Kyligence Analytics Platform(KAP)大数据智能分析平台[1]是基于Apache Kylin构建的企业级数据仓库产品,能够在超大规模数据集上提供亚秒级分析能力,为业务用户、分析师及工程师提供简便、快捷的大数据分析服务。在继承Apache Kylin的高性能查询、易用建模,多协议支持、非侵入式架构等突出优点的同时,KAP在企业用户所关注的实施效率、安全可控、性能优化、自助式敏捷BI、系统监控等方面进行了全方位的创新,被誉为目前最为成熟的OLAP on Hadoop产品。
Azure[2]是微软的公有云平台,旨在向用户提供一个开放、灵活和可靠的企业级云计算平台。提供了各个方面极为广泛的服务,如计算、网络、存储、数据库、各类编程语言框架、大数据分析、机器学习等等。在本文中,将会侧重介绍KAP在Azure上所使用到的HDInsight[3]、Blob存储[4]以及虚拟网络服务[5]。
通过在Azure上提供KAP的部署和服务,可以帮助已经在Azure上开展业务的企业对其数据进行分析,加速企业发展和助力决策制定。企业数据无需在本地和云端反复流转,在云端产生同时在云端分析,快速便捷。同时释放了企业的IT运维压力,更多的将精力集中在核心产品上。
KAP和Azure
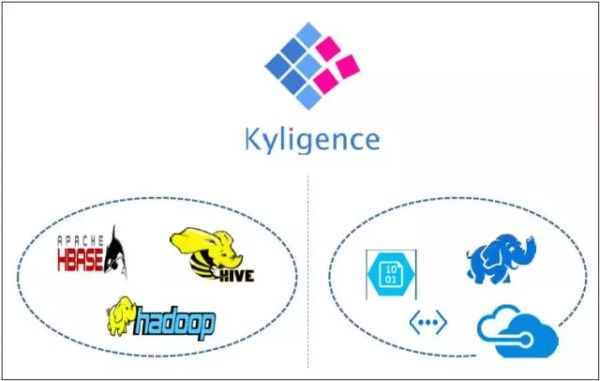
KAP构建于Hadoop之上,兼容开源Hadoop及主流商业Hadoop发行版,可运行在Apache Hadoop,Cloudera CDH,Hortonworks HDP,Microsoft HDInsight,AWS EMR等发行版和平台。图1左侧所示为KAP在本地部署的情况,主要依赖的组件包括Hadoop、Hive、HBase等。 如图1右侧所示,与本地部署不同的是,KAP在Azure上选择使用HDInsight作为底层依赖,同时利用Azure Blob存储和虚拟网络等云端功能。下面将对为何选择使用这些技术做出解释。
为什么使用HDInsight?
HDInsight是一种由云技术驱动的 Hadoop 发行版。这意味着 HDInsight 能够处理任何数量的数据,可按需将数据容量从数 TB 扩展至数 PB 级别。支持快速创建任意数量的节点,并只对实际使用的计算和存储收取费用。
在Azure上部署Hadoop集群,有两种选择:1)创建虚拟机,自行在虚拟机上部署所需的Hadoop发行版。2)使用HDInsight。相比较在虚拟机上自行安装Hadoop,使用HDInsight有如下优劣:
优势:
部署简单快速;
默认使用Azure Blob存储作为HDFS文件系统,无需考虑磁盘的运维。使用虚拟机,需要规划挂载多大的磁盘作为存储,容量不够时还需要处理扩容的问题;
支持动态伸缩;
由Azure提供99.9%SLA。
劣势:
Hadoop发行版为HDP,无其它可选;
默认安装时不可定制(安装后可以通过Ambari进行调整)。
为了更好的利用云计算的各项功能,我们建议直接使用HDInsight,而不是使用虚拟机手动部署Hadoop。
为什么使用Azure Blob存储?
Azure Blob 存储是一种稳健、通用的存储解决方案,它与 HDInsight 无缝集成。 将Azure Blob存储作为HDFS的底层文件系统,可以直接访问云端存储的数据,并将计算结果直接写入云端。
通过在 Azure 区域的存储帐户资源附近创建计算群集,使计算节点能够通过高速网络非常高效地访问 Azure Blob 存储中的数据。这种方式将计算和存储解绑,因此只在需要计算时才创建计算节点,其余时间只保留存储,从而节约了计算成本。
在 Azure Blob 存储而非 HDFS 中存储数据有几个好处:
数据重用和共享:
若HDFS 中的数据位于计算群集内,那么仅有权访问计算群集的应用程序才能通过 HDFS API 使用数据。而Azure Blob 存储中的数据可通过 HDFS API 或 Blob 存储 REST API 访问,因此,可使用大量应用程序(包括其他 HDInsight 群集)和工具来生成和使用此类数据。
数据存档:
通过在 Azure Blob 存储中存储数据,可以安全地删除用于计算的 HDInsight 群集而不会丢失用户数据。
数据存储成本:
与在 Azure Blob 存储中存储数据相比,在 DFS 中长期存储数据的成本更高,因为计算群集的成本高于Azure Blob 存储容器的成本。此外,由于数据无需在每次生成计算群集时重新加载,也节省了数据加载成本。
弹性向外扩展:
尽管 HDFS 提供了向外扩展文件系统,但缩放的容量将由创建的节点数量决定,更改缩放的过程也会更复杂。
异地复制:
可对 Azure Blob 存储容器进行异地复制。该功能可提供地理恢复和数据冗余功能,保障数据的安全。(但针对异地复制位置的故障转移将大大影响性能,并且会产生额外成本。 因此,建议仅在数据的价值值得你支付额外成本时才选择适当的地理复制。)
为什么使用Azure 虚拟网络?
Azure 虚拟网络 (VNet) 是网络在云中的表示形式。它是一种对网络进行的逻辑隔离。用户可以完全控制该网络中的 IP 地址池、DNS 设置、安全策略和路由表。还可以进一步将 VNet 细分成各个子网,并在子网内启动 Azure IaaS 虚拟机 (VM) 和云服务(PaaS 角色实例)。此外,也可以将多个虚拟网络连通,甚至连接到本地网络。HDInsight将所有节点部署在同一个VNet中,这样集群内部的通信,包括数据的传输都是在该内网中进行。虚拟网络外的节点无法与内部进行通信,因此集群的数据不会被窃取,从而保障了集群内的通信快速、安全和可靠。
KAP在Azure上的使用优化
云上环境与本地有所不同,KAP的使用也有一些相应需要注意的地方,下面总结了一些在Azure上使用KAP的经验。
KAP的部署:
KAP依赖于Hadoop、Hive和HBase,因此部署KAP的节点应当能够与HDInsight集群中的各个组件正常通信,且配置正确。可以通过在HDInsight相同的虚拟网络中创建虚拟机,然后手动安装或者复制对应版本的Hadoop、Hive和HBase到该机器中。这样虽然可行,但是却无法使用HDInsight集成的Ambari对KAP节点进行管理,这导致所有后续的配置更改也无法自动更新到KAP节点。熟悉Ambari的朋友可能已经想到,可以直接通过Ambari添加Client节点作为KAP的安装节点,这样可以保证新节点能够被Ambari统一管理。但是这个方法也是不可行的,因为HDInsight隐藏了部署新节点需要的软件源。最佳的方案是使用HDInsight的边缘节点(Edge Node)作为部署KAP的环境。边缘节点包含连通HDInsight集群的所有信息,各个组件也自动配置妥当,同时会被自动注册到Ambari服务器,能够被Ambari统一管理。创建新的边缘节点需要使用Azure Resource Manager方式部署,可以选择使用空边缘节点模版[6],也可以选择使用Kyligence公司提供的KAP模版。
加载数据:
KAP支持Hive和Kafka作为构建Cube的数据源,通常情况下我们需要将准备好的数据上传到集群中,然后在Hive中建表作为后续构建Cube的数据源。这对于那些数据原本就在云端的用户来说,如果分析集群在本地,或使用虚拟机磁盘作为HDFS存储,就需要先把本就在云端的数据下载到硬盘上,然后导入Hive中,这样既浪费了数据转移的时间,又带来了额外的传输成本。通过使用Azure Blob存储,将HDInsight集群和KAP节点部署在原数据相同的存储账号下,可以直接从Azure Blob存储在Hive中建表,KAP能够直接将其作为数据源进行Cube的构建。同样的,构建出来的Cube也可以直接存储到Azure Blob中。
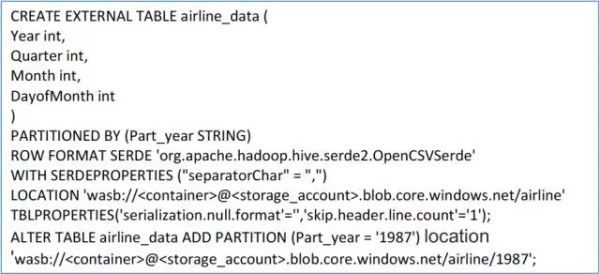
(使用Azure Blob数据直接创建Hive表)
利用本地文件系统加速构建:
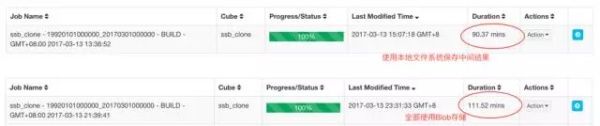
虽然使用Azure Blob存储带来了诸多便利,但是作为网络存储,性能上终归是要比硬盘读写要低。比如Azure Blob不能有效利用HDFS的缓存机制。在KAP构建Cube的过程中,存在一些中间结果,比如Hive的临时表、MapReduce任务的输出文件等。KAP支持将这些结果写在本地的文件系统中,提高IO效率,加速Cube的构建。
具体配置方式如下:

我们在相同的数据集上,对是否使用本地文件系统加速进行的对比测试,结果如下:
集群动态伸缩:
HDInsight提供的集群伸缩功能可以和KAP完美的结合起来。KAP对集群的使用主要分为两大部分:构建Cube和查询。Cube的构建(流式构建除外)通常是定期的任务,且需要较大的集群资源,而查询通常是不定时的,对资源没有过高的要求。利用KAP的这个特性,可以结合HDInsight的伸缩功能,在构建Cube时扩大集群规模,构建完毕后将集群收缩至能够满足查询效率的较小规模。这样极大的提高了资源利用率,降低了成本。
集群的快速删除与恢复:
经常会遇到这样一种场景,构建出来的Cube并不需要长期持续不断的被查询,可能只在一周的某一天或一个月的某几天需要使用。另一种类似的场景是,有些测试集群只在某些测试场景下需要,测试完毕后只需要保存构建出的Cube,集群并不需要保留。通过将KAP与HDInsight结合使用,我们可以实现构建完毕后完全删除集群,并在需要时恢复,所有构建的Cube不会丢失。
由于HDInsight不会保留Hive Metadata Store的数据库,所以在创建HDInsight时要指定外部的数据库,替换默认部署的数据库。删除时需要保留该数据库,以便在恢复后重新将Hive Metadata Store的数据库替换回来。KAP的所有必要数据无需手动备份及恢复,只需将定制的配置文件保留用于恢复即可。
本文对在Azure使用KAP所用到的技术作了简要介绍,并总结了在Azure上使用KAP的一些实践方法,利用这些方法能够降低用户的成本,提高工作效率,更好的利用KAP在云端进行大数据分析。希望能给读者带来一定的帮助。