一、环境安装
3台服务器的搭建,为了好描述我把服务器的地址分成hadoop1、hadoop2、hadoop3,
实际生产环境可以用域名来代替。
注意:配置里面尽量用域名,不要用IP,因为我曾经用IP配置出现了主机服务器联系不上从者服务器
集群规划:
| 主机名 | hdfs主服务器,即namenode | hdfs备用主服务器,也是namenode | hdfs从服务器,即datanode | zookeeper服务器 | yarn主服务器,即resourcemanager | yarn备用主服务器,resourcemanager | yarn从服务器,即nodemanager | hbase主服务器,即hmaster | hbase备用服务器,也是hmaster | hbase从服务器,即hslave |
|---|---|---|---|---|---|---|---|---|---|---|
| hadoop1 | 是 | 否 | 是 | 是 | 否 | 否 | 是 | 是 | 否 | 是 |
| hadoop2 | 否 | 是 | 是 | 是 | 是 | 否 | 是 | 否 | 是 | 是 |
| hadoop3 | 否 | 否 | 是 | 是 | 否 | 是 | 是 | 否 | 否 | 是 |
1、前提工作
1.1准备好服务器
如果是线上也就是有万网DNS域名解析的服务器的话忽略以下操作。
本地的话,自己修改本机的DNS域名解析文件,在各个linux服务器下的/etc/host文件中
vim /etc/host
追加
IP+域名
例如图1.1(a)

1.2相关安装包下载
jdk1.7
linux 准备3台服务器hadoop1、hadoop2、hadoop3
hadoop-2.7.3(http://apache.fayea.com/hadoop/common/)
zookeeper-3.4.5(http://apache.fayea.com/zookeeper/)
hbase-1.2.6(http://apache.fayea.com/hbase/)
1.3SSH免密码登录
由于hadoop各组件分布式集群,需要主机通过SSH协议启动从者服务器,设置免密码登录,减少工作量
1.3.1配置hadoop1到hadoop1、hadoop2、hadoop3的免密码登陆
#在hadoop1上生产一对钥匙
ssh-keygen -t rsa
输入上面的指令,然后一直按enter就行了
#将公钥拷贝到其他节点,包括自己
ssh-copy-id hadoop1
ssh-copy-id hadoop2
ssh-copy-id hadoop3
1.3.2配置hadoop2到hadoop1、hadoop2、hadoop3的免密码登陆
#在hadoop2上生产一对钥匙
ssh-keygen -t rsa
#将公钥拷贝到其他节点
ssh-copy-id hadoop1
ssh-copy-id hadoop2
ssh-copy-id hadoop3
2.安装配置zookeeper集群(在hadoop1服务器上)
2.1解压zookeeper安装包
假设在linux的/root下,那么zookeeper根目录是/root/zookeeper-3.4.5
2.2修改配置
2.2.1修改zoo.cfg配置文件
cd /root/zookeeper-3.4.5/conf/
cp zoo_sample.cfg zoo.cfg
vim zoo.cfg
修改:
dataDir=/root/zookeeper-3.4.5/tmp
添加:
dataLogDir=/root/zookeeper-3.4.5/log
server.1=hadoop1:2888:3888
server.2=hadoop2:2888:3888
server.3=hadoop3:2888:3888
2888是zookeeper相互通信的端口,3888是zookeeper与其他应用通信的端口,
2181是zookeeper客户端通信的端口
保存退出
2.2.2为该服务器上的zookeeper指定id
在zookeeper根目录创建一个tmp文件夹
mkdir /root/zookeeper-3.4.5/tmp
再创建一个空文件
touch /root/zookeeper-3.4.5/tmp/myid
最后向该文件写入ID
echo 1 > /root/zookeeper-3.4.5/tmp/myid
也就是为该服务器的zookeeper指定了id是1(其他服务器的id不能一样)
2.2.3将配置好的zookeeper拷贝到其他节点
scp -r /root/zookeeper-3.4.5/ hadoop2:/root/
scp -r /root/zookeeper-3.4.5/ hadoop3:/root/
注意:修改hadoop2、hadoop3对应/root/zookeeper-3.4.5/tmp/myid内容
hadoop2:
echo 2 > /root/zookeeper-3.4.5/tmp/myid
hadoop3:
echo 3 > /root/zookeeper-3.4.5/tmp/myid
启动zookeeper,看看部署成功没。
分别启动hadoop1、hadoop2、hadoop3服务器的zookeeper
/root/zookeeper-3.4.5/bin/zkServer.sh start
使用jps指令可以看到图2.2.3(a)

启动完毕,等待片刻,分别在hadoop1、hadoop2、hadoop3服务器执行命令
/root/zookeeper-3.4.5/bin/zkServer.sh status
查看zookeeper状态图2.2.3(b)与图2.2.3(c)

会出现其中一台是leader,也就是zookeeper的主服务器,而其他服务器都是follower则是从服务
器,就说明zookeeper分布式协调服务器启动成功了,就可以进行下一步,部署hadoop集群了。
3.安装Hadoop集群
我这里是用root权限,hadoop的目录路径为:
/root/hadoop
3.1配置HDFS
hadoop2.x所有的配置文件都在$HADOOP_HOME/etc/hadoop目录下
3.1.1将hadoop添加到环境变量中
vim /etc/profile
export JAVA_HOME=/usr/java/jdk1.7.0_55 #这是我的java路径,修改成你的java根目录路径就行了
export HADOOP_HOME=/root/hadoop #同样改成自己的hadoop根目录路径
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin
#hadoop2.x的配置文件全部在$HADOOP_HOME/etc/hadoop下
cd /root/hadoop/etc/hadoop
3.1.2修改hadoop-env.sh
vim hadoop-env.sh
找到:
export JAVA_HOME=XXX
改为:
export JAVA_HOME=/usr/java/jdk1.7.0_55
3.1.3修改core-site.xml
fs.defaultFS
hdfs://ns1
hadoop.tmp.dir
/root/hadoop/tmp
ha.zookeeper.quorum
hadoop1:2181,hadoop2:2181,hadoop3:2181
3.1.4修改hdfs-site.xml
3.1.4修改hdfs-site.xml
dfs.nameservices
ns1
dfs.ha.namenodes.ns1
nn1,nn2
dfs.namenode.rpc-address.ns1.nn1
hadoop1:9000
dfs.namenode.http-address.ns1.nn1
hadoop1:50070
dfs.namenode.rpc-address.ns1.nn2
hadoop2:9000
dfs.namenode.http-address.ns1.nn2
hadoop2:50070
dfs.namenode.shared.edits.dir
qjournal://hadoop1:8485;hadoop2:8485;hadoop3:8485/ns1
dfs.journalnode.edits.dir
/root/hadoop/journaldata
dfs.ha.automatic-failover.enabled
true
dfs.client.failover.proxy.provider.ns1
org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider
dfs.ha.fencing.methods
sshfence
shell(/bin/true)
dfs.ha.fencing.ssh.private-key-files
/root/hadoop/.ssh/id_rsa
dfs.ha.fencing.ssh.connect-timeout
30000
3.1.5修改mapred-site.xml
mapreduce.framework.name
yarn
3.1.6修改yarn-site.xml
yarn.resourcemanager.ha.enabled
true
yarn.resourcemanager.cluster-id
yrc
yarn.resourcemanager.ha.rm-ids
rm1,rm2
yarn.resourcemanager.hostname.rm1
hadoop2
yarn.resourcemanager.hostname.rm2
hadoop3
yarn.resourcemanager.zk-address
hadoop1:2181,hadoop2:2181,hadoop3:2181
yarn.nodemanager.aux-services
mapreduce_shuffle
3.1.6修改slaves
(slaves是指定子节点的位置,因为要在hadoop1上启动HDFS、在hadoop2启动yarn,所以hadoop1上的slaves文件指定的是datanode的位置,hadoop2上的slaves文件指定的是nodemanager的位置)
vim slaves
在文件中追加以下内容
hadoop1
hadoop2
hadoop3
3.1.7拷贝配置好的hadoop到其他服务器
scp -r /root/hadoop/ hadoop2:/root/
scp -r /root/hadoop/ hadoop3:/root/
3.2启动hadoop集群
3.2.1启动journalnode
/root/hadoop/sbin/hadoop-daemon.sh start journalnode
#运行jps命令检验,hadoop1、hadoop2、hadoop3上多了JournalNode进程
这一步是为了可以格式化namenode
3.2.2格式化hdfs
#在hadoop1上执行命令:
hdfs namenode -format
#格式化后会在根据core-site.xml中的hadoop.tmp.dir配置生成个文件,这里我配置的是/root/hadoop/tmp,然后将/root/hadoop/tmp拷贝到hadoop2的/root/hadoop/下。
scp -r /root/hadoop/tmp/ hadoop2:/root/hadoop/
#也可以这样,建议hdfs namenode -bootstrapStandby
3.2.3格式化ZKFC(在hadoop1上执行即可)
hdfs zkfc -formatZK
3.2.4启动HDFS(在hadoop1上执行)
/root/hadoop/sbin/start-dfs.sh
3.2.5启动YARN
(#####注意#####:是在hadoop2上执行start-yarn.sh,如何可以的话把namenode和resourcemanager分开,不要放同一个服务器中,因为他们都要占用大量资源,他们分开了就要分别在不同的机器上启动)
在hadoop2上执行
/root/hadoop/sbin/start-yarn.sh
然后在hadoop3上执行
/root/hadoop/sbin/yarn-daemon.sh start resourcemanager
3.2.6查看是否成功
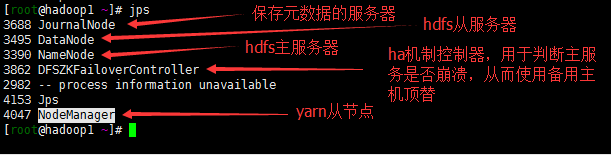
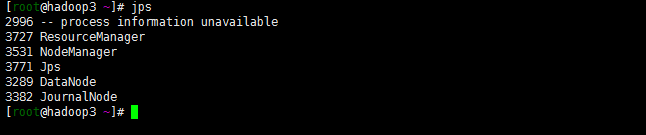
使用jps查看相关进程(图3.2.6(a,b,c))
hadoop1:
hadoop2:

hadoop3:
访问 http://hadoop1:50070
看到active,说明这是活跃的namenode主服务器

访问http://hadoop2:50070
看到这个是standby,说明它是备胎,hadoop1的namenode挂掉,hadoop2就会顶上

如果看到图3.2.6(f)

说明hdfs集群成功
4.HBASE集群,集成到HADOOP中
这一步在hadoop1上执行
4.1修改HBASE配置
配置hbase集群,要修改3个文件(首先zk集群已经安装好了)
4.1.1把hadoop配置文件复制过来
我的hbase路径是/root/hbase/
注意:要把hadoop的hdfs-site.xml和core-site.xml 拷贝到/root/hbase/conf下
4.1.2修改hbase-env.sh
找到
export JAVA_HOME=/usr/java/jdk1.7.0_55 #改成你的jdk根目录
export HBASE_CLASSPATH=/root/hadoop/etc/hadoop #改成你的hadoop目录下的etc/hadoop目录
export HBASE_LOG_DIR=/root/hbase/logs #设置hbase的日志所在目录
export HBASE_MANAGES_ZK=false #因为默认会使用hbase自带的zookeeper,需要告诉hbase使用外部的zookeeper,也就是第一步配置好的zookeeper
4.1.3修改hbase-site.xml
该配置文件是hbase核心配置文件
vim hbase-site.xml
hbase.rootdir
hdfs://ns1/hbase
hbase.cluster.distributed
true
hbase.zookeeper.quorum
hadoop1:2181,hadoop2:2181,hadoop3:2181
4.1.3修改regionservers
该文件决定了hbase的从节点
vim regionservers
追加以下内容
hadoop1
hadoop2
hadoop3
4.1.4拷贝hbase到其他节点
scp -r /root/hbase/ hadoop2:/root/
scp -r /root/hbase/ hadoop3:/root/
将配置好的HBase拷贝到每一个节点并同步时间(hbase每个节点的时间不要大于30秒)。
4.2启动hbase
注意zookeeper和hadoop必须启动着,因为hbase依赖zookeeper进行集群,而我们的配置文件是使用外部的zookeeper,另外hbase是以hdfs作为分布式文件系统
启动hbase,在主节点上运行:
/root/hbase/bin/start-hbase.sh
4.2.1为保证集群的可靠性,要启动多个HMaster(在hadoop2上执行)
/root/hbase/bin/hbase-daemon.sh start master
4.2.1通过浏览器访问hbase管理页面
hadoop1:16010

说明hbase启动成功,就可以使用hbase shell来当成数据库使用
注意:
搭建hadoop相关集群,需要把防火墙给关闭了。因为有大量通讯端口,和mapreduce会产生一些随机端口,所以hadoop的搭建需要关闭防火墙,关闭防火墙就出现安全性问题,所以hadoop适合在内网中使用!
非要启动防火墙的话,需要开放其中大量的端口防火墙白名单