这次给大家介绍一下GAN的generalized framework。其实很多研究都是这样,先找到一个比较直观好理解方法,然后去研究他的框架,发现原来的就是一个特例。所以物理学家才想找什么归一化的方程。。
本文主要介绍了f-GAN、WGAN、improved WGAN、conditional GAN和cycle GAN资料来源于Hung-yi Lee
先介绍一些背景知识
- paper: Sebastian Nowozin, Botond Cseke, Ryota Tomioka, f-GAN: Training Generative Neural Samplers using Variational Divergence Minimization. NIPS, 2016
一句话总结:可以设计discriminator,和任何f-divergence有关(原来是和JS Divergence有关) - f-divergence
- Fenchel Conjugate
f-divergence
用来量两个分布的差异,假设P和Q是两个分布。p(x),q(x)分别是从两个分布sample出x的概率

f是一个函数喽,你带不同的函数就会得到不同的divergence,只要符合上述两个条件,比如KL Divergence (f(x)=xlog(x)),reverse KLD (f(x)=-log(x)),Chi Square (f(x)=(x-1)^2)等
Fenchel Conjugate
这个东西是凸优化中的,学过SVM的朋友应该知道哦!(主要就是把一般问题转化为简单,好解得问题)
这个东西就是可以把f-divergence写成GAN的样子,这里简单说一下定义吧,感兴趣的同学可以去看看凸优化

看到这个上确界是不是很快能想到不等式,最小最大对偶问题?那你功力不错!

上面的过程都颇直接的,这里给定一个D其实就是f-divergence的lower bound,我们max它,就可以近似f-divergence啦
从概率的角度讲呢,就可以改写成这样
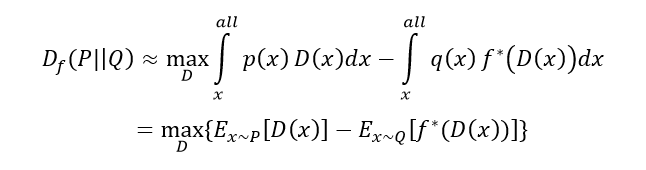
是不是很眼熟,这个式子一下就会求了吧, sample,对吧!找一个D能尽量最大化上式,那你就找到了衡量两个分布的f-divergence!(比如真实数据分布和伪造数据分布)

我们把中间过程写成V(G,D)是不是就和原来一样了么?!那个D就是Discriminator。
那也就是说,现在你想要算什么f-divergence,只要算出f的共轭来,带进去就可以啦!那你说带不同的f-divergence有差么?这就是上次提到的Mode Collapse,原始GAN不能产出多样性的data,就是因为原来是用JS Divergence,现在你就可以用KLD啦,也许可以解决Mode Collapse!(实际上是差不多....也就是说这个问题不是我们minimize哪个divergence产生的)。现在明白GAN就是f-divergence的一个特例了吧!
这篇paper还有说一点是Double-loop v.s. Single-step,也就是训练的时候本来是D训练多次,G训练一次,现在可以都只训练一次,可以证明是收敛的!大家可以看看paper,这里先不说了
接下来,我们回忆一下上次提到的,我们用JS Divergence来量两个分布的差异时,当两个分布没有交集的时候,它总是log2,这样会导致G的训练失效,它不明白到底怎么改变参数才能让divergence变小,其实这时候Discriminator失去了它作用
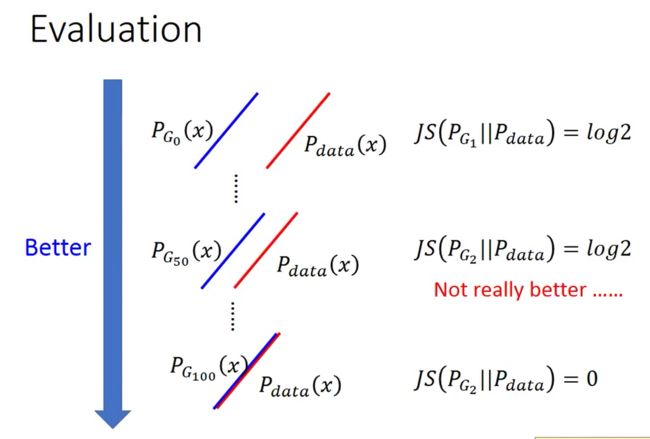
那其实很明显可以看到, 当两个分布逐渐接近的时候,其实我们的模型就在变好,那有没有办法来衡量这种趋势呢?(找到一种度量两个分布的距离不就好了么!就像perceptron一样,转化为度量误分类点到分类平面的距离!)

接下来,我们就介绍这种模型WGAN
下面我们来介绍一下WGAN
- paper: Martin Arjovsky, Soumith Chintala, Leon Bottou, Wasserstein GAN, arXiv prepring, 2017
Ishaan Gulrajani, Faruk Ahmed, Martin Arjovsky, Vincent Dumoulin, Aaron Courville, Improved Training of Wasserstein GANs, arXiv prepring, 2017
一句话总结:用Earth Mover's Distance来估计两个分布的差异 - Earth Mover's Distance
它类似于线性规划中运输问题的最优解(又挖坑了),你可以想象成搬运工把一堆土搬到指定的地方,那搬运所做平均最小功最小就是EMD,那我们可以用一个矩阵来表示

上图表示把P的土搬到Q的位置,B就是平均搬运的距离,那EMD是最小的搬运平均距离,那现在当两个分布不断接近时,它的EMD其实是不断的连续的在变小,模型就知道该往哪个方向走可以让两个分布差异变小!
我们来看看把EMD套用到GAN的框架里面!(文献直接给出)
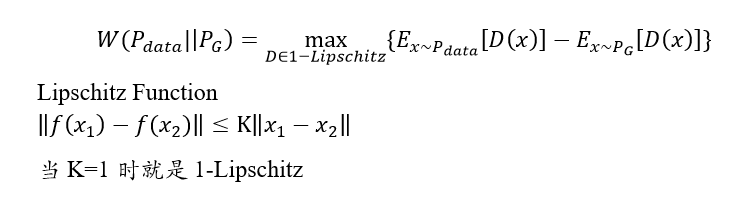
EMD可以表示成最大化这个式子,D属于1-Lipschitz function。从定义可以看出,D加了这个限制其实也就是说,D要是一个不会变化太猛烈的函数,如果没有这个约束会有什么问题呢?其实我们最大化这个式子只要让x从真实数据sample出来的值为正无穷,从假的数据集sample出来的值为负无穷就可以,这样能得到earth mover's distance吗?这里和原来是有区别的,最初的GAN我们假设D可以是任何输出的函数!(没忘吧)
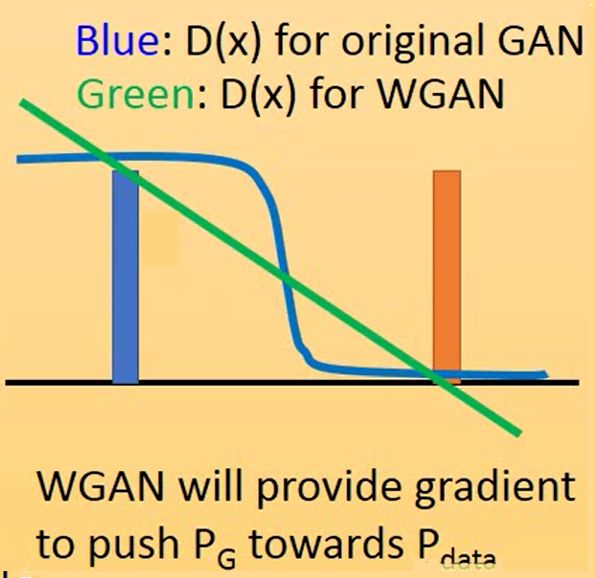
这个图可以帮助理解,用原始GAN的D,相当于一个sigmoid二分类器,它平滑了里分类面较远的点(导致梯度很小接近如零),使得比较难分类的点(正负边界上)有很好的学习,这是logistic回归中用sigmoid方程的好处之一(自己臆想的,它导致是sigmoid直接原因是属于指数族分布),但是我们现在任务不是为了分类,用WGAN的D的那条绿色的线更适合,至少他梯度不会变化太大,在哪里都有可学习性,不会出现gradient vanish问题
接下来我们看看怎么解这个问题,如果没有这个限制,直接gradient ascending就可以,但现在有这个限制怎么办呢?作者开始就用了weight clipping来限制D的变化范围(RNN有做的限制是gradient clipping),通过限制了weight,input的变化导致的output的变化肯定是在一个范围内的,但可能不是1-Lipschitz,但可以保证是K-Lipschitz。也很直观对吧,如果不加限制可能就会出现一根不断接近90度的分类线,你的training就无法停止!但是这是不一定可以找到W距离的
具体来说就是让weight在-c到c之间:
if w > c, then w = c;
if w < -c, then w = -c
算法其实只需要改一点就好,原来用的logD和log(1-D),现在只需要用D和-D就可以啦,然后学习D的过程中做一个weight clipping就好啦!第一篇paper中还有一个流言就是说不要用Adam来train,要用RSMprop,也有paper正好相反。。,大家可以试试
- 那我们这里小结一下
- 最初GAN的D是用来衡量JS Divergence的,假设每次我们把D train到底,那我们可能得到的结果都是定值log2,根本不知道我们generate的图片到底有多好;作者说它通常D不训练到底(D更新一次,G更新一次),那其实他衡量的根本不是JS Divergence,也不知道是啥,那他的discriminator的output也就失去了意义,你只能通过直觉来看G生成的好坏
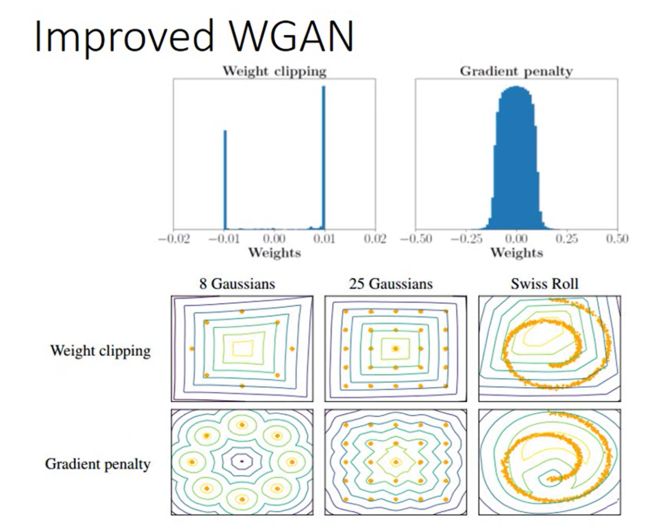
- 如果我们现在用的是WGAN的话,Discriminator衡量的是Wasserstein Distance,它是在衡量可以表示两个分布的距离,所以可以从loss里面看出来你的generator生成的图片到底好不好。比如下图二,G和D都用MLP则产生的图都是烂的,loss也都很大
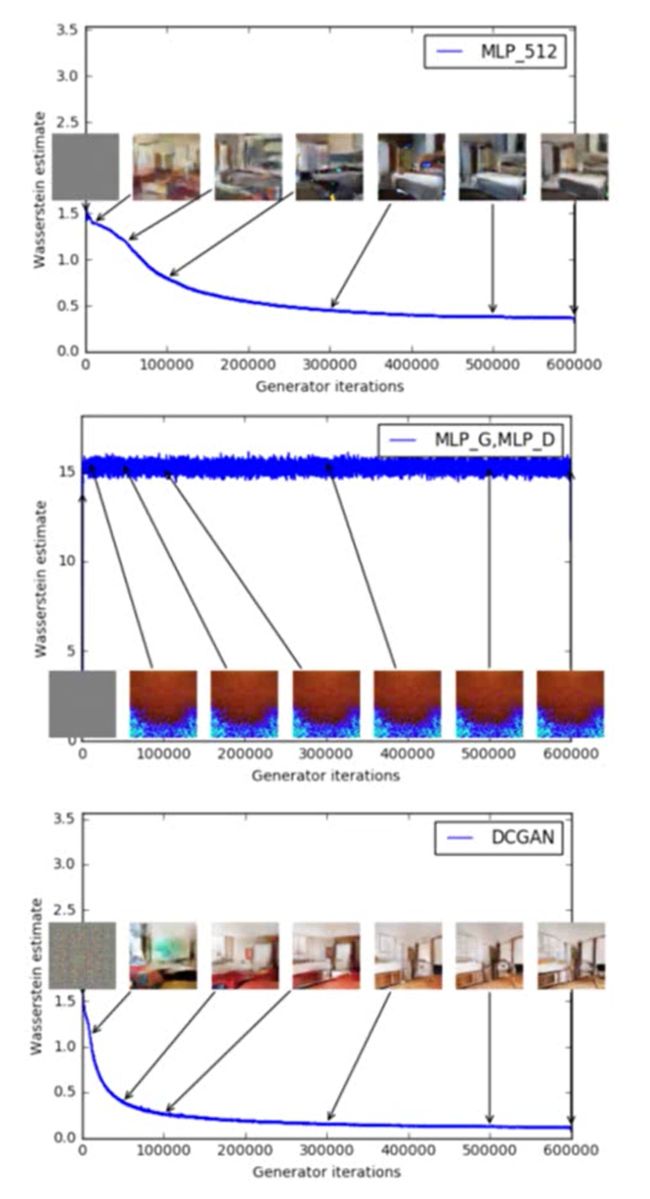
上面的解法我们只能说可以做到D是K-Lipschitz,但无法说是1-Lipschitz,那有什么方法可以让模型尽量去找1-Lipschitz呢?其实相当于你可以加更大的限制,大家可以想想,一般模型怎么加限制呢?下面简单聊聊
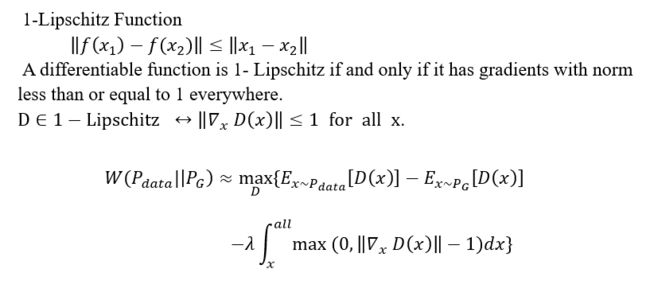
利用上面这个1-Lipschitz的性质,(注意一点是D对x的微分,不是对参数的!),给模型加正则。按照定义也颇直觉的对吧,我们从所有的D里面找到使 max最大的D,对那些gradient norm大于1的加penalty,这样只要lambda给足够大,就可以找到1-Lipschitz,这就是 Improved WGAN,因为不可能积分我们要做sample,所以
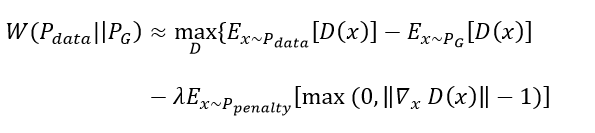
这个用来约束的penalty分布,直觉上这个应该是uniform分布对吧,但其实那样的话可能效率会很低,我们来介绍一下paper中是怎么选择的
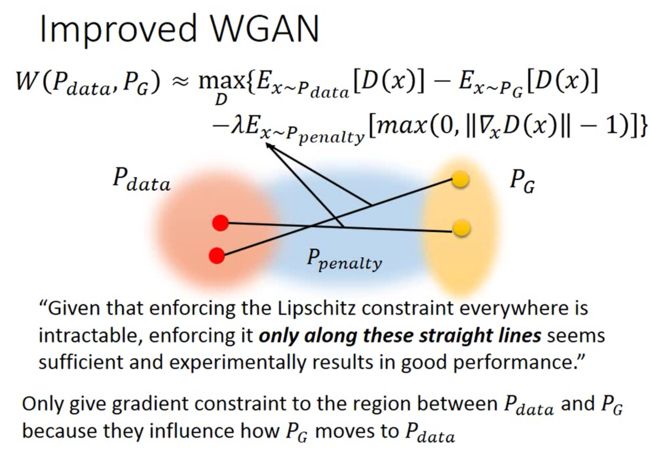
paper中说只用取真实分布和G中间的部分来作为penalty的分布,实验结果就很好了!其实也颇直接,因为他们之外的分布对G的更新也没意义对吧
那其实还有一点就是,paper中要norm越接近1约好,过大过小都有penalty,所以实际操作是用下面这个公式
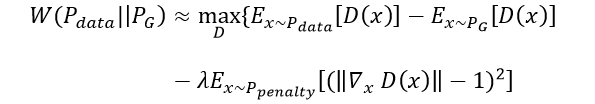
paper中是这么说的(同时Appendix有证明!)
"one may wonder why we penalize the norm of the gradient for differing from 1, instead of just penalizing large gradients. The reason is that the optimal critic ... actually has gradients with norm 1 almost everywhere under Pr and Pg"
"Simply penalizing overly large gradients also works in theory, but experimentally we found that this approach converged faster and to better optima."
他说假设你可以找到那个最好的Discriminator可以量出Wasserstein Distance的,那么它有个特性就是让真实data和G产生的data的连线上的Gradient都是1。那其实我们也是希望真实分布和G产生的分布差距大一点(也就是两个分布之间越陡约好),但是不能太大(最大为1),最后也说了,试验结果这样最好啦!
我们现在聊聊如何产生句子,为什么一般GAN不能做NLP呢?
那句子由词组成,一般用one-hot embedding来表示每个词,一个句子可用一个matrix表示,图片产生也就是产生一个矩阵而已,那直接产生句子好了呗。但是因为真实的句子是one-hot表示每个词也就是离散的,只有一个1其他都是0,而generator很难产生只有一个1和0的矩阵,那D是不是很容易发现什么假的?只要不是只有一个1的向量那肯定就是假的了。根本不需要学什么语义文法的事情,那其实不论G产生什么东西,D随便就可以判断真假,那学什么东西。(图的话因为每个像素值是连续的)。其实主要因为真实data和产生的data没有overlap的情况,那JS Divergence量出来永远是log2,train什么东西还?!是不是一下就知道该怎么办了?WGAN!
下面是一些WGAN产生的诗,有些还不错哦
其实主要产生这种离散数据的GAN主要是SeqGAN,但它不像传统的GAN,基于Reinforcement Learning来做,下次来聊这个,我们的图灵对话机!
前面讲的都是Generation的GAN,现在简单将一些GAN做transformation,比如text to image,你输入一句话,产生描述你说的话的图,image to image等等
比如inputs=一条狗,output应该输出一个狗的图片。那你问这不就是传统的supervise learning么?直接训练一个这样的模型不就好了么?那为什么用GAN呢?其实因为有许多狗的图片,它可以对于inputs=一条狗,那你传统方法会倾向于输出这个狗图片的均值,得到一个非常模糊的图,他不是sample的data
如果你用GAN的话可以approximate真实狗的分布,然后依照你的text得到高清图片(有见过文章用GAN去马赛克,脱衣服的哦),一般就是用Conditional GAN
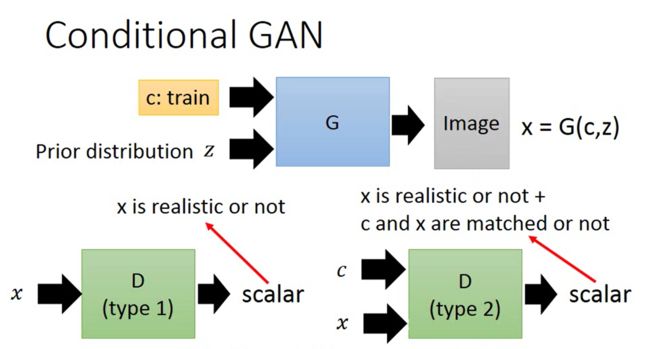
上图有两种方法可以训练Discriminator,那对应的正负样本应该是什么呢?大家想想吧。paper中效果比较好的是右图
再举一个image to image的例子,比如黑白图片到彩色图片,白天到黑夜等。
这里有一个trick是在G输出的结果中加入一个constrain,让output和target越接近约好,这样产生的图会更真实,不会产生一些怪怪的不存在的东西
上面都是有paired data来训练模型,假设没有paired data,如何做这种风格的转化呢?你不能让画家来对着你的照片画画
- Cycle GAN/Disco GAN
transform an object from one domain to another
比如把一张照片转化为梵高画风的图,冬天的景色转为夏天的景色等

Cycle GAN
这里怎么train呢?是不是可以容易想到你让D来辨别是否是梵高画的画,这样不断训练之后G产生的图就越来越像梵高的话了,但有一个问题是可能产生的画和输入的照片完全无关,inputs当做noise忽略掉就好了。。。作者为了避免这种结果,又加了一个generator,把产生梵高的画再合成输出原始图片,有点像AE,让input和output越接近越好。这样产生的图会保留原来的information。那个把梵高的画转为原始的generator就可以用来把真实梵高的画转为照片啦!
这个技术玩起来还是不错的,比如你可以把所有的照片都转为画家的画像,卡通人物等等
这次学了这些,有错误欢迎指出,下次学一下另一个重要技术Reinforcement Learning,走向终极目标(图灵问答)