ucore Lab0 一些杂记
前一阵子开始做 MIT 6.828,做了两三个实验才发现清华的 ucore 貌似更友好一些,再加上前几个实验也与6.828 有所重叠,于是决定迁移阵地。
文章计划分两类,一类是代码的分析,另一类是实验的解答和比较。
1. 计算机执行第一条指令之前,分段状态是怎样的?
执行make debug, 然后考察 QEMU monitor 中 GDT 的值:
GDT= 00000000 0000ffff
参考 GDTR 寄存器:

参考手册 2.4.1 节描述:
On power up or reset of the processor, the base address is set to the default value of 0 and the limit is set to 0FFFFH. A new base address must be loaded into the GDTR as part of the processor initialization process for protected-mode operation.
结论 计算机执行第一条指令前,也就是重置状态,全局描述符表区域被默认设置为,基址=0,limit=0FFFFH, 似乎是把整个内存空间都视作GDT,其本质上没有分段.
2. 怎样验证生成的磁盘文件是合法的 elf 文件?
期望: 磁盘的第 510 个(倒数第二个)字节是 0x55, 第 511 个(倒数第一个)字节是 0xAA.
验证:
cd ~/ucore_os_lab/labcodes_answer/lab1_result
make $(call totarget,ucore.img)输出结果:
//省略。..
000001e0 05 42 86 03 83 04 00 00 00 00 01 00 00 02 00 00 |.B..............|
000001f0 00 00 00 00 00 00 00 00 00 00 00 00 00 00 55 aa <-得证 |..............U.|
//省略。..原理 sign.c用于将一个二进制文件构建为一个磁盘文件。
3. bootloader 被如何加载到内存中?
前置问题 bootloader 如何生成?
考察 Makefile,参考实验报告中关于 make 的流程可知,ucore.img由bootblock和kernel合并而成.bootloader ,有效的 elf 文件是 /obj/bootblock.o; kernel 的有效 elf 文件是 bin/kernel.
BIOS把磁盘的第一个扇区作为 bootloader,即把磁盘的前 512 字节加载进来.
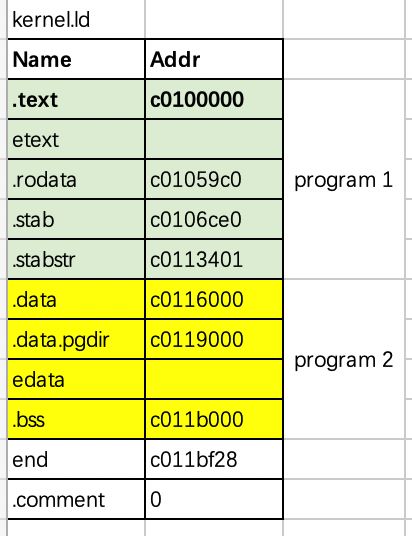
4. kernel 希望自己怎样加载到内存中,提供了哪些信息?
考察 kernel:
执行readelf -a kernel|less:
其中由
Program Headers:
Type Offset VirtAddr PhysAddr FileSiz MemSiz Flg Align
LOAD 0x001000 0x00100000 0x00100000 0x0eb0b 0x0eb0b R E 0x1000
LOAD 0x010000 0x0010f000 0x0010f000 0x00a16 0x01d80 RW 0x1000可知 kernel 提供了两个 program header,与section header对照,并结合链接脚本可知 kernel 提供的链接信息如下:
5. bootasm.S 中切换到保护模式之后,GDT 的分布是怎样的?
参考手册 2.4.1 节,GDTR 寄存器长度是 48bit, 32 位模式下维护着 GDT 的线性基址和字节数量。
LGDT 和 SGDT 分别用于(从程序中)加载(至 cpu) 和(从 CPU) 保存(到程序)中。cpu 重置时,GDT基址默认为 0,limit 默认为0FFFFH. 初始化保护模式时必须设置新的基址。
所以源代码中的 gdtdesc 就是描述了 GDT 的位置和字节数。但注意字节数=size(GDT)-1, 因为 (3.5.1)GDT 中的第一个条目不被使用,即"null descriptor". 当 segement selector 指向此条目时,不会产生异常,而是产生通用保护错误。
每个 segment descriptor 是 32*2=64 bit.

汇编代码初始化了代码段和数据段:
gdt:
SEG_NULLASM # null seg
SEG_ASM(STA_X|STA_R, 0x0, 0xffffffff) # code seg for bootloader and kernel
SEG_ASM(STA_W, 0x0, 0xffffffff) # data seg for bootloader and kernelSEG_ASM的定义是#define SEG_ASM(type,base,lim).
首先是 type.
type 的定义可参考手册 3.4.5.1 节:
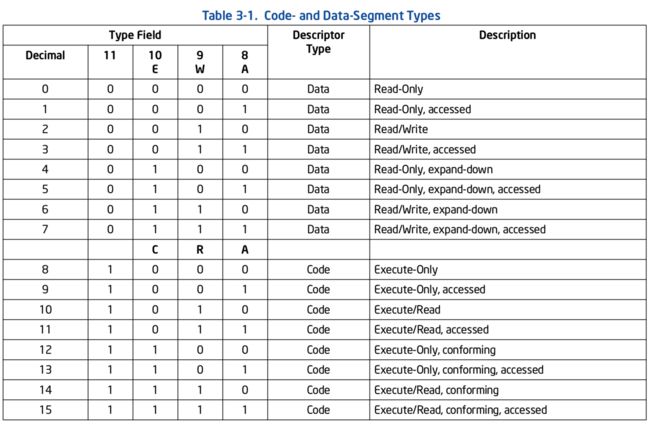
代码中事实上给出了相应的宏:
//mmu.h
#define STA_X 0x8 // Executable segment
#define STA_E 0x4 // Expand down (non-executable segments)
#define STA_C 0x4 // Conforming code segment (executable only)
#define STA_W 0x2 // Writeable (non-executable segments)
#define STA_R 0x2 // Readable (executable segments)
#define STA_A 0x1 // Accessed于是代码段的类型为可执行|可读取,数据段的类型为可读写。
代码初始阶段我们将内存设置为平铺模型(参考手册 3.2.2 节):
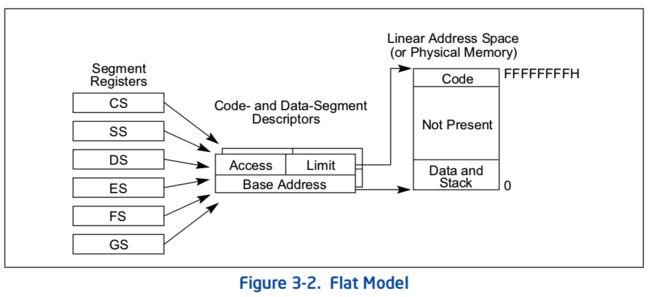
所以 base 和 limit 设置为内存边界值。
而 gdt 的大小,即为 64bit * 3 = 8byte * 3 = 24byte
24-1=23=0x17. 至于为何要-1, 参考 OSdev 的解释。
验证 gdt 的内存分布:
首先 qemu 进入 monitor (Ctrl-Alt 2):
//查看 gdtr:
info registers
GDT = 00007c54 00000017即 gdt 基址为 0x7c54, 大小为 0x17. 与代码中一致。
通过 gdb 查看:
make debug # 进入保护模式
(gdb) p gdt
$1 = {} 0x7c54 # 得到 gdt 的地址
(gdb) x/6x 0x7c54
0x7c54 : 0x00000000 0x00000000 0x0000ffff 0x00cf9a00
0x7c64 : 0x0000ffff 0x00cf9300 用逻辑表来描述主要字段就是:
| Index | Base | Limit | 类型 |
|---|---|---|---|
| 0 | 0 | 0 | NULL |
| 1 | 0x0 | 0xffffffff | code |
| 2 | 0x0 | 0xffffffff | data |
6. 要执行保护模式下的 c 代码,需要如何设置寄存器?
执行call bootmain的前提是要把段寄存器设置正确,因为 call 标号 等价于
push IP
jmp near ptr 标号通过长转移指令,修改 cs 和 ip.
ljmp $PROT_MODE_CSEG, $protcseg即段内转移。那么bootmain位于哪个段里?
其实我们设置 GDT 已经很清楚了,代码段和数据段都是从 0 开始!但是在保护模式下,ljmp 的第一个操作数不再是段地址,而是段选择子,即 GDT 的索引值。那么基于我们刚刚建立的 gdt,代码段和数据段的索引分别是1 和 2.所以只需将 cs 段选择子中的索引部分设置为 1 和 2 即可.
关于段选择子的格式,参考手册 3.4.3 节:

高位是索引,手动写入,低位由 cpu 自动写入.
再考察 Segment Selector 的格式(3.4.2 节):

Segment Selector 的三个字段分别是 Index,TI,RPL.
Index: 3~15bit,选择GDT 或 IDT 中8192 个条目之一,注意此 index 不是地址,而是索引号,从 0 开始每次增长 1,所以要想正确找到 gdt 条目的话还需*8.因为每个 segment descriptor 的大小是 64bit=8byte.
计算过程图:
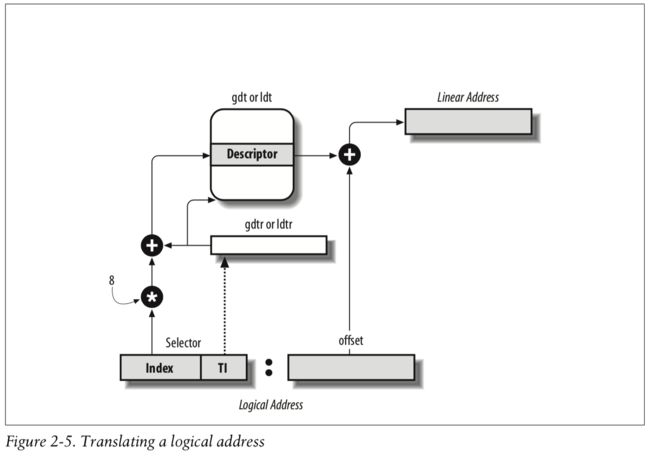
图自 Understanding the LINUX KERNEL, 3rd edition
TI: Table Indicator, 指明是 GDT 还是 LDT,0 为 GDT,1 位 LDT.
RPL: Request Privilege Level.对于向内核的请求,此值为 0.
所以:用于描述 code 段的 selector 应该是 index 为 1,ti 为 0,RPL = 0,即 100b=0x8;用于描述 data 段的 selector 应该是 1000b=0x10.
7. 函数调用分析:
- 0 到多个 push,参数入栈
- 一个 call 指令. call 指令其实也 push 了返回地址,即 call 指令下一个命令的指令
函数序言:
保存并更新段基址.
pushl %ebp
movl %esp , %ebp所以在执行调用函数的代码前,已经有 1)参数 2)返回地址 3)ebp 三种类型的值入栈:
+| 栈底方向 | 高位地址
| ... |
| ... |
| 参数3 |
| 参数2 |
| 参数1 |
| 返回地址 |
| 上一层[ebp] | <-------- [ebp]
| 局部变量 | 低位地址注意!当前 ebp 指向的值就是上一层函数的 ebp!
则有:
| 地址 | 代码 |
|---|---|
| 第一个参数(假定4byte) | ss:[ebp+8] |
| 返回地址 | ss:[ebp+4] |
上一层 ebp |
ss:[ebp] |
| 第一个局部变量 | ss:[ebp-4] |
参考链接
lab1 练习 6 如何初始化中断向量表?
中段描述符表(IDT):
参考手册 6-11:
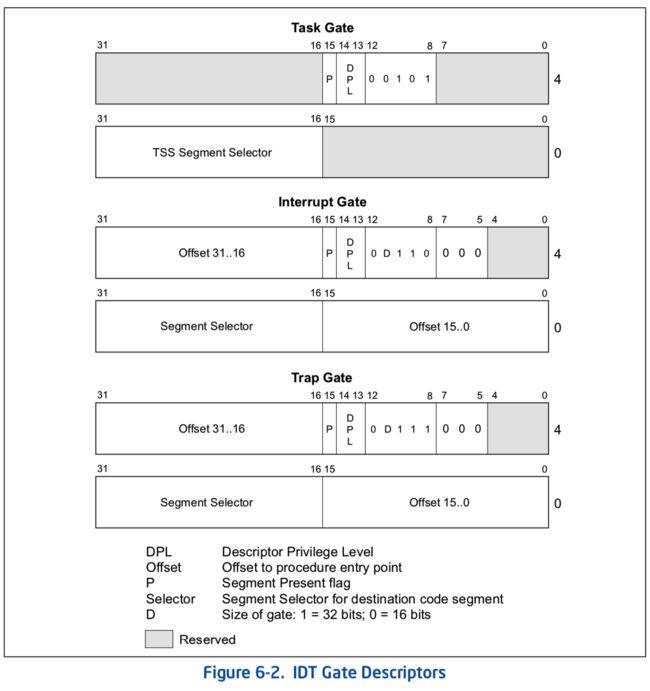
三种 gate 通过 type 指定类型.
对于每个描述符,都要按照宏#define SETGATE(gate, istrap, sel, off, dpl)填充其是否是 trap gate,以及指向段的 selector,limit,dpl.
通过中断访问门进而访问代码段,通过内存访问数据段.
本来特权级低的代码是不能访问特权级高的代码段(内核态)的,但是通过等级更低的门就可以了,门的特殊功效就是通向更高级别的段!这就是所谓的系统调用.