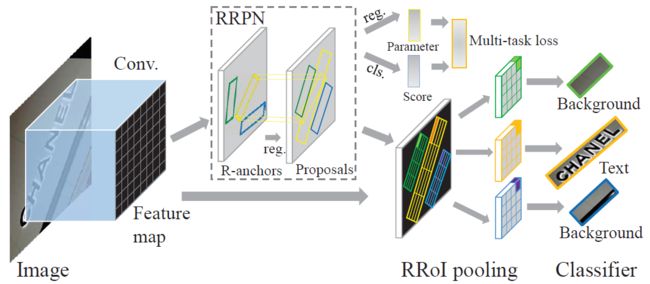
图2:基于旋转的文本检测流水线。
3.1 水平候选区域
如上节所述,RPN [27]能够进一步加快候选框生成过程。VGG-16 [30]的一部分被用作共享层,并且通过在最后的卷积层的特征图上滑动来生成水平候选区域。从每个滑动窗口提取的特征被馈送到两个兄弟层(边界框回归(reg)层和边界框分类(cls)层),其中存在4k个(每个候选框的4个坐标)来自reg层的表示坐标的输出, 2k个(每个候选框2个分数)来自cls层的每个滑动位置对应k个anchor的得分。
为了适应不同尺寸的对象,RPN使用两个参数来控制anchor的尺寸和形状,即尺度和纵横比。缩放参数决定anchor的大小,宽高比控制anchor框宽度和高度的比例。在[27]中,作者将尺寸设为8,16和32,比例为1:1,1:2和2:1,用于通用对象检测任务。这种anchor选择策略可以覆盖几乎所有自然对象的形状,并保留少数的候选框。然而,在文本检测任务中,特别是对于场景图像,文本通常以不自然的形状呈现,具有不同的方向;由RPN生成的轴对齐候选框对于场景文本检测不够鲁棒。为了使网络的文本检测更加强大并保持其效率,我们认为有必要建立一个将候选区域的旋转信息编码的检测框架。
3.2 建议架构
如图2所示,我们在框架的前面采用了VGG16 [30]的卷积层,它们由两个兄弟分支共享,即RRPN和最后一个卷积层的特征图的克隆。RRPN为文本实例生成面向任意方向的候选框,并进一步对候选框进行边界框回归,以更好地适应文本实例。从RRPN分支的兄弟层分别是RRPN的分类层(cls)和回归层(reg)。这两个层输出是来自cls的分数和reg的候选框信息,它们的损失被计算并求和以形成多任务损失。然后最大池化的RRoI池化层通过将任意方向的文本候选框从RRPN投影到特征图上。最后,使用由两个全连接层形成的分类器,将具有RRoI特征的区域分类为文本或背景。
3.3 数据预处理
在训练阶段,一个文本区域的ground truth被表示为具有5个元组($x,y,h,w,\theta$)的旋转边界框,坐标($x,y$)表示边界框的几何中心。高度h设定为边框的短边,宽度w为长边,方向是长边的方向。我们将范围修改为($-\frac{\pi}{4},\frac{3\pi}{4}$),如果角度超出该范围,则通过向相反方向移动。
3.4 旋转anchor
使用尺度和宽高比参数的传统anchor不足以进行自然场景文本检测,因此我们通过多次调整设计旋转anchor(R-anchor)。首先,添加方向参数以控制候选框的方向。使用六个不同的方向,即$-\frac{\pi}{6},0,\frac{\pi}{6},\frac{\pi}{3},\frac{\pi}{2}$和$\frac{2\pi}{3}$,它们在方向覆盖和计算效率之间进行权衡。第二,由于文字区域通常具有特殊的形状,因此宽高比为1:2,1:5和1:8以覆盖广泛的文字行。此外,保留8,16和32的尺寸。anchor策略的总结如图3所示。在我们的数据预处理步骤之后,从具有5个变量($x,y,h,w,\theta$)的R-anchor生成一个候选框。对于特征图上的每个点,产生54个R-anchor($6\times3\times3$),并且在每个滑动位置分别产生用于reg层的270个输出($5\times54$)和用于cls层的108个输出($2\times54$)。然后,我们使用RRPN滑动特征图,为宽度为W和高度为H的特征图生成总共$H\times W\times54$个anchor。
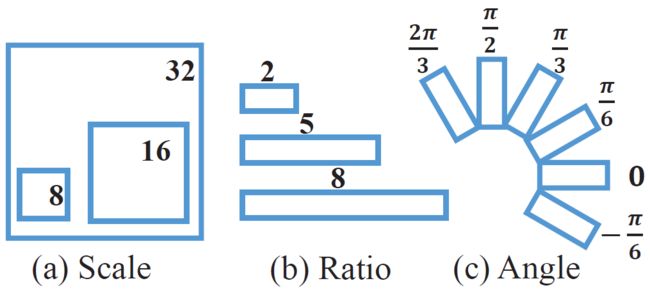
图3:我们框架中的anchor策略。
3.5 旋转候选框的学习
随着R锚点生成,网络学习需要R-anchor的采样策略。我们首先将交并比(IoU)重叠定义为ground truth和R-anchor的倾斜矩形之间的重叠。然后,正样本R-anchor具有以下特征:(i) 与ground truth有最大的IoU重叠或IoU大于0.7,以及(ii) 与ground truth的交叉角小于$\frac{\pi}{12}$。负样本R-anchor定义为:(i) IoU低于0.3,或(ii) IoU大于0.7,但与ground truth的交叉角大于$\frac{\pi}{12}$。训练期间不使用非正样本或非负样本的区域。
我们对该候选框的损失函数采用多任务损失的形式[8],其定义如下:$$L(p,l,v^,v)=L_{cls}(p,l)+\lambda lL_{reg}(v^,v)\qquad(1)$$其中$l$是类标签的指示符(对于文本$l=1$,背景$l=0$,背景无回归),参数$p=(p_0,p_1)$是由softmax函数计算的类的概率,$v=(v_x,v_y,v_h,v_w,v_{\theta})$表示文本标签的预测元组,$v*=(v_x,v^y,v*_h,v_w,v^{\theta})$表示为ground truth。两个术语之间的权衡由平衡参数控制。我们将类别$l$的分类损失定义为:$$L{cls}(p,l)=-\log p_l\qquad(2)$$对于边界回归,背景RoIs被忽略,我们对文本RoI采用平滑$L_1$损失:$$L{reg}(v*,v)=\sum_{i\in{x,y,h,w,\theta}}smooth_{L_1}(vi-v_i)\qquad(3)$$ $$smooth{L_1}(x)=\left{\right.{0.5x2\qquad if|x|<1}_{|x|-0.5\quad otherwise}\qquad(4)$$尺度不变参数化元组$v$和$v^$计算如下:$$v_x=\frac{x-x_a}{w_a},v_y=\frac{y-y_a}{h_a}$$$$v_h=\log\frac{h}{h_a},v_w=\log\frac{w}{w_a},v_{\theta}=\theta\ominus\theta _a\qquad(5)$$$$v*_x=\frac{x-x_a}{w_a},v^_y=\frac{y*-y_a}{h_a}$$$$v_h=\log\frac{h^}{h_a},v*_w=\log\frac{w}{w_a},v^_{\theta}=\theta^\ominus\theta _a\qquad(6)$$其中$x$,$x_a$和$x^$ 是为预测的框,anchor和ground truth框;对于$y$,$h$,$w$和$\theta$是相同的。操作$a\ominus b=a-b+k\pi$,$k\in Z$确保$a\ominus b\in[-\frac\pi4,\frac{3\pi}{4})$。正如我们在前面的部分所描述的那样,我们给出R-anchor固定方位在$[-\frac\pi4,\frac{3\pi}{4})$,并且6个方向中的每一个可以拟合具有小于$\frac{\pi}{12}$的交点角度的ground truth,使得每个R-anchor具有其拟合范围,我们称之为拟合域。当ground truth框的方向位于R-anchor的拟合域中时,该R-anchor很可能是ground truth框的正样本。因此,6个方向的拟合域将角度范围$[-\frac\pi4,\frac{3\pi}{4})$分成6等份。因此,任何方向的ground truth都可以匹配拟合域的R-anchor。图5显示了回归项的效用的比较。我们可以观察到,在邻近区域,区域的方向是相似的。

图4:可视化不同的多任务损失值。方向是每个点上白线的方向,较长的线表示文本的较高响应分数。(a)输入图像;(b)0次迭代;(c)15,000次迭代;(d)15万次迭代。

图5:可视化回归的影响。(a) 输入图像; (b)没有回归anchor的方向和响应; (c) 有回归anchor的方向和响应。
为了验证网络学习文本区域方向的能力,我们在图4中可视化了中间结果。对于输入图像,可视化不同迭代后RRPN训练的特征图。特征图上的短白线表示对文本实例的响应最高的R-anchor。短线的方向是该R-anchor的取向,短线长度表示响应的水平。我们可以观察到,特征图的更亮的区域集中在文本区域,其他区域在15万次迭代后变得更暗。此外,随着迭代的增加而增加这些区域的方向变得更接近文本实例的方向。
3.6 准确的候选框精修
${\bf 倾斜IoU计算}$。旋转候选框可以以任何方向生成,因此在轴对齐候选框上的IoU计算可能导致倾斜相交的候选框的IoU计算错误,并进一步破坏了候选框学习。如算法1所示,我们设计了一个用于三角测量的倾斜IoU计算的实现[25],图6显示了几何原理。

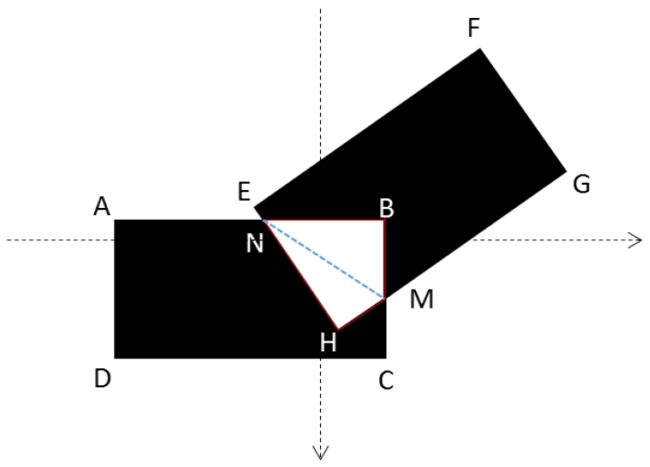
图6:任意方向的两个矩形的交叉区域计算。 首先将交点N,M和内部顶点H,B添加到PSet中,对PSet进行排序以获得凸多边形NHMB,然后计算交叉区域$S_{NHMB} = S_{\Delta NHM} + S_{\Delta NMB}$
${\bf倾斜非极大值抑制(Skew-NMS)}$。传统NMS只考虑IoU因子(例如IoU阈值为0.7),但是对于任意方向的候选框是不够的。例如,比例1:8和角度差$\frac{\pi}{12}$的锚点的IoU为0.31,小于0.7;然而,它可能被注释为正样本。因此,Skew-NMS由两个阶段组成:(i)保留IoU大于0.7中IoU最大的候选框;(ii)如果所有候选框的IoU范围在[0.3,0.7]内,保留与ground truth最小角度差的候选框(角度差应小于$\frac{\pi}{12}$)。
3.7 RRoI池化层
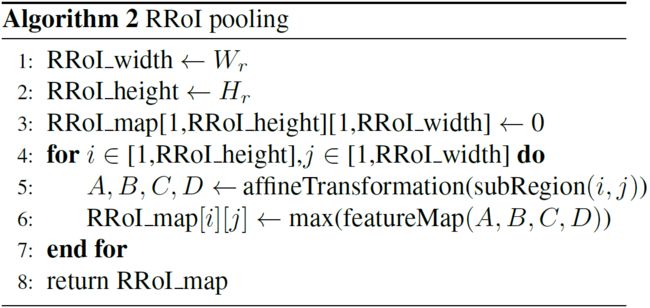
如Fast-RCNN[8]所示,RoI池化层从每个候选框的特征图中提取固定长度的特征向量。每个特征向量被馈送到全连接层,最终分支送到兄弟层cl和reg,并且输出是对输入图像中对象的位置和类别的预测。由于每个图像仅需要计算一次特征图,而不需要计算每个生成的候选框,所以对象检测框架被加速。RoI池化层使用最大池化来将任何有效的RoI内的特征转换为具有固定的空间尺寸$h_r\times w_r$的小特征图,其中$h_r$和$w_r$是独立于任何RoI层的超参数。
对于任意方向的文本检测任务,传统的RoI池化层只能处理轴对齐的候选框,因此我们提出了旋转RoI(RRoI)池化层来调整RRPN生成的面向任意的候选框。我们首先将RRoI层超参数设置为$H_r$和$W_r$,旋转的候选区域可以将具有高度$h$和宽度$w$的候选框划分为$H_r\times W_r$个大小为$\frac{h}{ H_r}\times\frac{w}{W_r}$子区域(如图7(a)所示);每个子区域的方向与候选框相同。图7(b)示例了该特征图上具有4个顶点(A,B,C和D)的子区域。使用仿射变换计算4个顶点,并将其分组以区分子区域的边界。然后在每个子区域执行最大池化,最大池化值保存在每个RRoI的矩阵中; RRoI池化伪代码显示在算法2中。与RoI池化相比,RRoI池化可以将任何具有各种角度、宽高比或尺寸的区域池化为一个固定大小的特征图。最后,将候选框转移到RRoI中,并送到分类器中以获得是文本或是背景的结果。

图7:RRoI池化层:(a)将任意方向的候选框划分为子区域;(b)从一个倾斜候选框到RRoI中的一点最大池化单个区域。
4 试验
我们在三个流行的文本检测基准上执行基于旋转的框架系统:MSRA-TD500[38],ICDAR2015[18]和ICDAR2013[19];我们遵循这些基准的评估方案。MSRA-TD500数据集包含300个训练图像和200个测试图像。图像的注释由每个文本实例的位置和方向组成,并且基准可用于评估面向多文本实例上的文本检测性能。由于MSRA-TD500的数据集相对较小,因此其实验利用了交叉设置。ICDAR 2015 Robust Reading Competition中发布了用于附带场景文本挑战(任务4.1)的文本定位的ICDAR 2015,共有1500张图像。与以前的ICDAR Robust Reading Competition不同,文本实例注释具有四个顶点,形成一个不规则的带有方向信息的四边形边框。我们粗略地生成一个倾斜的矩形以适应四边形及其方向。ICDAR 2013数据集来自“ICDAR 2013 Robust Reading Competition”。有229个自然图像用于训练和233个自然图像进行测试。该数据集中的所有文本实例都是水平对齐的,我们对这个横向基准进行实验,以了解我们的方法对特定方向的适应性。
${\bf实施细节}$。我们的网络通过ImageNet分类模型的预训练进行初始化[30]。然后设置前200,000次迭代中学习率为$10{-3}$,在接下来的100,000次迭代中学习率为$10{-4}$,权重衰减为$5\times10^{-4}$,动量项为0.9,来更新网络的权重。
由于我们不同的R-anchor策略,每个图像的候选框总数几乎是先前方法(如Faster-RCNN)的6倍。为了进行有效的检测,我们过滤了破坏图像边界的R-anchor。因此,我们系统的速度与以前在训练和测试阶段的工作相似。
4.1 MSRA-TD500
我们使用MSRA-TD500训练集的300幅图像训练基准系统;输入图像补丁的长边尺寸为1000像素。评估结果是精确度为57.4%,回归率为54.5%,F值为55.9%,性能优于原来的P,R和F为38.7%,30.4%和34.0%的Faster-RCNN。我们在旋转和水平区域候选框之间做了比较,一些检测结果如图8所示。基于旋转的方法能够实现具有较少的背景区域的准确检测,这表明并入旋转策略的有效性。
图8:旋转和水平候选区域的比较。第一行:原始图像;第二行:基于水平候选区域的文本检测;第三行:基于旋转候选区域的文本检测。
对基准结果的进一步分析给出以下见解:(i)图像中的复杂情况(例如,模糊和不均匀照明)几乎不能被检测到;(ii)一些极小尺寸的文本实例无法正确检测到,而且这个问题导致大量性能召回损失;(iii)非常长的文本行,即高宽比大于1:10的边框,无法正确检测,通常被分为几个较短的候选框,导致在MSRA-TD500评估下所有候选框检测出错(一些失败的检测如图9所示)。测试了基准方法中的一些交叉策略和设置,并将总结列在表1中。

图9:MSRATD500错误检测示例。红色框是检测结果,绿色框是ground truth。
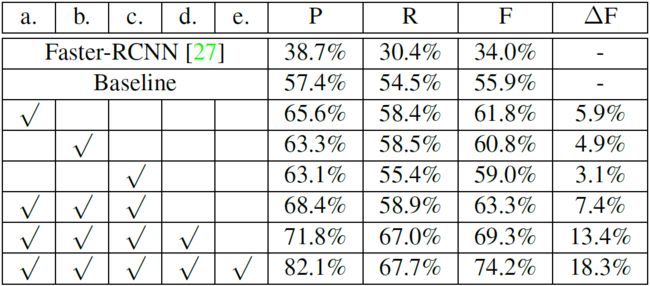
表1:在不同策略和设置的MSRA-TD500上进行评估。Faster-RCNN的实验基于原始源代码。P,R和F分别是Precision,Recall和F-measure的缩写。$\Delta F$是基准线上F-measure的改善。策略包括:a.文本区域的上下文;b. 扩大训练数据集;C.边界填充;d.规模抖动;e.后处理。
${\bf文本区域上下文}$。证明了将上下文信息合并到一般对象检测任务中是有用的(例如,[26]),并且我们想知道它是否可以促进文本检测系统。我们保留旋转边界框的中心和方向,并在数据预处理步骤上设置宽度和高度放大倍数为1.X。在测试阶段,我们扩大每个候选框的划分。如表2所示,所有实验的F-measure均显著提高了。原因可能是随着边框越来越大,掌握了文本实例的更多上下文信息,可以更好地捕获方向信息,从而更准确地预测候选框的方向。
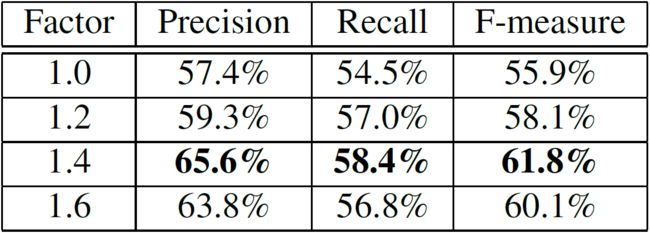
表2:通过扩大具有不同原始大小因素的文本边界框来利用文本区域上下文。
${\bf扩大训练数据集}$。我们采用HUSTTR400(包含400个图像,带有与MSRA-TD500相同的参数注释的文本实例)[37]作为附加数据集,并从两个数据集中组成700个图像的训练集。所有测量值都有显著改善,F度量值为60.8%,表明在处理噪声输入时,网络训练更好,更强大。
${\bf边框填充}$。通过我们的过滤策略,大部分破解的R-anchor都被消除。然而,当边框旋转某个角度时,它可能仍然超过图像边界,特别是当我们放大上下文信息的文本区域时。因此,我们设定了每边0.25倍的边界填补,以保留更多正样本候选框。实验表明,添加图像边框填充可以提高检测结果。此外,边界填充与文本区域扩展和训练数据集的结合进一步改善F-measure,提高到63.3%。
${\bf尺寸抖动}$。在训练数据集中仍然有一些小文本区域,为了系统的稳健性,我们增加了尺寸抖动。图像补丁用长边小于1300像素的随机尺寸重新缩放,然后送到网络中。基于尺度抖动的F-measure为69.3%,比没有抖动的实验提高了6%。
${\bf后处理}$。MSRA-TD500的注释优先标记整个文本行的区域。因此,文本行的长度不是固定的范围,有时候很长。然而,R-anchor的比率是固定的,并且可能不足以覆盖所有长度,这导致单个文本区域的几个短边界框结果。为了处理这个非常长的文本行问题,在后处理过程中将邻近区域中的多个短检测框组合到一个候选框。随着后处理,性能进一步提升,F-measure为74.2%。
4.2 ICDAR基准
${\bf ICDAR 2015}$。按照MSRA-TD500评估的策略和参数,我们用ICDAR2015的训练数据集训练基准系统,其中包含1000张具有10886个文本实例的图像。评估结果为精确率为45.42%,召回率为72.56%,F-measure为55.87%。
由于MSRA-TD500倾向于提供文本行ground truth,而ICDAR是字级注解,所以我们的方法的精度要低于达到相同幅度F-measure的其他方法。我们分析文本检测结果,找到三个原因。首先,即使我们使用尺寸抖动策略调整图像的大小,一些附带的文本区域仍然太小。第二,在ICDAR2015训练集中存在一些小的不可读的文本实例(标有“###”)(有些如图10所示),这可能导致文本样例的一些错误的检测结果。最后,我们的训练数据集远远小于以前的方法,如[39,32,44]。

图10:ICDAR2015中的文本检测,其模型训练于ICDAR2015训练集上(包括所有不可读的文本实例)。绿色区域是IoU>0.5的正样本检测,红色区域表示错误检测。
为了处理小文本区域问题,我们在送到网络之前,通过以长边小于1700像素的随机大小抖动的图像块来进行更大规模化。我们还通过从训练集中随机删除这些实例来检查小型不可读文本实例的影响。图11显示了测量的曲线。除非我们删除所有不可读的实例,否则召回率保持在72%-73%左右,而精确度则以比例显著增加。因此,我们在训练集上随机删除80%不可读的文本实例,并保留整个测试集。为了进一步改进我们的检测系统,我们结合了一些用于训练的文本数据集,即ICDAR2013[19],ICDAR2003[21]和SVT[35]。如表3所示,不同方法的训练图像处于同一数量级,我们实现更好的性能。

图11:对训练集的不可读文本实例部分使用交叉验证的效果。横轴表示不可读文本实例的删除部分,纵轴表示F-measure的百分比。

表3:ICDAR2015的训练集和结果。Ixx表示ICDAR20xx训练集;M500表示MSRATD500,CA表示由[32]的作者收集的数据。
${\bf ICDAR 2013}$。为了检验我们的方法的适应性,我们还对水平的ICDAR 2013基准进行实验。我们重新使用在ICDAR 2015上训练的模型,并且5元组的旋转候选框匹配水平对齐的矩形。结果是ICDAR 2013评估方案的精度为90.22%,召回率为71.89%,F-measure为80.02%。如表4所示,与Faster-RCNN相比,提高了7%,这证实了我们的检测框架与旋转因子的稳健性。

表4:三个基准的state-of-the-art的比较。[45]给出了Faster-RCNN在ICDAR2013上结果。
4.3 与State-of-the-art比较
我们的方法与现有技术方法相比较的实验结果如表4所示。同基于MSRA-TD500和ICDAR分别对RRPN模型进行训练一样,针对一般化问题,我们还在所有数据集上训练了一个标准模型。对于MSRA-TD500数据集,我们的RRPN的性能达到了state-of-the-art等级,如同[39]和[44]。由于我们的系统进行端到端的文本检测,每张测试图像处理时间只有0.3秒,比其他的系统更有效率。对于ICDAR基准,实质性能增益大于已发布的作品证实了使用旋转候选区域和旋转RoI进行文本检测任务的有效性。最近的DeepText[45]工作也是基于检测的方法,但是基于Inception结构。我们相信,我们的基于旋转的框架也是对Inception的补充,因为它们专注于不同级别的信息。基准测试中的一些检测结果如图12所示。
图12:基准上的文本检测结果
5 总结
在本文中,我们引入了一种面向任意方向文本检测的基于旋转的检测框架。从网络的较高卷积层生成倾斜的带有文本区域方向角信息的矩形候选框,其能够用于检测多方位的文本。还设计了一种新颖的RRoI池化层,适用于旋转的RoIs。通过与MSRA-TD500,ICDAR2013和ICDAR2015上的state-of-the-art的实验比较,证明了提出的RRPN和RRoI对文本检测任务的有效性和效率。
参考文献
[1] A. Bissacco, M. Cummins, Y. Netzer, and H. Neven. Photoocr: Reading text in uncontrolled conditions. In ICCV, pages 785–792, 2013. 1
[2] D. Chen and J. Luettin. A survey of text detection and recognition in images and videos. Technical report, 2000. 2
[3] X. Chen and A. L. Yuille. Detecting and reading text in natural scenes. In CVPR, pages 366–373, 2004. 1
[4] X. Chen and A. L. Yuille. Detecting and reading text in natural scenes. In CVPR, volume 2, pages II–366, 2004. 2
[5] H. Cho, M. Sung, and B. Jun. Canny text detector: Fast and robust scene text localization algorithm. In CVPR, 2016. 2
[6] J. Deng,W. Dong, R. Socher, L. Li, K. Li, and L. Fei-Fei. ImageNet: A large-scale hierarchical image database. In CVPR, 2009. 2
[7] B. Epshtein, E. Ofek, and Y.Wexler. Detecting text in natural scenes with stroke width transform. In CVPR, 2010. 1, 2
[8] R. Girshick. Fast r-cnn. In ICCV, 2015. 2, 4, 5
[9] A. Gupta, A. Vedaldi, and A. Zisserman. Synthetic data for text localisation in natural images. In CVPR, pages 2315–2324, 2016. 8
[10] T. He, W. Huang, Y. Qiao, and J. Yao. Accurate text localization in natural image with cascaded convolutional text network. arXiv preprint arXiv:1603.09423, 2016. 1
[11] T. He, W. Huang, Y. Qiao, and J. Yao. Text-attentional convolutional neural network for scene text detection. IEEE Trans. IP, 25(6):2529–2541, 2016. 2
[12] W. Huang, Y. Qiao, and X. Tang. Robust scene text detection with convolution neural network induced mser trees. In ECCV, pages 497–511, 2014. 1
[13] M. Jaderberg, K. Simonyan, A. Vedaldi, and A. Zisserman. Reading text in the wild with convolutional neural networks. IJCV, 116(1):1–20, 2014. 2
[14] M. Jaderberg, K. Simonyan, A. Zisserman, and k. kavukcuoglu. Spatial transformer networks. In NIPS, pages 2017–2025, 2015. 2
[15] M. Jaderberg, A. Vedaldi, and A. Zisserman. Deep features for text spotting. In ECCV, pages 512–528, 2014. 1, 2
[16] K. Jung, K. I. Kim, and A. K. Jain. Text information extraction in images and video: a survey. Pattern Recognition, 37(5), 2004. 2
[17] L. Kang, Y. Li, and D. Doermann. Orientation robust text line detection in natural images. In CVPR, 2014. 8
[18] D. Karatzas, L. Gomez-Bigorda, A. Nicolaou, et al. Icdar 2015 competition on robust reading. In ICDAR, pages 1156–1160, 2015. 2, 5
[19] D. Karatzas, F. Shafait, S. Uchida, et al. Icdar 2013 robust reading competition. In ICDAR, 2013. 2, 5, 7
[20] K. I. Kim, K. Jung, and J. H. Kim. Texture-based approach for text detection in images using support vector machines and continuously adaptive mean shift algorithm. IEEE Trans. PAMI, 25(12):1631–1639, 2003. 2
[21] S. M. Lucas, A. Panaretos, L. Sosa, A. Tang, S. Wong, and R. Young. ICDAR 2003 robust reading competitions. In ICDAR, 2003. 7
[22] J. Matas, O. Chum, M. Urban, and T. Pajdla. Robust widebaseline stereo from maximally stable extremal regions. Image & Vision Computing, 22(10):761–767, 2004. 1, 2
[23] L. Neumann and J. Matas. A method for text localization and recognition in real-world images. In ACCV, 2010. 1
[24] L. Neumann and J. Matas. Scene text localization and recognition with oriented stroke detection. In ICCV, 2013. 2
[25] D. A. Plaisted and J. Hong. A heuristic triangulation algorithm. Journal of Algorithms, 8(3):405–437, 1987. 4
[26] J. Redmon, S. Divvala, R. Girshick, and A. Farhadi. You only look once: Unified, real-time object detection. In CVPR, 2016. 7
[27] S. Ren, K. He, R. Girshick, and J. Sun. Faster r-cnn: Towards real-time object detection with region proposal networks. IEEE Trans. PAMI, 2016. 2, 3, 6, 8
[28] A. Risnumawan, P. Shivakumara, C. S. Chan, and C. L. Tan. A robust arbitrary text detection system for natural scene images. Expert Systems with Applications, 41(18):8027–8048, 2014. 2
[29] A. Shahab, F. Shafait, and A. Dengel. Icdar 2011 robust reading competition challenge 2: Reading text in scene images. In ICDAR, pages 1491–1496, 2011. 2
[30] K. Simonyan and A. Zisserman. Very deep convolutional networks for large-scale image recognition. In ICLR, 2015. 2, 3, 6
[31] S. Tian, Y. Pan, C. Huang, S. Lu, K. Yu, and C. L. Tan. Text flow: A unified text detection system in natural scene images. In ICCV, 2015. 1
[32] Z. Tian, W. Huang, T. He, P. He, and Y. Qiao. Detecting text in natural image with connectionist text proposal network. In ECCV, pages 56–72, 2016. 2, 7, 8
[33] S. Uchida. Text localization and recognition in images and video. In Handbook of Document Image Processing and Recognition, pages 843–883. 2014. 2
[34] J. R. R. Uijlings, K. E. A. V. D. Sande, T. Gevers, and A.W. M. Smeulders. Selective search for object recognition. IJCV, 104(2):154–171, 2013. 2
[35] K. Wang and S. Belongie. Word spotting in the wild. In ECCV, pages 591–604, 2010. 1, 2, 7
[36] T.Wang, D. J.Wu, A. Coates, and A. Y. Ng. End-to-end text recognition with convolutional neural networks. In ICPR, pages 3304–3308, 2012. 2
[37] C. Yao, X. Bai, and W. Liu. A unified framework for multioriented text detection and recognition. IEEE Trans. IP, 23(11):4737–49, 2014. 7, 8
[38] C. Yao, X. Bai, W. Liu, Y. Ma, and Z. Tu. Detecting texts of arbitrary orientations in natural images. In CVPR, pages 1083–1090, 2012. 2, 5
[39] C. Yao, X. Bai, N. Sang, X. Zhou, S. Zhou, and Z. Cao. Scene text detection via holistic, multi-channel prediction. arXiv preprint arXiv:1606.09002, 2016. 1, 2, 7, 8
[40] Q. Ye and D. Doermann. Text detection and recognition in imagery: A survey. IEEE Trans. PAMI, 37(7):1480–1500, 2015. 2
[41] X. C. Yin, W. Y. Pei, J. Zhang, and H. W. Hao. Multiorientation scene text detection with adaptive clustering. IEEE Trans. PAMI, 37(9), 2015. 8
[42] X. C. Yin, X. Yin, K. Huang, and H. W. Hao. Robust text detection in natural scene images. IEEE Trans. PAMI, 36(5):970–83, 2014. 8
[43] S. Zhang, M. Lin, T. Chen, L. Jin, and L. Lin. Character proposal network for robust text extraction. In ICASSP, pages 2633–2637, 2016. 2
[44] Z. Zhang, C. Zhang, W. Shen, C. Yao, W. Liu, and X. Bai. Multi-oriented text detection with fully convolutional networks. In CVPR, 2016. 1, 7, 8
[45] Z. Zhong, L. Jin, S. Zhang, and Z. Feng. Deeptext: A unified framework for text proposal generation and text detection in natural images. arXiv preprint arXiv:1605.07314, 2016. 2, 8
[46] C. L. Zitnick and P. Doll´ar. Edge boxes: Locating object proposals from edges. In ECCV, pages 391–405, 2014. 2