感谢Robert I.Kabacoff 著作本书,同时感谢高涛、肖楠、陈钢编译此书。
最近在学习《R语言实战》,特将学习过程记录下来,供各位朋友参考,虽说是笔记,但是90%是书中内容,另外10%是自己偶尔冒出的一点点想法的记录和一些疑问,希望互相探讨。末尾有本章的代码清单下载地址,与各位交流,还是提倡按照书中内容把代码一个个敲出来。
第六章 基本图形
本章内容
条形图、箱线图和点图
饼图和扇形图
直方图与核密度图
6.1 条形图
条形图通过水平或垂直的条形展示了类别型变量的分布(频率)函数函数barplot()的最简单用法是:
barplot(height)
其中height是一个向量或一个矩阵。(问:数据框不可以吗?亲测,不可以,会有错误提示。)
6.1.1 一个简单的条形图
载入vcd包之前,需要载入grid包。
小提示
若要绘制的类别型变量是一个因子或有序型因子,就可以使用函数plot()快速创建一幅垂直条形图。由于Arthritis$Improved是一个因子,所以代码:
plot(Arthritis$Improved, main = "Simple Bar Plot", xlab = "Improved", ylab = "Frequency")
plot(Arthritis$Improved, horiz = TRUE, main = "Horizontal Bar Plot", xlab = "Frequency", ylab = "Improved")
6.1.2 堆砌条形图和分组条形图
如果hight是一个矩阵而不是一个向量,则绘图结果将是一幅堆砌条形图或分组条形图。若beside=FALSE(默认),则矩阵中的每一列将都将生产图中的一个条形,各列中的值将给出堆砌的“子条”的高度。若beside=TRUE,则矩阵中的每一了都表示一个分组,各列中的值将并列而不是堆砌。
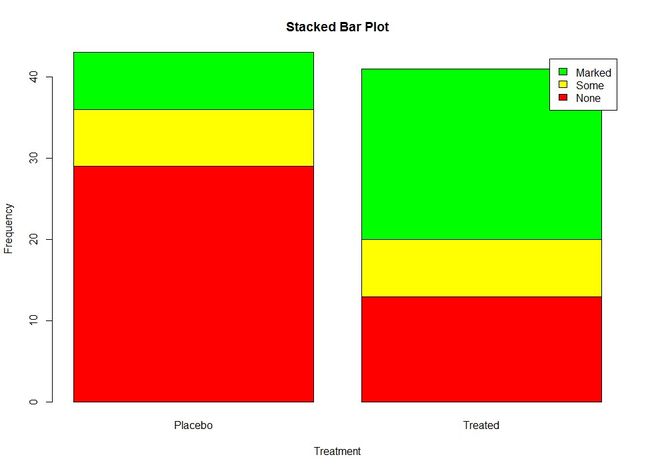
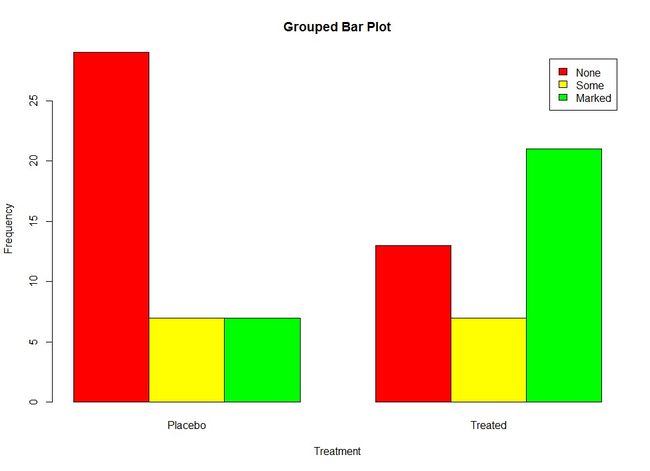
6.1.3 均值条形图
条形图并不一定要基于计数数据或频率数据。你可以使用数据整合函数并将结果传递给barplot()函数,来创建表示均值、中位数、标准差等的条形图。
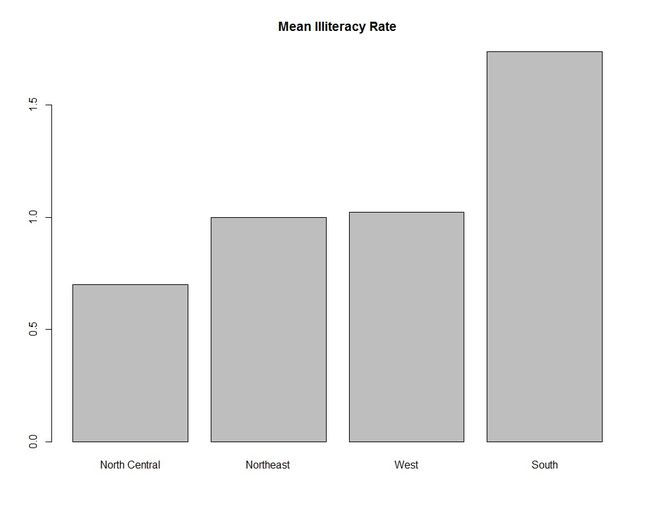
6.1.4 条形图的微调
有若干种方式可以微调条形图的外观。例如,随着条数的增多,条形的标签可能会开始重叠,你可以使用参数cex.names来减小字号。将其指定为小于1的值可以缩小标签的大小。可选的参数names.arg允许你指定一个字符向量作为条形的标签名。
6.1.5 棘状图
在结束官途条形图的讨论之前,让我们再来看一种特殊的条形图,它被称为棘状图(spinogram)。棘状图对堆砌条形图进行了重缩放,这样每个条形的高度为1,每一段的高度即表示比例。棘状图可由vcd包中的函数spine()绘制。
6.2 饼图
由函数pie()创建,代码如下:
pie(x, labls)
饼图让比较各扇形的值变得困难(除非这些值被附加在标签上)。因此出现了一种扇形图,为用户提供了一种同时展示相对数量和相互差异的方法。通过plotrix包中的fan.plot()函数实现。特点是以同一起点开始,分别展示不同扇形,可以理解为:按照从小到大的顺序,分别从前往后绘制图形。在这里扇形的宽度(width)是重要的,半径并不重要。
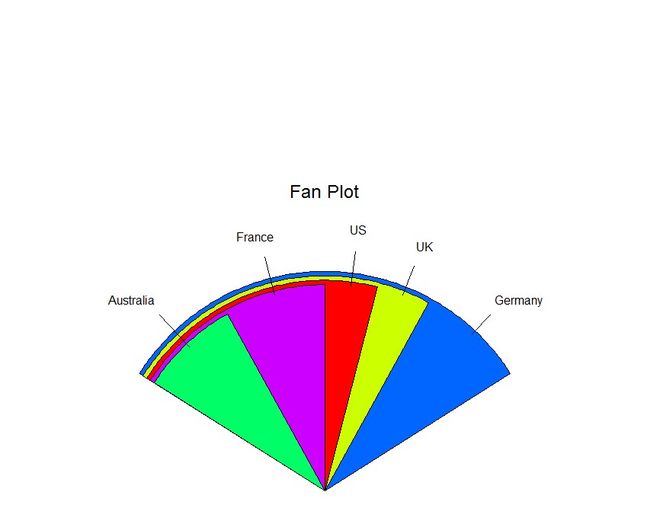
6.3 直方图
与条形图和饼图不同,直方图描述的是连续型变量的分布。直方图是通过X轴上将值域分割为一定数量的组,在Y轴上显示相应值得频数,展示了连续型变量的分布。使用如下代码创建直方图。
hist(x)
其中的X是一个由数据值组成的数值向量。参数freq=FALSE表示根据频率密度而不是频数绘制图形。参数breaks用于控制组的数量。
代码清单6-6 直方图
par(mfrow = c(2,2))
hist(mtcars$mpg)
hist(mtcars$mpg, breaks = 12, col = "red", xlab = "Miles Per Gallon", main = "Colored histogram with 12 bins")
hist(mtcars$mpg, freq = FALSE, breaks = 12, col = "red", xlab = "Miles Per Gallon", main = "Histogram ,rug plot, density curve")
rug(jitter(mtcars$mpg))
lines(density(mtcars$mpg))
lines(density(mtcars$mpg), col = "blue", lwd = 2)
x <- mtcars$mpg
h <- hist(x, breaks = 12, col = "red", xlab = "Miles Per Gallon", main = "Histogram with normal curve and box")
xfit <- seq(min(x), max(x), length = 40)
yfit <- dnorm(xfit, mean = mean(x), sd = sd(x))
yfit <- yfit*diff(h$mids[1:2])*length(x)
lines(xfit, yfit, col = "blue", lwd = 2)
box()
第一幅直方图展示了未指定任何选项是的默认图形。第二幅将组数指定为12,使用红色填充条形,并添加了标签和标题。
第三幅直方图保留了上一幅图中的颜色、组数、标签和标题设置,又叠加了一条密度曲线和轴须图。这条密度曲线是一条核密度估计,它为数据的分布提供了一种更加平滑的描述。再使用lines()函数叠加了这条蓝色、双倍默认线条宽度的曲线。最后,轴须图是实际数据的一种一维呈现方式。如果数据中有许多结,你可以使用如下代码将轴须图的数据打散:
rug(jitter(mtcars$mpg, amount = 0.01))
这样将向每个数据点添加一个小的随机值(一个±amount之间的均匀分布随机数),以避免重叠的点产生影响。
第四幅直方图与第二幅类似,只是拥有一条叠加在上面的正太曲线和一个将图形围绕起来的盒形。
6.4 核密度图
用术语来说,核密度估计是用于估计随机变量概率密度函数的一种非参数方法。核密度图不失为一种用来观察连续型变量分布的有效方法。不叠加到另一幅图上方绘制密度图的方法为:
plot(density(x))
其中x是一个数值型向量。若要在一幅已经存在的图形上叠加一条密度曲线,可以使用:
lines(density(x))
使用sm包中的sm.density()函数可向图形叠加两组或更多的核密度图。使用格式为:
sm.density.compare(x, factor)
其中的x是一个数值型向量,factor是一个分组变量。
6.5 箱线图
箱线图(又称盒须图)通过绘制连续型变量的五数总括,即最小值、下四分位数(第25百分位数)、中位数(第50百分位数)、上四分位数(第75百分位数)以及最大值,描述了连续型变量的分布。箱线图能够显示出可能为离群点(范围在±IQR以外的值,IQR表示四分位距,即上四分位数与下四分位数的差值)的观测。
boxplot(mtcars$mpg,main = "Box plot", ylab = "Mles per Gallon")
6.5.1 使用并列箱线图进行跨组比较
箱线图可以展示单个变量或分组变量。使用格式为:
boxplot(formula, data = dataframe)
其中对的formula是一个公式,dataframe代表提供数据的数据库(或列表)。一个示例公式为y ~ A,这将为类别型变量A的每个值并列地生成数值型变量y的箱线图。公式y ~ A*B则将为类别型变量A和B所有水平的两两组合生成数值型变量y的箱线图。
箱线图灵活多变,通过添加notch=TRUE。可以得到含凹槽的箱线图。若两个箱的凹槽互不重叠,则表明他们的中位数有显著差异。
6.5.2 小提琴图
小提琴图示箱线图和核密度图的结合。首次使用需要下载安装vioplot包。使用格式为:
Vioplot(x1, x2, …, names = , col = )
其中x1,x2,…表示要绘制的一个或多个数值向量(将为每个向量绘制一幅小提琴图)。参数names是小提琴图中标签的字符向量,而col是一个为每幅小提琴图指定颜色的向量。(注意:每个参数都是向量。)
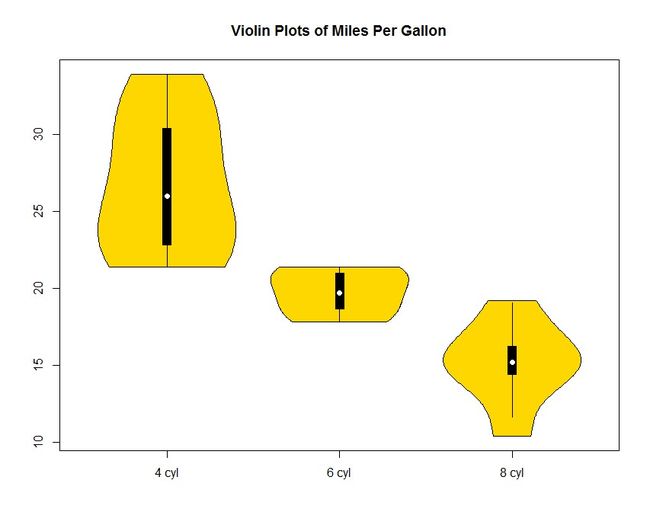
小提琴图基本上是核密度图以镜像的方式在箱线图上的叠加。在图中,白点是中位数,黑色盒型的范围是下四分位点到上四分位点,西黑线表示须。外部形状即为核密度估计。
6.6 点图
点图提供了一种在简单水平刻度上绘制大量有标签值的方法。可以用dotchart()函数创建点图。格式为:
dotchart(x, labels)
其中x是一个数值向量,而labels则是由每个点的标签组成的向量。你可以通过添加参数groups来选定一个因子,用以指定x中元素的分组方式。如果这样做,则参数groups可以控制不同组标签的颜色,cex可控制标签的大小。
注意:
点图有许多变种。Jacoby(2006)对点图进行了非常有意义的讨论,并且提供了创新型应用的R代码。此外,Hmisc包也提供了一个带有许多附加功能的点图函数(恰如其分地叫做dotchart2)。
附件:《R语言实战》学习笔记及代码(第六章)