此作业的要求参见https://edu.cnblogs.com/campus/nenu/2019fall/homework/7628
要求0 以 战争与和平 作为输入文件,重读向由文件系统读入。连续三次运行,给出每次消耗时间、CPU参数。 (2分)
运行方法
ptime wf -s < war_and_peace.txt连续三次运行时间截图
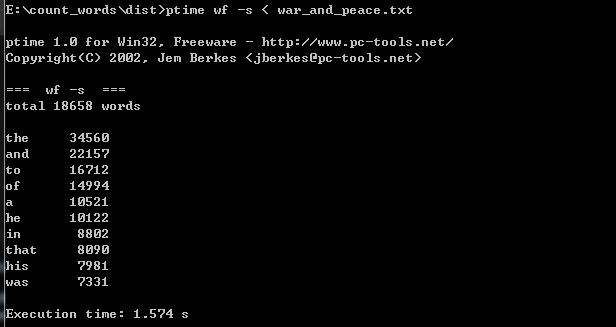
第一次消耗时间:1.574s
CPU参数:Intel(R)Core(TM)i5-8300H CPU @ 2.30GHz 2.30 GHz

第二次消耗时间:2.164s
CPU参数:Intel(R)Core(TM)i5-8300H CPU @ 2.30GHz 2.30 GHz

第三次消耗时间 1.583s
CPU参数:Intel(R)Core(TM)i5-8300H CPU @ 2.30GHz 2.30 GHz
要求1 给出你猜测程序的瓶颈。你认为优化会有最佳效果,或者在上周在此处做过优化 (或考虑到优化,因此更差的代码没有写出) 。
猜测的瓶颈:1.由文件重定向读入时遍历文档并把大写字母转化为小写时耗时过长。
2.用正则表达式区分单词并统计单词频率时耗时过长。
要求2 通过 profile 找出程序的瓶颈。给出程序运行中最花费时间的3个函数(或代码片断)。要求包括截图。
使用命令行进入程序所在目录后输入以下命令:python -m cProfile -s time wf.py -s < war_and_peace.txt
得到分析结果截图:

最花费时间的三个函数 findall() 0.297s, Couter()0.134s,read() 0.086s
优化前代码:
def doCountByPurText(inputText): words = re.findall(r'[a-z0-9^-]+', inputText.lower()) collect = collections.Counter(words) num = 0 for i in collect: num += 1 print('total %d words\n' % num) result = collect.most_common(10) for j in result: print('%-8s%5d' % (j[0], j[1]))
优化后代码:
def doCountByPurText(inputText): words = re.findall(r'[a-z0-9^-]+', inputText.lower()) count(words)
git链接:https://e.coding.net/xulijun/wf.git