Sovereign Systems是一家成立于2007年的技术咨询公司,帮助客户将传统数据中心技术和应用程序转换为更高效的、基于云的技术平台,以更好地应对业务挑战。曾连续3年提名CRN,并且在2012年到2016年均被评为美国增长最快的私营公司之一。
本文由Sovereign Systems的解决方案架构师Chip Zoller根据客户的使用案例撰写而成。
Rancher是一个容器编排管理平台,它已经在这一领域深耕几年并且具备很多简单易用的实用功能。近几年,它经过重构已经完全拥抱Kubernetes。在本文中,我将着重介绍如何在VMware Enterprise PKS之上构建一个企业级、高可用和安全的Rancher Server安装。同时,我将回答“为什么要在PKS上使用Rancher”这一问题。此外,本文将包括整个构建流程、架构以及完整的安装指南。涉及的内容十分丰富,赶紧开始吧!
把Rancher部署在PKS上?
我知道这并不是一个普遍的搭配,特别是这两个解决方案还存在某种竞争关系。它们都能够在不同的云提供商部署Kubernetes集群,并可以在本地部署到诸如vSphere之类的堆栈。它们分别都有自己的长处和短处,但是在管理空间中两者没有重叠的地方。Enterprise PKS使用BOSH部署Kubernetes集群,并且继续将其用于生命周期的事件——扩展、修复、升级等。而Rancher则是将自己的驱动程序用于各种云PaaS解决方案,甚至使用vSphere进行本地部署来执行类似的任务。但Rancher能够导入外部配置的集群并且为其提供可见性,至今PKS还没有实现这样的功能。而在VMware 2019大会上,VMware宣布推出一款名为Tanzu Mission Control的产品,该产品在未来或许能实现Rancher现有的这些功能。但是,在那之前,Rancher依旧代表着优秀的技术,它可以管理并且聚合不同的Kubernetes集群到单一的系统中。
这个案例从何而来?
和我之前写过的很多文章一样,这篇文章也是从客户项目中衍生出来的。而且由于找不到关于这个主题的Enterprise PKS指南,我决定自己写一个。这个客户计划使用裸机、小型硬件将在边缘的Kubernetes部署到全球数百个站点。他们需要将所有集群统一到一个工具中,从而方便管理、监控以及应用程序部署。他们在主要的数据中心运行Enterprise PKS,来为其他业务需求部署Kubernetes集群。由于这些站点都与他们在世界各地的各个数据中心相连接,因此它们需要聚集在一个可以在本地运行的工具中,同时必须具有高可用性、安全性和高性能。将Enterprise PKS用于底层、专用的Kubernetes集群,然后在该集群上以HA模式在Rancher Server上分层,这样操作为我们两个方面的绝佳功能——通过NSX-T进行网络和安全性,通过BOSH进行集群生命周期维护,通过Harbor复制镜像仓库并且通过Rancher在边缘范围内对分散的Kubernetes集群在单一窗格进行统一管理。
架 构
我们先来看看架构图。
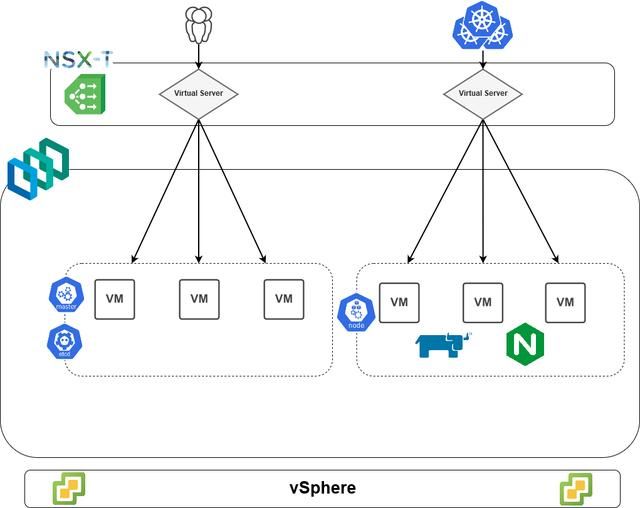
理论上说,我们在底部有一个vSphere栈,它在我们本地的SDDC中托管这个环境。接下来,我们通过PKS构建了一个3-master和3-worker的Kubernetes集群。除了许多其他系统容器(未在上图显示)之外,worker还托管Rancher pod和Nginx pod。基于以上,我们使用NSX-T提供的负载均衡器来提供两个主要虚拟的服务器:一个用于控制平面访问,另一个用于ingress访问。
然而,经过反复的试验并最终失败之后,我发现NSX-T的L7负载均衡器并不支持Rancher正常运行所需的必要请求头。具体来说,Rancher需要在HTTP请求中传递4个请求头到pod。这些请求头用于识别入站请求的来源,并确保在应用程序外部已经发生适当的TLS终止。其中一个请求头X-Forwarded-Proto,它可以告诉Rancher用于与负载均衡器进行通信的协议,但NSX-T的负载均衡器无法传递这些请求头。基于此,我们必须使用第三方ingress controller——nginx,它是目前最流行的解决方案之一,它对大部分的客户端选项提供了广泛的支持,并且可以直接发送请求头。
我们接着往下一个层次看,进入Kubernetes内部(如下图所示)。请记住,我们正在专门研究worker,但正在抽象化诸如节点之类的物理层。
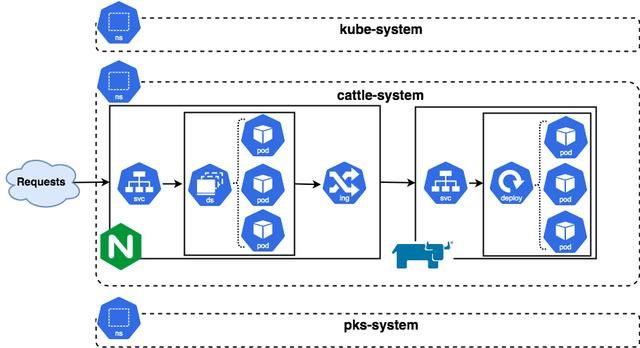
外部请求通过Nginx controller中的LoadBalance服务类型进入集群。从该服务构建的端点列表中选择一个nginx controller,进而匹配ingress controller中的规则。该请求将转发到Rancher Service,最后到与该服务上的标签selector匹配的pod。
我们接下来一步一步完成安装过程,看完之后你将会有更深的理解。
安 装
请记住上文提到的架构,我们将开始将这些碎片拼在一起。一共有6个大步骤,每个步骤下都有详细的小步骤,我会详细说明。
1、 配置新的自定义PKS集群
第一步,我们将专门为Rancher制定一个plan,然后构建一个专门用于在HA模式下运行Rancher的集群。我们还将制作一个自定义的负载均衡器配置文件,以供构建中参考。
2、 使用Helm准备集群
集群构建完成之后,我们需要进行准备,以便可以使用Helm的软件包,因为我们将使用它来安装ingress controller和Rancher。
3、 生成证书和secret
这是一个企业级的部署,这意味着要使用自定义证书。所以我们需要创建那些证书并且使它们可供Kubernetes的各种API资源使用。
4、 创建并配置Ingress
既然我们无法使用NSX-T作为Ingress controller,那么我们必须配置另一种类型并适当地配置它。然后我们将使用一个NSX-T的Layer-4负载均衡器来发送流量到ingress。
5、 安装Rancher
接下来,我们使用Helm安装Rancher。
6、 配置基础架构
一切都就位之后,我们需要执行一些部署后的配置任务,然后才完成所有的步骤。
接下来,我将详细解释每一个步骤具体如何操作。
配置新的自定义PKS集群
首先我们需要做的是设置PKS基础架构,以便我们可以将Kubernetes集群部署在任意地方。需要做两件最基础的事情:创建一个新plan,创建中型负载均衡器。我们的plan需要指定3个master以使控制平面级别高可用,并且3个worker在工作负载级别高可用。在本例中,由于我们正在准备将大量集群安装到Rancher中,因此我们可能要继续进行操作,并指定一个中型负载均衡器,否则PKS会给我们一个很小的负载均衡器。这个负载均衡器将为控制平面/API访问提供虚拟服务器并将traffic发送到Rancher。
在PKS tile中,我使用以下配置创建一个新plan。
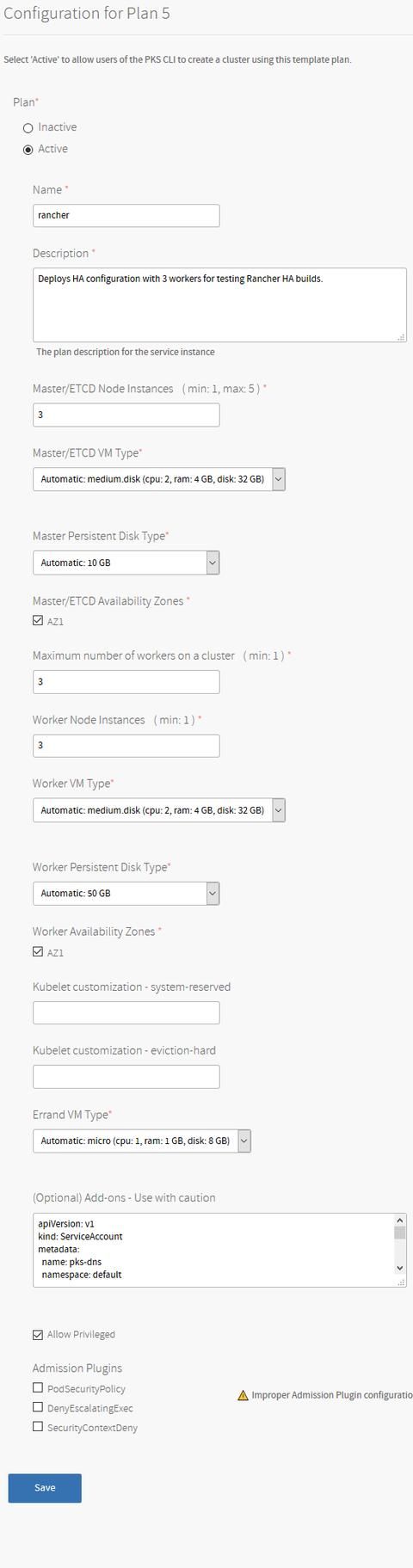
根据你自己的需求来创建plan,但记住master和worker的数量。如果想要将其放入生产环境中,我建议你增加master永久磁盘的规格。既然每个主节点都是一个包含控制平面组件和etcd的组合节点,并且Rancher将充分利用Kubernetes集群的etcd安装作为其数据存储,因此我们要确保有足够的空间。
你可以使用底部的附加组件部分来自动加载任意Kubernetes Manifest,使其可以在集群构建过程中运行。我将使用pks-dns,它可以在控制平面启动后自动为其创建DNS记录。如果你之前尚未使用过,我强烈建议你试用一下。
最后,为了让Rancher agent能够正确运行,请务必在此集群上启动“允许特权”模式。
现在,使用之前保存的plan和提交的更改,你应该能够运行一个pks plans并且显示这个新的plan。
1 $ pks plans 2 Name ID Description 3 dev-small 8A0E21A8-8072-4D80-B365-D1F502085560 1 master; 2 workers (max 4) 4 dev-large 58375a45-17f7-4291-acf1-455bfdc8e371 1 master; 4 workers (max 8) 5 prod-large 241118e5-69b2-4ef9-b47f-4d2ab071aff5 3 masters; 10 workers (20 max) 6 dev-tiny 2fa824527-318d-4253-9f8e-0025863b8c8a 1 master; 1 worker (max 2); auto-adds DNS record upon completion. 7 rancher fa824527-318d-4253-9f8e-0025863b8c8a Deploys HA configuration with 3 workers for testing Rancher HA builds.
有了这个,我们现在可以创建一个自定义负载均衡器plan。目前,实现这个方法的唯一方式是通过pks CLI工具或通过创建自定义JSON规范文件创建API。保存一下信息到名为lb-medium.json.的文件中,根据自己的需求替换“name”和”description”的值。
1 { 2 "name": "lb-medium", 3 "description": "Network profile for medium NSX-T load balancer", 4 "parameters": { 5 "lb_size": "medium" 6 } 7 }
运行以下命令来创建一个新的网络配置文件:
1 $ pks create-network-profile lb-medium.json
再次检查,确保plan是存在的。
1 $ pks network-profiles 2 3 Name Description 4 lb-medium Network profile for medium NSX-T load balancer
现在使用你的plan和中型负载均衡器创建一个新的PKS集群。
1 $ pks create-cluster czpksrancher05 -e czpksrancher05.sovsystems.com -p rancher --network-profile lb-medium
构建集群将会花费几分钟的时间,可以趁机休息一下。你可以监视集群创建过程,以了解什么时候创建完成。
1 $ nslookup czpksrancher05 2 Server: 10.10.30.13 3 Address: 10.10.30.13#53 4 Name: czpksrancher05.sovsystems.com 5 6 Address: 10.50.0.71
集群创建完成之后,如果你之前使用了我推荐的pls-dns工具,那么你的DNS记录现在也应该已经创建好了。
1 $ nslookup czpksrancher05 2 Server: 10.10.30.13 3 Address: 10.10.30.13#53 4 Name: czpksrancher05.sovsystems.com 5 6 Address: 10.50.0.71
现在,所有必要的工作都完成了,我们可以访问这个集群。首先让我们先配置kubeconfig。
1 $ pks get-credentials czpksrancher05
然后确认我们是否具有访问权限。
1 $ kubectl cluster-info 2 Kubernetes master is running at https://czpksrancher05.sovsystems.com:8443 3 CoreDNS is running at https://czpksrancher05.sovsystems.com:8443/api/v1/namespaces/kube-system/services/kube-dns:dns/proxy
使用Helm准备集群
既然现在我们已经可以访问我们的集群,我需要使用Helm来准备它。Helm是一个用chart的打包格式来将整个应用程序部署到Kubernetes的一个工具。这些chart打包了完整部署应用程序所需的各种Kubernetes manifest。网络上已经有大量的文章介绍了Helm及其入门,所以我将不再赘述。我假设你已经了解了这些,并将Helm二进制文件添加到了PATH中。我们需要在Kubernetes创建一个必要的对象,以供Tiller(Helm的服务器端组件)运行。这包括了一个ServiceAccount、ClusterRoleBinding,然后初始化Helm。
1 $ kubectl -n kube-system create serviceaccount tiller 2 serviceaccount/tiller created
创建Tiller帐户的绑定作为集群管理员。当你完成安装之后,你就可以解除绑定了。通常来说,绑定service account到集群管理员角色并不是一个好主意,除非它们真的需要集群范围的访问。如果你想的话,可以限制Tiller部署到单个命名空间中。幸运的是,在Helm3中将不会有Tiller,这将进一步简化Helm chart的部署并提高了安全性。
1 $ kubectl create clusterrolebinding tiller --clusterrole cluster-admin --serviceaccount=kube-system:tiller 2 clusterrolebinding.rbac.authorization.k8s.io/tiller created
接下来,使用service account初始化Helm,这将在kube-system命名空间创建一个Tiller pod。
1 $ helm init --service-account tiller 2 $HELM_HOME has been configured at /home/chip/.helm. 3 Tiller (the Helm server-side component) has been installed into your Kubernetes Cluster.
你现在应该能够检查并看到一个新的Tiller pod已经创建完成并且正在运行。
1 $ kubectl -n kube-system get po -l app=helm 2 NAME READY STATUS RESTARTS AGE 3 tiller-deploy-5d6cc99fc-sv6z6 1/1 Running 0 5m25s
helm version要能确保客户端的helm二进制文件能够与新创建的Tiller pod通信。
1 $ helm version 2 Client: &version.Version{SemVer:"v2.14.3", GitCommit:"0e7f3b6637f7af8fcfddb3d2941fcc7cbebb0085", GitTreeState:"clean"} 3 Server: &version.Version{SemVer:"v2.14.3", GitCommit:"0e7f3b6637f7af8fcfddb3d2941fcc7cbebb0085", GitTreeState:"clean"}
第二个步骤就完成,接下来我们需要做一些证书工作。
生成证书和secret
现在,我们不得不创建我们的自定义证书并使它们可供Kubernetes使用。在本例中,我使用由内部企业证书颁发机构(CA)签名的证书,但是你可以只使用由第三方根签名的通用证书。Rancher可以使用以上两种证书,也可以使用自签名证书。由于这是一个企业级部署,我们需要一个已经建立的信任链,因此我们将使用企业CA。
创建证书的过程可能会有所不同,因此我无法一一列出所有情况,我只会简单介绍与本例所需证书创建和生成过程相同的证书。但是无论如何,我们都需要一个主机名,通过它可以访问集群中运行的Rancher应用程序。不要将之前我们在创建PKS集群时使用的外部主机名混淆,它们时两个单独的地址,并且作用也不一样。我将这个Rancher安装命名为“czrancherblog”,以便正确地生成并签名我的证书。
通过Internet的魔力,我们可以快速完成生成过程,直到获得证书,secret和根CA证书文件。
确保运行kubectl的系统可以访问这些文件,然后继续。
我们将为Rancher创建一个新的命名空间,在命名空间内,我们需要创建2个secret:一个用于签署我们的主机证书的根CA证书,以及实际生成的证书及其对应的私钥。
1 $ kubectl create ns cattle-system 2 namespace/cattle-system created
在创建第一个secret之前,确保根CA证书命名为cacerts.pem,必须准确地使用这个名字,否则Rancher pod将启动失败。
1 $ kubectl -n cattle-system create secret generic tls-ca --from-file=cacerts.pem 2 secret/tls-ca created
接下来,创建TLS secret,该secret将保存czrancherblog站点的主机证书。此外,在下一步创建的nginx ingress controllerPod也会需要这个secret,以便正确认证客户请求。
1 $ kubectl -n cattle-system create secret tls czrancherblog-secret --cert=czrancherblog.cer --key=czrancherblog.key 2 secret/czrancherblog-secret created
验证已经创建的两个secret
1 $ kubectl -n cattle-system get secret 2 NAME TYPE DATA AGE 3 czrancherblog-secret kubernetes.io/tls 2 2m7s 4 default-token-4b7xj kubernetes.io/service-account-token 3 5m1s 5 tls-ca Opaque 1 3m26s
你会注意到,创建了这些secret,实际上只是创建两种不同类型的secret而已。tls-ca这个secret是Opaque类型的secret,而czrancherblog-secret是一个TLS secret。如果你两相比较,你会注意到tls-ca secret会在数据部分为cacerts.pem列出一个base64-encoded 证书。而czrancherblog-secret 将会列出其中的两个,每个文件分配一个。你同时还会注意到无论你提供哪种输入文件,都已经为tls.crt和tls.key列出它们的值(经过base64编码以使它们模糊之后)。
现在我们已经完成证书的生成了,现在应该到nginx ingress的部分。
创建和配置Ingress
既然secret和命名空间都已经创建,现在让我们来安装nginx-ingress controller。如上文所提到的,尽管Enterprise PKS可以并且将使用NSX-T作为现成的Ingress controller,但是Rancher有些特殊需求是这一controller无法满足的。因此在这一情况下,我们将使用其他的controller。Nginx有一个被广泛使用并且技术成熟的ingress controller,恰好符合我们的需求。请注意在本例中,我使用的是kubernetes/ingress-nginx,而不是nginxinc/Kubernetes-ingress。尽管它们有些许差异,但其实在本例中两者都能使用。
在您的终端上,运行以下Helm命令以从稳定版本中安装kubernetes / ingress-nginx controller:
1 helm install stable/nginx-ingress --name nginx --namespace cattle-system --set controller.kind=DaemonSet
在这个命令中,我们让Helm把nginx对象放入cattle-system命名空间中,并且将pod作为DaemonSet而不是Deployment来运行。我们希望每个Kubernetes节点都有一个controller,进而节点故障不会消除通往Rancher Pod的入口数据路径。Rancher将完成类似的任务,但将使用具有pod反关联规则的deployment(这与vSphere DRS的工作原理相似)。
命令完成之后,你将会从Helm获得一连串的返回,包括所有它创建的对象。需要指出的是,几个API对象是ConfigMap,它存储nginx controller的配置以及服务。
1 ==> v1/Service 2 NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE 3 nginx-nginx-ingress-controllern LoadBalancer 10.100.200.4880:32013/TCP,443:32051/TCP 0s 4 nginx-nginx-ingress-default-backend ClusterIP 10.100.200.45 80/TCP 0s
第一个称为nginx-nginx-ingress-controller的类型为LoadBalancer。从应用程序的角度来看,这实际上将是Rancher集群的切入点。如果你看到External-IP栏,你将会注意到它最初只报告了
1 # kubectl -n cattle-system get svc 2 NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE 3 nginx-nginx-ingress-controller LoadBalancer 10.100.200.48 10.50.0.79,100.64.128.125 80:32013/TCP,443:32051/TCP 6m35s 4 nginx-nginx-ingress-default-backend ClusterIP 10.100.200.4580/TCP 6m35s
这一次,你将会发现它分配了两个IP,因为NSX容器插件(NCP)注意到该对象的创建,并已与NSX-T进行通信,以使用为此集群指定的中型负载均衡器为我们创建新的虚拟服务器。
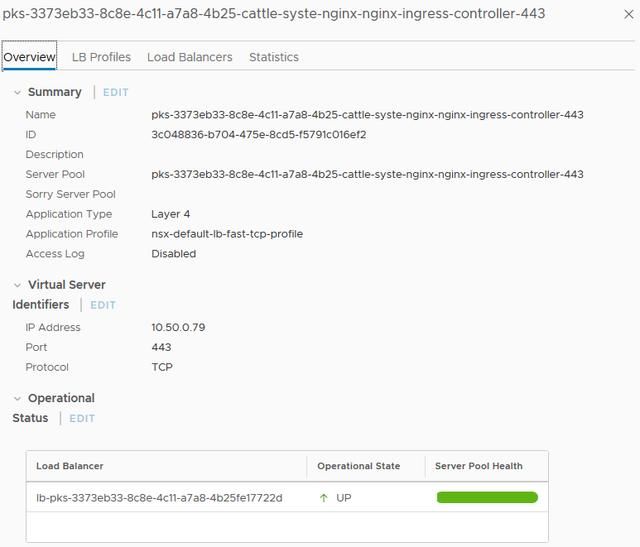
如果你跳到NSX-T管理器界面中的Server Pool选项卡,并找到此处引用的选项卡,那么可以检查Pool Member选项卡,并查看它已自动添加了该服务引用的端点。
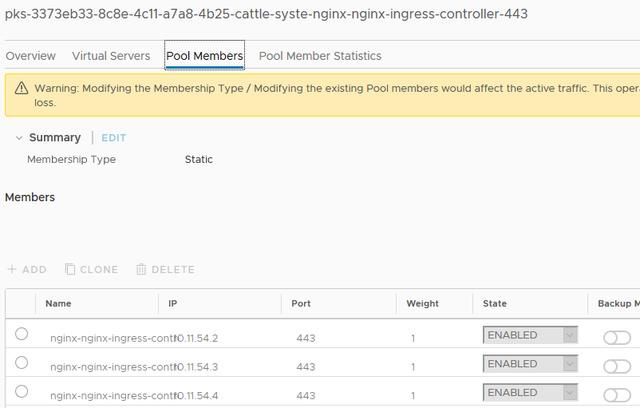
Name栏被截断了,但是IP栏依旧可见。让我们再次检查一下Kubernetes。
1 $ kubectl -n cattle-system get po -o wide -L app 2 NAME READY IP NODE APP 3 nginx-nginx-ingress-controller-wjn2x 1/1 10.11.54.2 9aa90453-2aff-4655-a366-0ea8e366de4a nginx-ingress 4 nginx-nginx-ingress-controller-wkgms 1/1 10.11.54.3 f35d32a0-4dd3-42e4-995b-5daffe36dfee nginx-ingress 5 nginx-nginx-ingress-controller-wpbtp 1/1 10.11.54.4 e832528a-899c-4018-8d12-a54790aa4e15 nginx-ingress 6 nginx-nginx-ingress-default-backend-8fc6b98c6-6r2jh 1/1 10.11.54.5 f35d32a0-4dd3-42e4-995b-5daffe36dfee nginx-ingress
输出的内容被稍微修改了一点点,去除了不必要的栏,但除了正在运行的节点之外,你还可以清晰地看到pod、它们的状态以及IP地址。
有了新虚拟服务器的IP地址,我们接下来需要创建一个DNS记录,可以与我们的Rancher HA安装的主机名对应。我决定将其命名为“czrancherblog”,因此我将在DNS中创建一个A记录,将在czrancherblog指向10.50.0.79。
1 $ nslookup czrancherblog 2 Server: 10.10.30.13 3 Address: 10.10.30.13#53 4 Name: czrancherblog.sovsystems.com 5 Address: 10.50.0.79
这一阶段的最后一步是在Kubernetes上创建ingress controller。尽管我们已经有LoadBalancer这一服务类型,我们依旧需要ingress资源来路由流量到Rancher service。但该服务尚不存在,但很快就可以创建。
使用以下代码创建一个新的manifest,命名为ingress.yaml,并且使用kubectl create -f ingress.yaml对其进行应用:
1 apiVersion: extensions/v1beta1 2 kind: Ingress 3 metadata: 4 annotations: 5 kubernetes.io/ingress.class: nginx 6 namespace: cattle-system 7 name: rancher-ingress 8 spec: 9 rules: 10 - host: czrancherblog.sovsystems.com 11 http: 12 paths: 13 - backend: 14 serviceName: rancher 15 servicePort: 80 16 tls: 17 - hosts: 18 - czrancherblog.sovsystems.com 19 secretName: czrancherblog-secret
现在我来解释一下这个manifest。首先,我们的类型是Ingress,接下来我们有一个注释。这一行实际上在做两件事:指示NCP不要告诉NSX-T创建和配置任何对象,并告诉Nginx controller将流量路由到端口80上尚未创建的名为rancher的服务。最后,当来自主机值为czrancherblog.sovsystems.com的请求中的任何流量进入系统时,它使用我们创建的包含证书及密钥的TLS secret应用到controller上。
尽管我们希望不会出错,但是我们仍然要将该地址放入网络浏览器中,以查看返回的内容。

我们将获得一些重要的信息。首先,非常明显的大字“503 Service Temporarily Unavailable”,考虑到目前尚无流量经过nginx controller,这样的返回结果是符合期望的。其次, 在地址栏我们看到了一个绿色锁的图标,这意味着我们创建的包含证书的TLS secret已经被接受并且应用于主机规则。
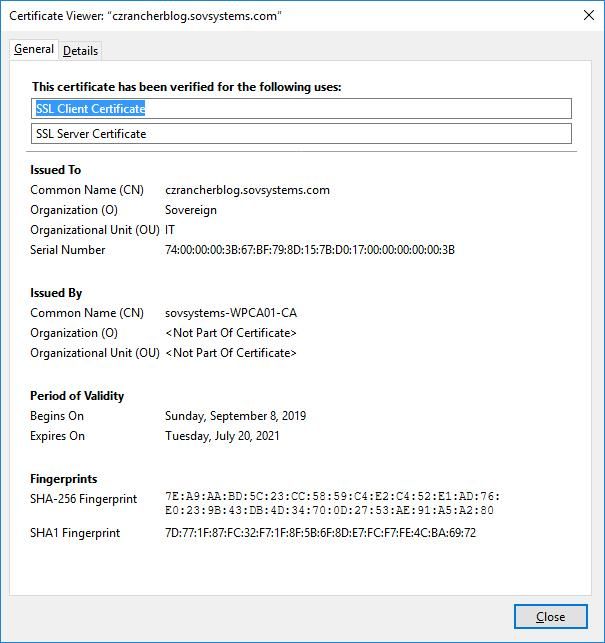
到目前为止,都在向预想的方向进行,让我们进行下一步。
安装Rancher
终于到了期待已久的一刻——安装Rancher。现在我们一切都准备好了,开始安装吧!
添加Rancher stable仓库到Helm,然后进行更新并拉取最新chart。
1 $ helm repo add rancher-stable https://releases.rancher.com/server-charts/stable 2 "rancher-stable" has been added to your repositories
1 $ helm repo list 2 NAME URL 3 stable https://kubernetes-charts.storage.googleapis.com 4 local http://127.0.0.1:8879/charts 5 rancher-stable https://releases.rancher.com/server-charts/stable
$ helm repo update Hang tight while we grab the latest from your chart repositories... ...Skip local chart repository ...Successfully got an update from the "rancher-stable" chart repository ...Successfully got an update from the "stable" chart repository Update Complete.
为什么在安装nginx ingress之前我们不需要添加一个仓库呢?因为那个chart实际上来自由谷歌托管的默认”stable”仓库,因此没有自定义仓库可以添加。对于Rancher,我们必须添加stable或latest仓库以访问其管理的chart。
如果你已经成功更新了,那么赶紧激活Rancher吧。从stable repo中安装最新的chart,并检查输出。
1 $ helm install rancher-stable/rancher --name rancher --namespace cattle-system --set hostname=czrancherblog.sovsystems.com --set ingress.tls.source=secret --set privateCA=true 2 3 NAME: rancher 4 LAST DEPLOYED: Sun Sep 8 18:11:18 2019 5 NAMESPACE: cattle-system 6 STATUS: DEPLOYED 7 8 RESOURCES: 9 ==> v1/ClusterRoleBinding 10 NAME AGE 11 rancher 1s 12 13 ==> v1/Deployment 14 NAME READY UP-TO-DATE AVAILABLE AGE 15 rancher 0/3 0 0 1s 16 17 ==> v1/Pod(related) 18 NAME READY STATUS RESTARTS AGE 19 rancher-6b774d9468-2svww 0/1 ContainerCreating 0 0s 20 rancher-6b774d9468-5n8n7 0/1 Pending 0 0s 21 rancher-6b774d9468-dsq4t 0/1 Pending 0 0s 22 23 ==> v1/Service 24 NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE 25 rancher ClusterIP 10.100.200.1580/TCP 1s 26 27 ==> v1/ServiceAccount 28 NAME SECRETS AGE 29 rancher 1 1s 30 31 ==> v1beta1/Ingress 32 NAME HOSTS ADDRESS PORTS AGE 33 rancher czrancherblog.sovsystems.com 80, 443 1s 34 35 NOTES: 36 Rancher Server has been installed. 37 38 NOTE: Rancher may take several minutes to fully initialize. Please standby while Certificates are being issued and Ingress comes up. 39 40 Check out our docs at https://rancher.com/docs/rancher/v2.x/en/ 41 42 Browse to https://czrancherblog.sovsystems.com 43 44 Happy Containering!
很好,现在chart为我们部署了大量的Kubernetes对象。然而,注意一下最后一个对象,它是另一个ingress。我们不需要它,所以直接将其删除。
1 $ kubectl -n cattle-system delete ing rancher 2 ingress.extensions "rancher" deleted
检查pod以确保它们现在正在运行。
$ kubectl -n cattle-system get po -l app=rancher NAME READY STATUS RESTARTS AGE rancher-6b774d9468-2svww 1/1 Running 2 5m32s rancher-6b774d9468-5n8n7 1/1 Running 2 5m32s rancher-6b774d9468-dsq4t 1/1 Running 0 5m32s
非常棒,一切都起来了。如果你在RESTARTS列中看到的值不是零,也不要惊慌,Kubernetes最终会与其controller和监控循环保持一致,因此只要采取适当的措施,就可以使得实际状态达到所需状态为止。
现在,这些工作都完成之后,让我们再次检查我们的网页,看看发生了什么。

正如我们所希望的那样,我们现在进入我们的Rancher集群了!让我们设置初始密码以及在下一页面中设置server URL。如果不进行设置,它将自动填充我们的主机名。
这一步骤就算完成啦,接下来让我们进入最后一步。
配置基础架构
既然我们已经让一切都起来了并且正在运行,让我们做些事情。
首先,你可能已经注意到你的“local”集群卡在Provisioning的状态,正在等待设置主机名。通常这几分钟之后就会自动解决,但在本例中,则需要执行几个简单的步骤。
最快的修复步骤是点击最右边的设置按钮来编辑这个集群。
现在不做任何更改,直接点击保存。
然后回到主页,它应该已经起来了。
再次进入集群,确保你的节点正在汇报状态。
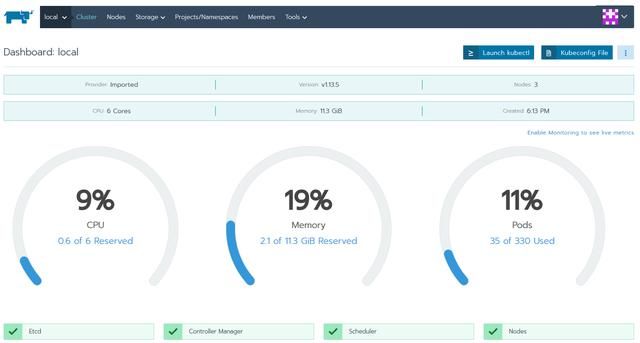
接下来,我们需要在主机之间分配我们的基础PKS Kubernetes节点。如果你的plan包括多个可用空间,你可能已经完成这一步了。但如果你像我一样,没有多个可用空间,你将需要某种方法来确保你的master和你的worker分布在ESXi主机上。如果你听说过我的Optimize-VMwarePKS项目,我强烈建议你使用它,该项目可以自动为你处理master,但我们依旧需要手动把worker分开。请记住,我们不仅需要API和控制平面的高可用,我们也需要Rancher 数据平面的高可用。这意味着任何管理程序的故障都不会影响我们应用程序的可访问性。
你使用-ProcessDRSRules标志运行Optimize-VMware-PKS之后,它应该检测到该集群的master并创建DRS反关联性规则。现在,你需要为worker节点手动创建一个新的节点。
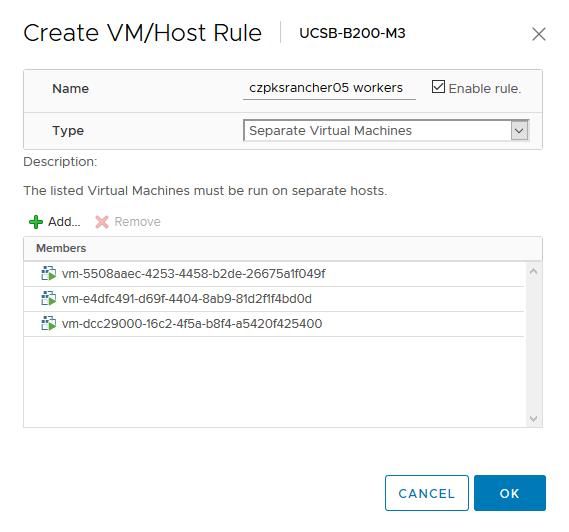
为worker创建一个新的反关联规则,并添加所有规则。由于BOSH会使用UUID而不是实际名称来部署它们,因此在列表中找到它们十分困难,但是你可以在vSphere VM和模板清单视图中找到它们(如果你使用-ProcessDRSRules标志运行Optimize-VMware-PKS),或者你可以在引用部署后,从BOSH CLI获取名称。
1 $ bosh -d service-instance_3373eb33-8c8e-4c11-a7a8-4b25fe17722d vms 2 Using environment 'czpcfbosh.sovsystems.com' as client 'ops_manager' 3 4 Task 55540. Done 5 6 Deployment 'service-instance_3373eb33-8c8e-4c11-a7a8-4b25fe17722d' 7 8 Instance Process State AZ IPs VM CID VM Type Active 9 master/00be5bab-649d-4226-a535-b2a8b15582ee running AZ1 10.50.8.3 vm-a8a0c53e-3358-46a9-b0ff-2996e8c94c26 medium.disk true 10 master/1ac3d2df-6a94-48d9-89e7-867c1f18bc1b running AZ1 10.50.8.2 vm-a6e54e16-e216-4ae3-8a99-db9100cf40c8 medium.disk true 11 master/c866e776-aba3-49c5-afe0-8bf7a128829e running AZ1 10.50.8.4 vm-33eea584-ff26-45ed-bce3-0630fe74f88a medium.disk true 12 worker/113d6856-6b4e-43ef-92ad-1fb5b610d28d running AZ1 10.50.8.6 vm-5508aaec-4253-4458-b2de-26675a1f049f medium.disk true 13 worker/c0d00231-4afb-4a4a-9a38-668281d9411e running AZ1 10.50.8.5 vm-e4dfc491-d69f-4404-8ab9-81d2f1f4bd0d medium.disk true 14 worker/ff67a937-8fea-4c13-8917-3d92533eaade running AZ1 10.50.8.7 vm-dcc29000-16c2-4f5a-b8f4-a5420f425400 medium.disk true 15 16 6 vms 17 18 Succeeded
无论你选择哪种方法,只要能保证规则创建即可。
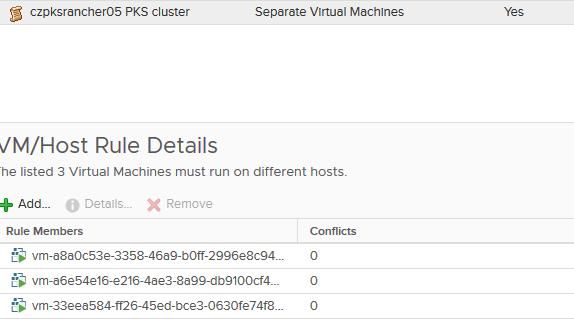
现在你已经有了master和worker的反关联规则,那么请确保你在多个方面都具备高可用性。如果你愿意进行测试,那么让工作节点(或与此相关的主节点)发生故障,或删除Rancher Pod,然后查看Kubernetes创建的新pod。此时,Rancher应该还保持工作状态。
结 语
你已经看到了我们如何从零开始创建了一个具备高可用性以及完整功能的Rancher Server,并且你也应该采取了一些措施确保将其安全地分布在底层架构上。你需要牢记一个重要的考虑因素:当在Enterprise PKS上运行Rancher的时候,与Kubernetes命名空间有关。当在Kubernetes上安装Rancher时,通过创建CRD和其他对象,Rancher从平台的角度将与Kubernetes深度集成。当用户创建一个新项目或导入一个新集群时,Kubernetes将会在后台创建一个新的命名空间。在其他Kubernetes环境中,这样的操作流程会非常完美,但在Enterprise PKS中,一个新的命名空间则意味着新的Tier-1 router、新的逻辑网段、新的pod IP块等。在PKS没有预先设置好的情况下,如果大量导入集群和创建项目,那么这些命名空间很快会耗尽诸如pod IP块之类的NSX-T对象。如果你正在考虑在生产环境中采用这样的架构,那么需要牢记这一点。现在,无法告诉NCP忽略这些命名空间创建命令,因此它不会在NSX-T内部生成对象。