JVM有几种常量池
主要分为: Class文件常量池、运行时常量池,全局字符串常量池,以及基本类型包装类对象常量池。
Class文件常量池
class文件是一组以字节为单位的二进制数据流,在java代码的编译期间,我们编写的java文件就被编译为.class文件格式的二进制数据存放在磁盘中,其中就包括class文件常量池。 class文件中存在常量池(非运行时常量池),其在编译阶段就已经确定,jvm规范对class文件结构有着严格的规范,必须符合此规范的class文件才能被jvm任何和装载。为了方便说明,我们写个简单的类
class JavaBean{
private int value = 1;
public String s = "abc";
public final static int f = 0x101;
public void setValue(int v){
final int temp = 3;
this.value = temp + v;
}
public int getValue(){
return value;
}
}
通过javac命令编译之后,用javap -v 命令查看编译后的文件:
class JavaBasicKnowledge.JavaBean
minor version: 0
major version: 52
flags: ACC_SUPER
Constant pool:
#1 = Methodref #6.#29 // java/lang/Object."":()V
#2 = Fieldref #5.#30 // JavaBasicKnowledge/JavaBean.value:I
#3 = String #31 // abc
#4 = Fieldref #5.#32 // JavaBasicKnowledge/JavaBean.s:Ljava/lang/String;
#5 = Class #33 // JavaBasicKnowledge/JavaBean
#6 = Class #34 // java/lang/Object
#7 = Utf8 value
#8 = Utf8 I
#9 = Utf8 s
#10 = Utf8 Ljava/lang/String;
#11 = Utf8 f
#12 = Utf8 ConstantValue
#13 = Integer 257
#14 = Utf8
#15 = Utf8 ()V
#16 = Utf8 Code
#17 = Utf8 LineNumberTable
#18 = Utf8 LocalVariableTable
#19 = Utf8 this
#20 = Utf8 LJavaBasicKnowledge/JavaBean;
#21 = Utf8 setValue
#22 = Utf8 (I)V
#23 = Utf8 v
#24 = Utf8 temp
#25 = Utf8 getValue
#26 = Utf8 ()I
#27 = Utf8 SourceFile
#28 = Utf8 StringConstantPool.java
#29 = NameAndType #14:#15 // "":()V
#30 = NameAndType #7:#8 // value:I
#31 = Utf8 abc
#32 = NameAndType #9:#10 // s:Ljava/lang/String;
#33 = Utf8 JavaBasicKnowledge/JavaBean
#34 = Utf8 java/lang/Object
可以看到这个命令之后我们得到了该class文件的版本号、常量池、已经编译后的字节码(这里未列出)。既然是常量池,那么其中存放的肯定是常量,那么什么是“常量”呢? class文件常量池主要存放两大常量:字面量和符号引用。
1) 字面量: 字面量接近java语言层面的常量概念,主要包括:
- 文本字符串,也就是我们经常申明的: public String s = "abc";中的"abc"
#9 = Utf8 s
#3 = String #31 // abc
#31 = Utf8 abc
- 用final修饰的成员变量,包括静态变量、实例变量和局部变量
#11 = Utf8 f
#12 = Utf8 ConstantValue
#13 = Integer 257
这里需要说明的一点,上面说的存在于常量池的字面量,指的是数据的值,也就是abc和0x101(257),通过上面对常量池的观察可知这两个字面量是确实存在于常量池的。
而对于基本类型数据(甚至是方法中的局部变量),也就是上面的private int value = 1;常量池中只保留了他的的字段描述符I和字段的名称value,他们的字面量不会存在于常量池:
2). 符号引用
符号引用主要设涉及编译原理方面的概念,包括下面三类常量:
- 类和接口的全限定名,也就是Ljava/lang/String;这样,将类名中原来的"."替换为"/"得到的,主要用于在运行时解析得到类的直接引用,像上面
#5 = Class #33 // JavaBasicKnowledge/JavaBean
#33 = Utf8 JavaBasicKnowledge/JavaBean
- 字段的名称和描述符,字段也就是类或者接口中声明的变量,包括类级别变量和实例级的变量
#4 = Fieldref #5.#32 // JavaBasicKnowledge/JavaBean.value:I
#5 = Class #33 // JavaBasicKnowledge/JavaBean
#32 = NameAndType #7:#8 // value:I
#7 = Utf8 value
#8 = Utf8 I
//这两个是局部变量,值保留字段名称
#23 = Utf8 v
#24 = Utf8 temp
可以看到,对于方法中的局部变量名,class文件的常量池仅仅保存字段名。
- 方法中的名称和描述符,也即参数类型+返回值
#21 = Utf8 setValue
#22 = Utf8 (I)V
#25 = Utf8 getValue
#26 = Utf8 ()I
运行时常量池
运行时常量池是方法区的一部分,所以也是全局贡献的,我们知道,jvm在执行某个类的时候,必须经过加载、链接(验证、准备、解析)、初始化,在第一步加载的时候需要完成:
- 通过一个类的全限定名来获取此类的二进制字节流
- 将这个字节流所代表的静态存储结构转化为方法区的运行时数据结构
- 在内存中生成一个类对象,代表加载的这个类,这个对象是java.lang.Class,它作为方法区这个类的各种数据访问的入口。
类对象和普通对象是不同的,类对象是在类加载的时候完成的,是jvm创建的并且是单例的,作为这个类和外界交互的入口, 而普通的对象一般是在调用new之后创建。
上面的第二条,将class字节流代表的静态存储结构转化为方法区的运行时数据结构,其中就包含了class文件常量池进入运行时常量池的过程,这里需要强调一下不同的类共用一个运行时常量池,同时在进入运行时常量池的过程中,多个class文件中常量池中相同的字符串只会存在一份在运行时常量池,这也是一种优化。
运行时常量池的作用是存储java class文件常量池中的符号信息,运行时常量池中保存着一些class文件中描述的符号引用,同时在类的解析阶段还会将这些符号引用翻译出直接引用(直接指向实例对象的指针,内存地址),翻译出来的直接引用也是存储在运行时常量池中。
运行时常量池相对于class常量池一大特征就是具有动态性,java规范并不要求常量只能在编译时才产生,也就是说运行时常量池的内容并不全部来自class常量池,在运行时可以通过代码生成常量并将其放入运行时常量池中,这种特性被用的最多的就是String.intern()。
全局字符串常量池
1.Java中创建字符串对象的两种方式
一般有如下两种:
String s0 =”hellow”;
String s1=new String (“hellow”);
第一种方式声明的字面量hellow是在编译期就已经确定的,它会直接进入class文件常量池中;当运行期间在全局字符串常量池中会保存它的一个引用.实际上最终还是要在堆上创建一个”hellow”对象,这个后面会讲
第二种方式方式使用了new String(),也就是调用了String类的构造函数,我们知道new指令是创建一个类的实例对象并完成加载初始化的,因此这个字符串对象是在运行期才能确定的,创建的字符串对象是在堆内存上。
因此此时调用System.out.println(s0 == s1);返回的肯定是flase,因此==符号比较的是两边元素的地址,s1和s0都存在于堆上,但是地址肯定不相同。
我们来看几个常见的题目:
String s1 = "Hello";
String s2 = "Hello";
String s3 = "Hel" + "lo";
String s4 = "Hel" + new String("lo");
String s5 = new String("Hello");
String s7 = "H";
String s8 = "ello";
String s9 = s7 + s8;
System.out.println(s1 == s2); // true
System.out.println(s1 == s3); // true
System.out.println(s1 == s4); // false
System.out.println(s1 == s9); // false
String s1 = "Hello",到底有没有在堆中创建对象?
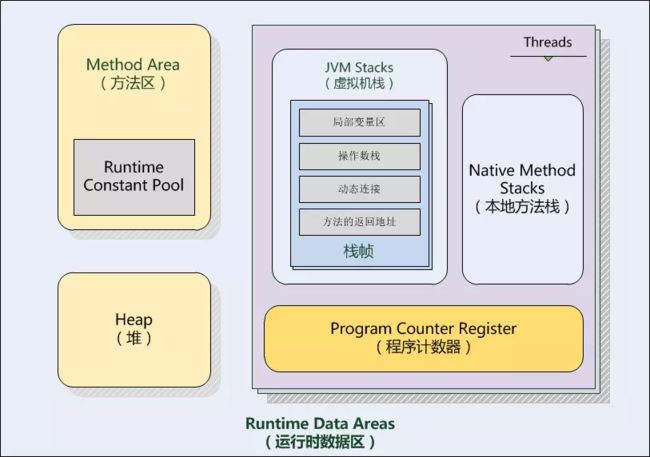
这张图是我们理解的jvm运行时数据区的结构,但是还有不完整的地方,
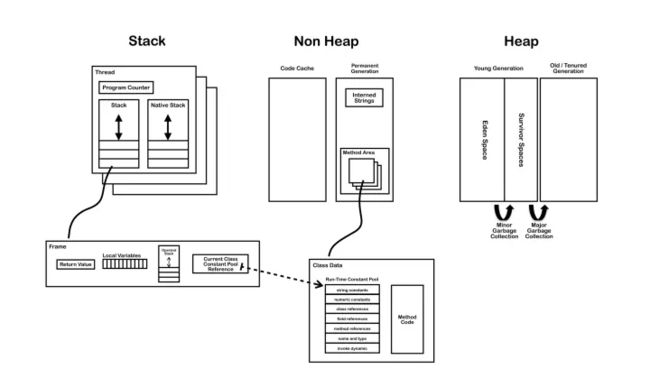
这张图中,可以看到,方法区实际上是在一块叫“非堆”的区域包含——可以简单粗略的理解为非堆中包含了永生代,而永生代中又包含了方法区和字符串常量池
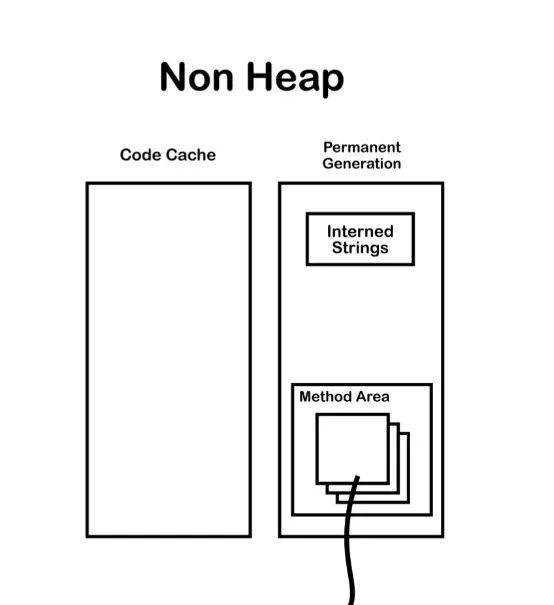
其中的Interned String就是全局共享的“字符串常量池(String Pool)”,和运行时常量池不是一个概念。但我们在代码中申明String s1 = "Hello";这句代码后,在类加载的过程中,类的class文件的信息会被解析到内存的方法区里。
class文件里常量池里大部分数据会被加载到“运行时常量池”,包括String的字面量;但同时“Hello”字符串的一个引用会被存到同样在“非堆”区域的“字符串常量池”中,而"Hello"本体还是和所有对象一样,创建在Java堆中。
当主线程开始创建s1时,虚拟机会先去字符串池中找是否有equals(“Hello”)的String,如果相等就把在字符串池中“Hello”的引用复制给s1;如果找不到相等的字符串,就会在堆中新建一个对象,同时把引用驻留在字符串池,再把引用赋给str。
当用字面量赋值的方法创建字符串时,无论创建多少次,只要字符串的值相同,它们所指向的都是堆中的同一个对象。
字符串常量池的本质
字符串常量池是JVM所维护的一个字符串实例的引用表,在HotSpot VM中,它是一个叫做StringTable的全局表。在字符串常量池中维护的是字符串实例的引用,底层C++实现就是一个Hashtable。这些被维护的引用所指的字符串实例,被称作”被驻留的字符串”或”interned string”或通常所说的”进入了字符串常量池的字符串”。
强调一下:运行时常量池在方法区(Non-heap),而JDK1.7后,字符串常量池被移到了heap区,因此两者根本就不是一个概念
String"字面量" 是何时进入字符串常量池的?
先说结论: 在执行ldc指令时,该指令表示int、float或String型常量从常量池推送至栈顶
JVM规范里Class文件的常量池项的类型,有两种东西:
- CONSTANT_Utf8_info
- CONSTANT_String_info
在HotSpot VM中,运行时常量池里,CONSTANT_Utf8_info可以表示Class文件的方法、字段等等,其结构如下:
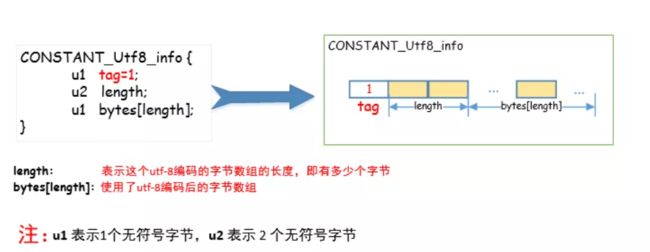
首先是1个字节的tag,表示这是一个CONSTANT_Utf8_info结构的常量,然后是两个字节的length,表示要储存字节的长度,之后是一个字节的byte数组,表示真正的储存的length个长度的字符串。这里需要注意的是,一个字节只是代表这里有一个byte类型的数组,而这个数组的长度当然可以远远大于一个字节。当然,由于CONSTANT_Utf8_info结构只能用u2即两个字节来表示长度,因此长度的最大值为2byte,也就是65535
CONSTANT_String_info是String常量的类型,但它并不直接持有String常量的内容,而是只持有一个index,这个index所指定的另一个常量池项必须是一个CONSTANT_Utf8类型的常量,这里才真正持有字符串的内容

CONSTANT_Utf8会在类加载的过程中就全部创建出来,而CONSTANT_String则是lazy resolve的,在第一次引用该项的ldc指令被第一次执行到的时候才会resolve。在尚未resolve的时候,HotSpot VM把它的类型叫做JVM_CONSTANT_UnresolvedString,内容跟Class文件里一样只是一个index;等到resolve过后这个项的常量类型就会变成最终的JVM_CONSTANT_String
也就是说,就HotSpot VM的实现来说,加载类的时候,那些字符串字面量会进入到当前类的运行时常量池,不会进入全局的字符串常量池(即在StringTable中并没有相应的引用,在堆中也没有对应的对象产生),在执行ldc指令时,触发lazy resolution这个动作:
ldc字节码在这里的执行语义是:到当前类的运行时常量池(runtime constant pool,HotSpot VM里是ConstantPool + ConstantPoolCache)去查找该index对应的项,如果该项尚未resolve则resolve之,并返回resolve后的内容。
在遇到String类型常量时,resolve的过程如果发现StringTable已经有了内容匹配的java.lang.String的引用,则直接返回这个引用,反之,如果StringTable里尚未有内容匹配的String实例的引用,则会在Java堆里创建一个对应内容的String对象,然后在StringTable记录下这个引用,并返回这个引用出去
可见,ldc指令是否需要创建新的String实例,全看在第一次执行这一条ldc指令时,StringTable是否已经记录了一个对应内容的String的引用。
String.intern()用法
String.intern()官方给的定义:
When the intern method is invoked, if the pool already contains a string equal to this String object as determined by the equals(Object) method, then the string from the pool is returned. Otherwise, this String object is added to the pool and a reference to this String object is returned.
实际上,就是去拿String的内容去Stringtable里查表,如果存在,则返回引用,不存在,就把该对象的"引用"存在Stringtable表里。
public class RuntimeConstantPoolOOM{
public static void main(String[] args) {
String str1 = new StringBuilder("计算机").append("软件").toString();
System.out.println(str1.intern() == str1);
String str2 = new StringBuilder("ja").append("va").toString();
System.out.println(str2.intern() == str2);
}
}
以上代码,在 JDK6 下执行结果为 false、false,在 JDK7 以上执行结果为 true、false。
首先我们调用StringBuilder创建了一个"计算机软件"String对象,因为调用了new关键字,因此是在运行时创建,之前JVM中是没有这个字符串的。
在 JDK6 下,intern()会把首次遇到的字符串实例复制到永久代中,返回的也是这个永久代中字符串实例的引用;而在JDK1.7开始,intern()方法不再复制字符串实例,String 的 intern 方法首先将尝试在常量池中查找该对象的引用,如果找到则直接返回该对象在常量池中的引用地址
因此在1.7中,“计算机软件”这个字符串实例只存在一份,存在于java堆中!通过3中的分析,我们知道当String str1 = new StringBuilder("计算机").append("软件").toString();这句代码执行完之后,已经在堆中创建了一个字符串对象,并且在全局字符串常量池中保留了这个字符串的引用,那么str1.intern()直接返回这个引用,这当然满足str1.intern() == str1——都是他自己嘛;对于引用str2,因为JVM中已经有“java”这个字符串了,因此new StringBuilder("ja").append("va").toString()会重新创建一个新的“java”字符串对象,而intern()会返回首次遇到的常量的实例引用,因此他返回的是系统中的那个"java"字符串对象引用(首次),因此会返回false
在 JDK6 下 str1、str2 指向的是新创建的对象,该对象将在 Java Heap 中创建,所以 str1、str2 指向的是 Java Heap 中的内存地址;调用 intern 方法后将尝试在常量池中查找该对象,没找到后将其放入常量池并返回,所以此时 str1/str2.intern() 指向的是常量池中的地址,JDK6常量池在永久代,与堆隔离,所以 s1.intern()和s1 的地址当然不同了。
public class Test2 {
public static void main(String[] args) {
/**
* 首先设置 持久代最大和最小内存占用(限定为10M)
* VM args: -XX:PermSize=10M -XX:MaxPremSize=10M
*/
List list = new ArrayList();
// 无限循环 使用 list 对其引用保证 不被GC intern 方法保证其加入到常量池中
int i = 0;
while (true) {
// 此处永久执行,最多就是将整个 int 范围转化成字符串并放入常量池
list.add(String.valueOf(i++).intern());
}
}
}
以上代码在 JDK6 下会出现 Perm 内存溢出,JDK7 or high 则没问题。
JDK6 常量池存在持久代,设置了持久代大小后,不断while循环必将撑满 Perm 导致内存溢出;JDK7 常量池被移动到 Native Heap(Java Heap,HotSpot VM中不区分native堆和Java堆),所以即使设置了持久代大小,也不会对常量池产生影响;不断while循环在当前的代码中,所有int的字符串相加还不至于撑满 Heap 区,所以不会出现异常。
JAVA 基本类型的封装类及对应常量池
java中基本类型的包装类的大部分都实现了常量池技术,这些类是Byte,Short,Integer,Long,Character,Boolean,另外两种浮点数类型的包装类则没有实现。另外上面这5种整型的包装类也只是在对应值小于等于127时才可使用对象池,也即对象不负责创建和管理大于127的这些类的对象。
public class StringConstantPool{
public static void main(String[] args){
//5种整形的包装类Byte,Short,Integer,Long,Character的对象,
//在值小于127时可以使用常量池
Integer i1=127;
Integer i2=127;
System.out.println(i1==i2);//输出true
//值大于127时,不会从常量池中取对象
Integer i3=128;
Integer i4=128;
System.out.println(i3==i4);//输出false
//Boolean类也实现了常量池技术
Boolean bool1=true;
Boolean bool2=true;
System.out.println(bool1==bool2);//输出true
//浮点类型的包装类没有实现常量池技术
Double d1=1.0;
Double d2=1.0;
System.out.println(d1==d2); //输出false
}
}
在JDK5.0之前是不允许直接将基本数据类型的数据直接赋值给其对应地包装类的,如:Integer i = 5; 但是在JDK5.0中支持这种写法,因为编译器会自动将上面的代码转换成如下代码:Integer i=Integer.valueOf(5);这就是Java的装箱.JDK5.0也提供了自动拆箱:Integer i =5; int j = i;