刘群:华为诺亚方舟NLP预训练模型工作的研究与应用 | AI ProCon 2019
演讲嘉宾 | 刘群(华为诺亚方舟实验首席科学家)
编辑 | Jane
出品 | AI科技大本营(ID:rgznai100)
预训练语言模型对自然语言处理领域产生了非常大的影响,在近期由CSDN主办的 AI ProCon 2019 上,自然语言处理技术专题邀请到了华为诺亚方舟实验首席科学家刘群分享了华为诺亚方舟实验室在预训练语言模型研究与应用。
他从以下三个方面
介绍了他们的工作:
一是刚发布的中文预训练语言模型——哪吒;
二是实体增强预训练语言模型——ERINE;
三是预训练语言模型——乐府。
最后,刘群对预训练语言模型研究与应用做了展望。下一步他们
希望研究更好、更强大的预训练语言模型,融入更多的知识,同时跟语音和图像也能够有所结合;
此外,也希望将这些预训练模型能应用到更多领域;
最后,模型压缩和优化方面做一些工作也能在终端落地,在华为自研的AI芯片上实现和优化。

以下为刘群的演讲内容实录,AI科技大本营(ID:
rgznai100)整理:
一、华为诺亚方舟在预训练模型的工作
预训练语言模型本身就是神经网络语言模型,它有哪些特点?第一,可以使用大规模无标注纯文本语料进行训练;第二,可以用于各类下游NLP任务,不是针对某项定制的,但以后可用在下游NIP任务上,你不需要为下游任务专门设计一种神经网络,或者提供一种结构,直接在几种给定的固定框架中选择一种进行 fine-tune,就可以从而得到很好的结果,这是预训练模型特别厉害的一点。
预训练语言模型有两个大类型。
一类是Encoder,用于自然语言理解,输入整个文章,用于自然语言理解;另一类是Decoder,是解码式的,用于自然语言生成,只能来看到已经生成的内容,看不到没有生成的内容,这两类模型有所区别。

从上面的图中我们可以看出,近两年预训练模型的发展非常快。从很早的Word2Vec、之后ULMFiT、CoVe、Elmo、OpenAI GPT随之出现,最后影响最大的是Bert,BERT之后有OpenAI Gpt-2。后面我又补充了 GPT-2 8B、MegatronLM、RoBERTa、Ernie-Tsinghua、Ernie-Baidu、XLNet、UNILM、MASS、MT-DNN、XLM,最近有几个模型非常有意思,比如 Ernie、Roberta,然后是Megatronlm,做到了GPT-2 8EB。
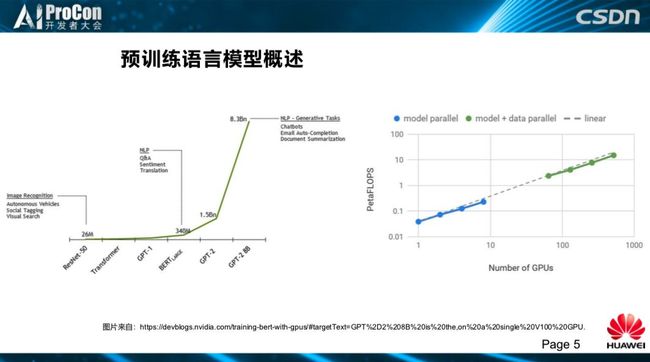
这是模型的参数大小,跟早期的 ResNet相比(视觉模型),我们看到GPT1 是 100M,BERT large是340M,GPT2是 1.5BN,GPT-2 8B是 8.3BN。再到计算量GPU的使用数量,可以看出大家都在拼数据、拼算力。
华为诺亚方舟实验室在预训练语言模型研究方面,内部重现了 Google Bert-base和Bert-large的实验;利用BERT的代码,实现了OpenAI GPT-2模型;实现基于GPU多卡多机并行训练,并且对训练过程进行了优化,提高了训练效率。
这些工作稍微有一点复杂,没有那么简单。我们华为内部有自己的云,有一些自己的配置,它是包装了一层的,一些源代码我们没有办法直接用,需要做一些改进。涉及很多细节和技巧,在开源的代码中是找不到的,我们做了很多尝试,现在在几百个上千个GPU跑起来没有问题。

其次,对模型细节进行了多方面的改进。
这是尝试很多方法后得到的结果,我们拿出有效的部分。此外,我们还尝试了很多模型压缩优化方案。我们希望这些成果能真正部署在我们的产品上,特别是手机上。虽然华为做手机已经很好了,但是这种GPT模型太大了,想直接用在手机上还是做不到,我们尝试很多压缩的方法,现在还没有完全能够压缩到手机上,但是已经能够压缩比较小了。
在模型应用方面做了很多有意思的事情,预训练语言模型特别好,有很多应用。首先是古诗的生成;其次是对话生成,香港科技大学有个冯老师做的一个对话生成很好;此外还可以应用于对话理解中,理解任务型的对话的意图,用了预训练语言模型都有很好的效果大的改变;在多标签分类方面,我们也做了很多大的实验;应用于推荐和搜索中也是如此,我们在其中做了一些很有意思的工作,阿里在这方面也有很好的工作成果,预训练模型对这些工作确实都有很大的改进。除了谈到的这些,还有其他的工作我们也正在尝试去做。
二、哪吒:诺亚方舟实验室的中文预训练语言模型
接下来,为大家介绍几个具体的工作。
哪吒,是我们推出的中文预训练语言模型。
这篇文章,我们9月4号公布出来的,大家可以在arXiv上下载论文,之后会开放源码和模型数据,目前在公司内部申请流程中。
论文地址:
https://arxiv.org/abs/1909.00204

预训练语言模型科学家有很风趣的一面,大家取名大多源于动画人物,比如ELMo、BERT、ERNIE等。哪吒有三头六臂,力大无比,我们也希望预训练语言模型可以解决不同的任务,基于这样一个期待我们取名哪吒。
我们重现了Google Bert-base和Bert-large的实验,并且在华为云上训练和运行成功;同时在华为云上的训练应用了多卡多机的数据并行,暂时只实现了数据并行,模型并行我们正在做还没有完全实现;此外实现了混合精度训练,这些都是很有必要的;最后,使用了Lamb优化器,这也是一个非常大的改进,这四点都是在模型训练优化方面的具体工作,都是非常有必要的。
另外,在哪吒模型中,我们还有两个模型改进的工作,一是函数式相对位置编码,二是实现全词覆盖。
现在,我们神经网络的模型无论是做语言模型还是在机器翻译任务中,都会用到一个词表,在 Softmax 时,每个词都要尝试比较一下,词表便成为了运算的瓶颈,每次运算的时候,每出来一个词要都在词表中走一遍,一般词表包含几万个词,机器翻译经常遇到六七万个词,这个规模很大,但七八万个词对自然语言处理仍然无法完全覆盖,神经网络的解决办法就是把它切成subword。我们在BERT里面,覆盖一个词预测一个词,最早BERT覆盖一个subword,一个词盖住一半,猜另一半,这就变得很容易了,后来提出了全词覆盖,这样预测整个词运算难度有所增加了,我认为这是一个方向,后来很多工作都是增加难度,一开始的难度太简单了。我们现在也是简单采用了全词覆盖。
第二个改进工作是我们使用的函数式相对位置编码。
位置编码跟最早我们做自然语言处理用的循环神经网络,这类模型中位置是从左到右一个词一个词进行编码的,位置信息自然是保留了,但是在Transformer 中,每个词跟每个词互相的都要Attending,并不知道每个词离自己的距离有多远,这样把每个词平等的对待,是存在一些问题的。继而谷歌引入了位置编码。位置编码的想法最早是 Facebook 提出引用的。位置编码有函数式和参数式两种,函数式通过定义函数直接计算就可以了。参数式中位置编码涉及两个概念,一个是距离,表示这个词离“我”有多远,二是维度,Word Embedding 一般有几百维,比如 768 维,每一维有一个值,通过位置和维度两个参数来确定一个位置编码的值。
一种做法就是采用函数式的。Transformer最早只考虑了绝对位置编码,这是Transformer提出来的,绝对位置编码,而且是函数式的,在文章后面也提到不一定采用函数式,还可以采用参数式。后来BERT的提出就使用了参数式,而参数式训练会受收到句子长度的影响,BERT一开始训练的句子最长为 512,如果只训练到 128 长度的句子,在 128~520之间的位置参数就得不到,所以必须要训练更长的语料来确定这一部分的参数。
我们尝试了各种做法,我们尝试各种组合:参数式的、函数式的,绝对位置编码,相对位置编码,相对位置编码是其他人提出来的,在TransformerXL、XLNet 中被采用,我们借用了这个方法。我们比他还更简单,他们设了两个超调参,我们去掉了,直接用参数效果很好。相对位置编码,计算相对位置距离有多远,这个值可能是正的也可能是负的。相对来说这个方法效果比较显著,效果好一些。

这是哪吒和相关工作的实验对比。结果最好的模型是百度的Base模型,哪吒模型总体与百度差不多,可以看到CMRC值还差一点,我们跑出来的Base模型比他们公布的要差,可能在数据处理上还有一点不太一样,别的数据差别都不大。
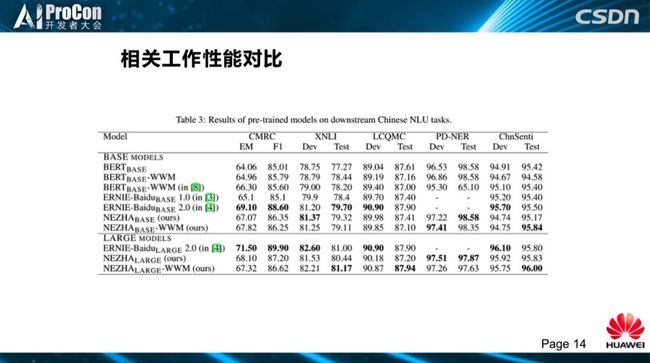
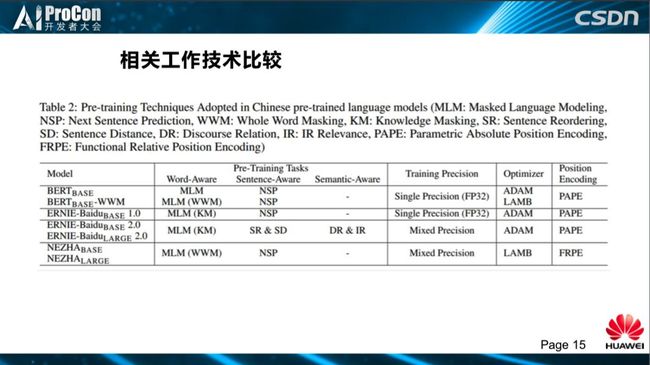
这是Bert的全词覆盖模型,百度 ERNIE1.0,百度 ERNIE2.0的 base和large模型,及我们自己的base、large模型实验对比。任务方面,百度模型中引用了KM,百度在 Pretraining Tasks探索上做了很多工作,另外,源于百度自己拥有的“天然”数据,在几个新任务上也做出了自己的特色,如句子的距离,两个句子之间是什么关系,判断中间词是否为连接词“所以”、“因果”、“因为”等。另外,我们看到训练精度方面,图中显示了百度2.0和我们对应的混合编码,引用了lamb优化,位置编码都是用的 PAPE,参数式的绝对位置编码,我们使用函数式的相对位置编码。
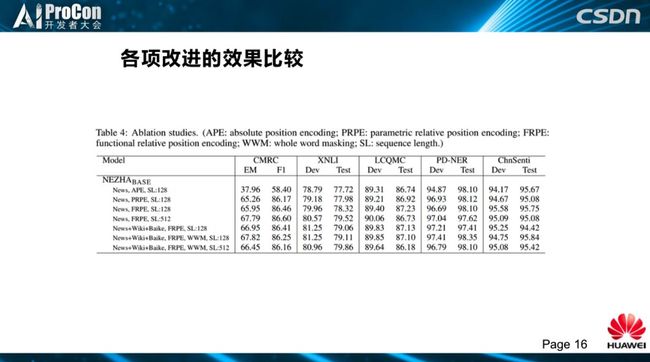
我们把自己的改进工作也做了比较。绝对位置编码和相对位置编码改进效果比较大;函数式的位置编码要比参数式稳定;此外,我们加了语料库、全词覆盖的效果都提升,每个工作都有改进成果。
三、Ernie:实体表示增强的预训练语言模型,为语言理解注入外部知识

我们的 ERNIE 不同于百度的 ERNIE 工作,这个工作主要是和清华大学老师团队合作做的。这项工作 初衷是想把知识图谱的信息引入到BERT模型中。通过下面的例子解释一下
论文地址:
https://arxiv.org/abs/1905.07129
Github地址:
https://github.com/thunlp/ERNIE
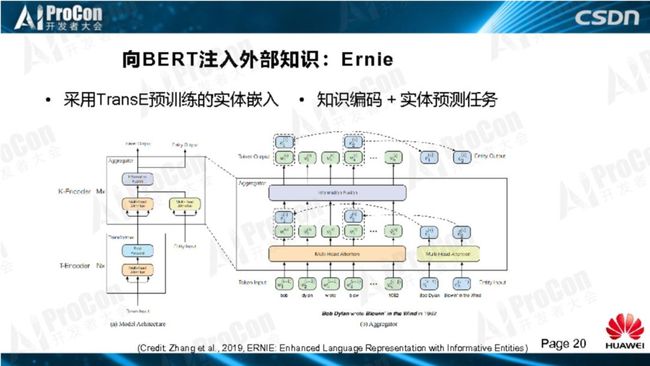
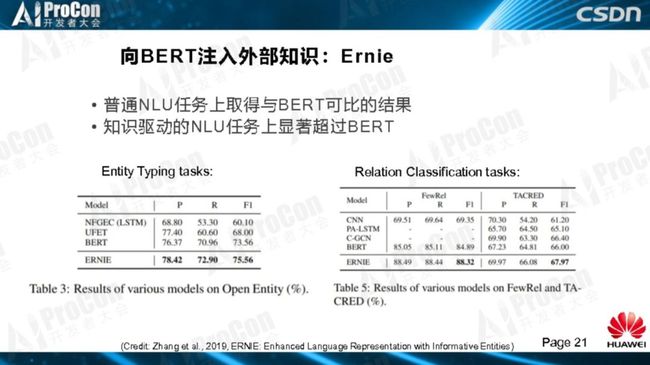
“Bob Dylan wrote Blowin in the Wind in1962,and wrote Chronicles:Volume One in 2004”,同一个人写了两个作品,一是写了一本书,身份是作家,另一作品是以作曲人的身份写了一首歌曲,将知识图谱融入语义关系判断是非常有用的,没有这两个相关的知识,我们不可能做出准确的身份判断。在标准BERT、Transformer的结构中,引入 Entity input,把知识图谱的信息和Bert如何在一块融合的过程。我们在处理各种任务的结果中发现,在普通NLU任务上与BERT没有太大区别,保证了BERT的基本能力;在知识驱动的NLU任务上显著超过了Bert。
四、乐府:基于GPT模型的中文古诗词生成系统
介绍一下乐府,大家可以试一下微信的小程序,我们跟华为云合作的,大家可以下载这个小程序,可以在微信里面尝试。

论文地址:
https://arxiv.org/abs/1907.00151
简单介绍一下我们是如何做的。我们基于BERT代码自己开发了自己的 GPT 模型,预训练阶段包含2.35亿句子新闻语料,Fine-tune 中使用绝句和律诗25万,词2万,词规模小多了,词比较难,词的语料少,长度又长,难度又大,对联用了70万。

生成策略采取Top-K随机取样。这个模型我们没有用任何人工编制的诗词的韵律、平仄、句子长度的规则信息,全部让模型自动去学。在Fine-tune中,把每组诗词变成(如下图所示)格式:“五言绝句(格式)静夜思(标题),床前明月光......”,把所有的古诗词用这种格式送给GPT模型,这是一个非常简单的处理,然后我们就可以作诗。
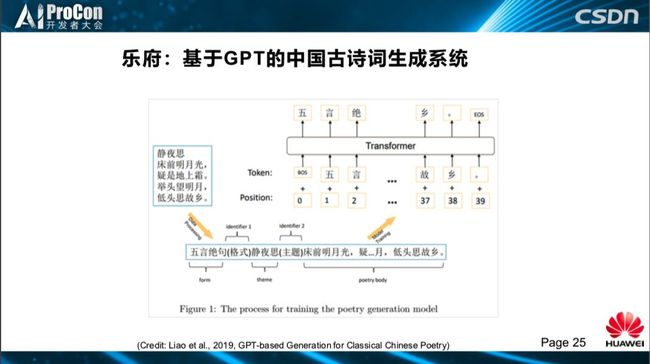
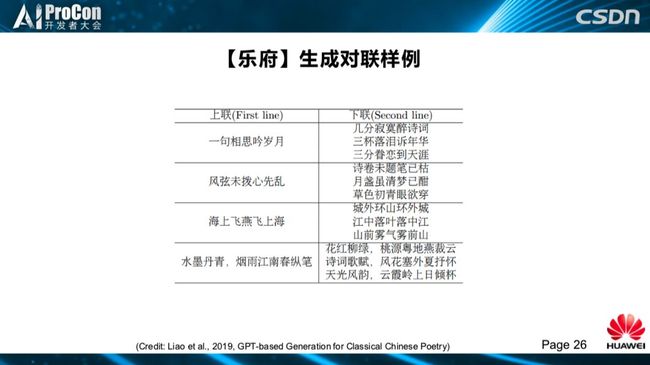
自己输入一个格式,输入一个主题、标题,然后就可以作出诗词。(如下图所示)是我们生成的对联,对联不算诗词,我们为了简化,都算作古诗词生成系统的能力。你输入一个上联,它可以对很多的下联:“海上飞燕飞上海”对“城外环山环外城”、“江中落叶落中江”,这是自动学习到词的重叠用法,还可以把词重新组合成一种新的模式,你出上联,它完全可以对下联,GPT这种格式学习的非常好。
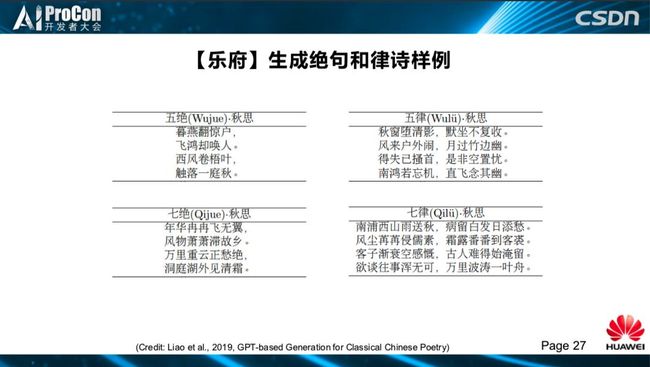
这是我们生成绝句和律诗的样例,有五绝、七绝、五律、七律。这个系统发布以后,很多人就来尝试,还有有很多例子,如《乐游西湖》、《伊美赞》、《闻秋虫有感》等作品,得到了很多好评,很多网友说超越一般人的水平,超越90%古风圈诗歌的水平。
关于这个问题的讨论,我在微博里面有人解释了:说到“诗词的问题,说穿了诗词就是文字游戏,AI文字游戏玩得比较好,实际上它不懂逻辑和意境的,因为诗词需要脑部的,太简略了,只要词语分析的好,加上网友脑部大家觉得有一些意境。诗人写诗以文达意,读者望文生义,本质是双方思想层面的沟通与升华”。
通过乐府所作的诗词,我们也观察到一些现象:
-
总体上句子长度、押韵、平仄都不错,但严格检查起来还是有一些不符合的地方。
-
扣题不错,能够找到跟主题相关的词语写进诗里,使人感觉总体上形成一定的意境。
-
有一定的起承转合,最后一句通常会点题。
-
偶尔出现一些非常好的金句。
-
七言诗比五言诗效果好。
-
但是作词成功率比较低,目前成果率在 70%左右,可能受语料较少因素影响,词的长度都很长,所以它不容易学好。
-
另外,也会犯一些逻辑错误;基于典型的GPT模型,我们都知道作诗的质量跟标题关系比较大,传统古诗中比较常见的主题容易作出好诗,纯现代主题作出的诗相对质量较低。
五、展望
总结一下我们在预训练语言模型方面做的一系列的工作,重现了主流的预训练语言模型,在华为云上实现了大规模的并行训练并做了针对性得到的优化。我们对预训练语言模型技术细节进行深入的研究,推出了中文预训练语言模型的哪吒,与清华大学合作我们推出了ERNIE。
下一步我们希望研究更好、更强大的预训练语言模型,融入更多的知识,同时跟语音和图像也能够有所结合;此外,也希望将这些预训练模型能应用到更多领域;最后,模型压缩和优化方面做一些工作也能在终端落地,在华为自研的AI芯片上实现和优化。
华为推出自己的芯片,有好几个型号消耗,有的在云端、服务器端、手机端的,我们跟华为海思合作,把预训练语言模型在华为自己芯片上实现,希望以后大家可以在手机上看到我们自己的预训练语言模型。
六、现场互动
提问:
我们知道BERT和Transformer是比较新的技术,还有很多值得改进的点,对于BERT来说存在很多继续优化使它变得更强大的方向,您更看好哪些值得往这个方向投入一些资源?ERNIE把结构化的知识怎么引入到BERT里面,是不是让它做知识图谱更好?
刘群:
Transformer不只一年,时间更长一点,BERT近一年。Transformer非常好,非常强大,但是用起来还是有问题的。一个例子就是说长度,BERT一般处理1000字,1500字,真正文本比这个更长,这个问题要怎么处理?我们和清华合作的ERNIE,只是做了一点一点的工作,实际上还差很多。我刚才举了例子,现在的模型还是缺乏常识。即使这些已经很强大了,它还是不能真正理解,怎么能够使一个真正理解语义,还是有很长的路要走,现在还没有做到。
提问:
您举的唐诗
例子,现在有没有更加符合中文应用这类生成,因为GPT2不开放完全模型,会不会造成伦理安全问题?
刘群:
我觉得GPT2这个事情上,我不知道它是真的担心还是有点炒作的意思,这个规模的语言模型不是太大,大家都可以做的,开放出来也没什么。应用的话,我现在还不知道工业界大规模的应用,故事生成很有用的,GPT首先拿出来是一个故事生成。比如说简单的新闻生成,足球赛的报道,只要把足球赛的参数几分钟谁踢进去一个球,每个人信息多少,把参数输入进去形成足球赛的报道,财经的新闻,生成新闻完全可以做到,甚至取代人工,我还没有看到用GPT做这个事情,文本生成这个事情产业上已经有的,这是肯定没有问题的。

提问:现在有很多人把规则和深度学习合在一块用,这是发展趋势吗?比如我们自己想做研究,在做药物不良反应关系过程中发现正向和负向用向量方法识别出来不是特别好,有可能指向性不是特别强,我们想加上一些规则、权重找到指向,这个是不是很好的方式。
刘群:
把规则和神经网络结合起来,我觉得这是很好的未来方向,具体怎么做,有很多不同的做法,这方面的工作并不少见,已经有不少应用了。加知识,读写规则可能是有用的,大家做正则,正则这个东西简单直接好用,神经网络学一个正则出来不太容易学好的。规则和神经网络结合起来这是有意思的问题,这是值得研究的,我相信这两者的结合肯定会有用的,因为它们是互补的东西。
提问:
最近几年人工智能比较热,所以有很多其他技术方向的人也对这个领域产生了兴趣的人,如果想尽快切入到这个领域来做一些事情,您有什么建议?
刘群:
我觉得现在的学习容易多了,我们当年学的一大堆算法,现在都不学了。现在大家都是从神经网络入手,看源代码,教材、视频,有很多资源,只要花点时间,都不是太大问题,数据也很多。我当时做分词的时候,全世界都没有分词系统可以用,什么事情都要重新做,我并不觉得这是很大的问题。
我说点个人经验,大家做学生的时候,特别是现在做深度学习的研究,容易犯的毛病,就是看结果,看一个评测什么值,然后直接调参,这是不好的现象,一定要看数据,一定要分析数据,评测值不好的时候,看看到底为什么不好,拿一个个的个体去看,一定要分析你的数据,只看结果不看问题,很难做好。这是我的建议。
AI ProCon 2019 大会官网,可获取大会演讲PPT、现场照片及图文直播等信息https://aiprocon.csdn.net/m/topic/ai_procon
(*本文为 AI科技大本营原创文章,
转
载请微
信联系 1092722531
)
◆
精彩推荐
◆
2019 中国大数据技术大会(BDTC)再度来袭!豪华主席阵容及百位技术专家齐聚,15 场精选专题技术和行业论坛,超强干货+技术剖析+行业实践立体解读,深入解析热门技术在行业中的实践落地。
即日起,
限量 5 折票
开售,数量有限,扫码购买,先到先得!

推荐阅读
估值被砍700亿美元后,Waymo发重磅公开信:即将推出全自动驾驶打车服务
CVPR 2019论文阅读:Libra R-CNN如何解决不平衡对检测性能的影响?
多数编程语言里的0.1+0.2≠0.3?
人体姿态估计的过去、现在和未来
图灵奖得主Bengio再次警示:可解释因果关系是深度学习发展的当务之急
技术领域有哪些接地气又好玩的应用?
Python新工具:用三行代码提取PDF表格数据
国产嵌入式操作系统发展思考
2019 年诺贝尔物理学奖揭晓!三得主让宇宙“彻底改观”!
公链故事难再续?
你点的每个“在看”,我都认真当成了AI