15.1-创建字典:
第一种方式:
说明:字典的键不仅仅可以是字符串,也可以是数字。
>>> dic = {
... "k1" : 11,
... "k2" : 22,
... 3 : 33
... }
>>> type(dic)
第二种方式:
>>> dic = dict({
... "k1" : 11,
... "k2" : 22,
... 3 : 33
... })
>>> type(dic)
def __init__(self, seq=None, **kwargs): # known special case of dict.__init__
"""
dict() -> new empty dictionary
dict(mapping) -> new dictionary initialized from a mapping object's
(key, value) pairs
dict(iterable) -> new dictionary initialized as if via:
d = {}
for k, v in iterable:
d[k] = v
dict(**kwargs) -> new dictionary initialized with the name=value pairs
in the keyword argument list. For example: dict(one=1, two=2)
# (copied from class doc)
"""
pass
通过源码可以看出 dict 可以初始化一个映射对象的 (键,值)对,即创建一个与该映射对象具有相同键-值对的字典。
#!/usr/bin/env python
# -*- coding:utf-8 -*-
dic = dict(k1 = 11,k2 = 22)
print(dic)
运行结果:
还可以接收一个可迭代对象,会将可迭代对象里的元素通过for循环一遍,将其元素当做字典的值,而键是默认没有的,所以可以通过 enumerate() 函数给它加一个序号,当做字典的键。
#!/usr/bin/env python
# -*- coding:utf-8 -*-
li = [11,22,33,44]
dic = dict(enumerate(li))
print(dic)
运行结果:
15.2-索引
说明:由于字典是无序的,所以字典是通过键来进行索引的,索引取值时,若是键不存在就会报错。
#!/usr/bin/env python
# -*- coding:utf-8 -*-
dic = {
"k1" : 11,
"k2" : 22,
"k3" : 33
}
# 索引
print(dic["k2"])
运行结果:
注:字典是不能够进行切片的。
15.3-for循环:
默认循环:
循环时默认循环的是 key。
#!/usr/bin/env python
# -*- coding:utf-8 -*-
dic = {
"k1" : 11,
"k2" : 22,
"k3" : 33
}
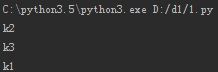
# 默认循环是 key
for i in dic:
print(i)
运行结果:
循环key:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
dic = {
"k1" : 11,
"k2" : 22,
"k3" : 33
}
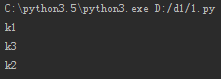
# 循环key,和默认循环相同
for i in dic.keys():
print(i)
运行结果:
注:和默认循环相同。
循环value:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
dic = {
"k1" : 11,
"k2" : 22,
"k3" : 33
}
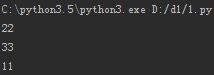
# 循环 value
for i in dic.values():
print(i)
运行结果:
循环key-value:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
dic = {
"k1" : 11,
"k2" : 22,
"k3" : 33
}
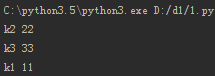
# 循环 键值对
for k,v in dic.items():
print(k,v)
运行结果:
15.4-字典(dict)内部方法介绍:
clear(self):
说明:删除字典中所有的元素。
#!/usr/bin/env python
# -*- coding:utf-8 -*-
dic = {
"k1" : 11,
"k2" : 22,
"k3" : 33
}
print(dic)
# 清空字典
dic.clear()
print(dic)
运行结果:

copy(self):
说明:浅拷贝。
fromkeys(*args, **kwargs):
说明:创建一个新的字典,第一个元素为可迭代的对象,将其中的元素作为字典的键,第二个元素为字典所有键对应的值。
#!/usr/bin/env python
# -*- coding:utf-8 -*-
dic = dict.fromkeys(["k1","k2","k3"],123456)
print(dic)
运行结果:
简单深入的例子:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
dic1 = dict.fromkeys(["k1","k2","k3"],11)
print(dic1)
dic2 = {"k1":11,"k2":11,"k3":11}
print(dic2)
运行结果:

注:默认生成一个字符串或者一个数字时,以上两个之间是没有区别的,但是如果生成的是一个列表或其它类型就有区别了。
#!/usr/bin/env python
# -*- coding:utf-8 -*-
dic1 = dict.fromkeys(["k1","k2","k3"],[])
print("dic1:",dic1)
dic2 = {"k1":[],"k2":[],"k3":[]}
print("dic2:",dic2)
print("-----" * 8)
# 在 空列表 里追加内容,通过 fromkeys 创建时,所有的键 共同对应着 同一个列表
dic1["k1"].append("11")
print("dic1",dic1)
# 每一个列表各自占一个内存
dic2["k1"].append("11")
print("dic2",dic2)
运行结果:
get(self, k, d=None):
说明:返回指定键的值, k 表示要指定的键, d 表示指定键不存在时返回的值,默认返回None。
#!/usr/bin/env python
# -*- coding:utf-8 -*-
dic = {
"k1" : 11,
"k2" : 22,
"k3" : 33
}
# 返回 "k2" 的值
ret = dic.get("k2")
print(ret)
# 指定键不存在时,默认返回 None
ret2 = dic.get("k4")
print(ret2)
# 指定键不存在时,设置返回值
ret3 = dic.get("k4",0)
print(ret3)
运行结果:
items(self):
说明:将字典中的键值对组成元组,并放到列表中返回。
#!/usr/bin/env python
# -*- coding:utf-8 -*-
dic = {
"k1" : 11,
"k2" : 22,
"k3" : 33
}
ret = dic.items()
print(ret)
运行结果:
keys(self):
说明:返回一个包含字典中键的列表。
#!/usr/bin/env python
# -*- coding:utf-8 -*-
dic = {
"k1" : 11,
"k2" : 22,
"k3" : 33
}
ret = dic.keys()
print(ret)
运行结果:
pop(self, k, d=None):
说明:移除字典中指定键对应的值,并返回该键对应的值, k 表示指定的键, d 表示当键不存在又不想处理异常时填写即可。
#!/usr/bin/env python
# -*- coding:utf-8 -*-
dic = {
"k1" : 11,
"k2" : 22,
"k3" : 33
}
# 删除 "k2" 并返回 "k2" 对应的值
ret = dic.pop("k2")
print(ret)
print(dic)
# 当 "k4" 不存在时,输出 "0"
ret2 = dic.pop("k4",0)
print(ret2)
运行结果:
popitem(self):
说明:随机删除字典中一对键和值,并返回该键值对。
#!/usr/bin/env python
# -*- coding:utf-8 -*-
dic = {
"k1" : 11,
"k2" : 22,
"k3" : 33
}
# 随即删除并返回
print(dic.popitem())
print(dic)
运行结果:
setdefault(self, k, d=None):
说明:如果指定键不存在,则创建键,如果存在则返回该键对应的值, k 表示指定的键, d 表示指定键不存在时,设置的默认值,默认为None。
#!/usr/bin/env python
# -*- coding:utf-8 -*-
dic = {
"k1" : 11,
"k2" : 22,
"k3" : 33
}
# 指定键存在时,返回该键对应的值
ret1 = dic.setdefault("k2")
print(ret1)
# 指定键不存在时,则创建该键,该键默认值为 None
ret2 = dic.setdefault("k4")
print(ret2)
# 设置默认值
ret3 = dic.setdefault("k5",55)
print(ret3)
print(dic)
运行结果:
update(self, E=None, **F):
说明:更新,将一个字典中的键值对更新到另一个字典中,如果字典原有的键与新添加的键重复,则新添加的覆盖原有的, E 表示添加到指定字典中的字典。
#!/usr/bin/env python
# -*- coding:utf-8 -*-
dic1 = {
"k1" : 11,
"k2" : 22,
"k3" : 33
}
dic2 = {
"k3" : "v3v3",
"k4" : 44,
"k5" : 55
}
dic1.update(dic2)
print(dic1)
运行结果:
values(self):
说明:返回一个包含字典中值的列表。
#!/usr/bin/env python
# -*- coding:utf-8 -*-
dic = {
"k1" : 11,
"k2" : 22,
"k3" : 33
}
ret = dic.values()
print(ret)
运行结果:
15.5-检查字典中指定key是否存在:
可以通过 in 来查看指定 key 是否存在字典中,如果存在字典中返回 True ,否则返回 False。
#!/usr/bin/env python
# -*- coding:utf-8 -*-
dic = {
"k1" : 11,
"k2" : 22,
"k3" : 33
}
# 指定 键 存在字典中
ret1 = "k2" in dic.keys()
print(ret1)
# 指定 键 不存在字典中
ret2 = "k4" in dic.keys()
print(ret2)
运行结果:
既然可以通过 in 来查看指定 key 是否存在字典中,那么也是可以通过 in 来查看指定 value 是否存在字典中的。
#!/usr/bin/env python
# -*- coding:utf-8 -*-
dic = {
"k1" : 11,
"k2" : 22,
"k3" : 33
}
# 指定 值 存在字典中
ret1 = 33 in dic.values()
print(ret1)
# 指定 值 不存在字典中
ret2 = 44 in dic.values()
print(ret2)
运行结果:
15.6-删除字典指定键值对:
通过 del 关键字删除字典中指定的键值对。
#!/usr/bin/env python
# -*- coding:utf-8 -*-
dic = {
"k1" : 11,
"k2" : 22,
"k3" : 33
}
print(dic)
# 删除 "k1" 这个键值对
del dic["k1"]
print(dic)
运行结果:
15.7-enumerate()函数:
说明: enumerate(iterable, start=0) 根据可迭代对象创建枚举对象,即同时返回索引和值, iterable 表示接受一个可迭代对象, start 表示指定索引的起始值,默认为0。
#!/usr/bin/env python
# -*- coding:utf-8 -*-
li = ["手机","电脑","汽车用品","图书"]
# 起始值从 1 开始,默认为 0
for key,item in enumerate(li,1):
print(key,item)
choice = int(input("请选取商品:"))
# 索引是从 0 开始的,只不过打印是从 1 开始的
# 所以选 1 的时候打印的还是电脑,所以可以让输入的值 -1
buy = li[choice-1]
print(buy)
运行结果:
15.8-练习题:
元素分类:
要求:有如下值集合[11,22,33,44,55,66,77,88,99,90]将所有大于 66 的值保存至字典的第一个key中,将小于 66 的值保存至第二个key的值中。即: {'k1': 大于66的所有值, 'k2': 小于等于66的所有值}。
#!/usr/bin/env python
# -*- coding:utf-8 -*-
l1 = [11,22,33,44,55,66,77,88,99,90]
dic = {
"k1" : [],
"k2" : []
}
# 循环 l1 并对里面每一个元素进行判断
for i in l1:
if i > 66:
dic["k1"].append(i)
else:
dic["k2"].append(i)
print(dic)
运行结果:
通过for循环将列表转换成字典:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
li = [11,22,33,44]
dic = {}
# key 是从 10 开始递增的
for k,v in enumerate(li,10):
dic[k] = v
print(dic)
# dic = dict(enumerate(li,10)) # 上面的循环就是字典内部的本质,就是说这一句的本质就是上面的循环
# print(dic)
运行结果:
查找列表中符合条件元素:
要求:查找列表中元素,移除每个元素的空格,并查找以 a或A开头 并且以 c 结尾的所有元素。
li = ["alec", " aric", "Alex", "Tony", "rain"]
tu = ("alec", " aric", "Alex", "Tony", "rain")
dic = {'k1': "alex", 'k2': ' aric', "k3": "Alex", "k4": "Tony"}
注:以上三个任选其一即可。
列表:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
li = ["alec", " aric", "Alex", "Tony", "rain","abcd"]
for i in li:
i = i.strip()
#if 判断的顺序是从前到后的,如果第一个条件为 True 后面跟着 or 就表示自己成功就行了,就不会去判断后面的了
# 前面加一个括号,将这个括号当成了一个整体
if (i.startswith("a") or i.startswith("A")) and i.endswith("c"):
print(i)
运行结果:
元组:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
li = ("alec", " aric", "Alex", "Tony", "rain","abcd")
for i in li:
i = i.strip()
if (i.startswith("a") or i.startswith("A")) and i.endswith("c"):
print(i)
运行结果:
字典:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
dic = {'k1': "alex", 'k2': ' aric', "k3": "Alex", "k4": "Tony"}
for i in dic.values():
i = i.strip()
if (i.startswith("a") or i.startswith("A")) and i.endswith("c"):
print(i)
运行结果: