动机:
从传统的检测算法而来,将检测问题中的特征提取用当时 轰动一时的CNN来代替,其他不变。那么检测和CNN识别之间需要一个候选框的过程,怎么办?结合另外一个人的工作叫做selective search来完成提出候选框。
为什么作者会想到呢?
首先他熟知了传统的检测过程的步骤,迅速灵敏的捕捉到特征提取可以用CNN来代替
这也警示我们:需要紧跟最新文献,熟知现阶段你所在领域的一般步骤,可从其他相似问题的解决模型中进行借鉴
整体算法模型过程:



大家可以将三者互相对比一下,R-CNN的主要思想还是比较简单的,但是文章的意义并不仅仅于此,他的实验的意义,训练技巧和实验结论个人觉得才是体现R-CNN文章的精髓。
实验设计
1. 数据集
正样本: IOU >0.5 为正样本
负样本: 经过作者的grid search{0,0.1..,0.5}发现负样本的标记为0.3时候最好,相比,如果选取0.5 则相差5个点,如果选取0则相差4个点。
为什么他会有这样的疑惑定义正负样本呢?
因为正负样本的定义有一个人为设定的阈值参数。只要是人为设置的参数阈值,都要反思其是否合理,无法得知就要做实验grid search!!!(下意识要有)
疑问:从检测的样本角度来看,是存在大量的标记噪声的。但是标记噪声和环境加入这两个是相对的概念,如何取舍?(还有一种是指感受野和图片标签的IOU,这个意思SSD用到的思想想到的点,也是tiny face里面用到的context主要意思)
2.模型设计
Ablation study,控制变量法,其实也有点调参的意思:
讨论行因素有:1.是否进行pre-trained+finetune 2.是否进行bbox regression 发现两者效果都有提升,其中pre-trained+finetune 效果提升巨大,后面bbox regression(虽然这里指DPM的bounding regression)也很大,这两个后续模型中都已经作为标配了。
2.1研究每个层pre-train的时候对检测结构的重要程度:(without finetune):
- 实验内容: CNN每一层都是特征,确认那到底用到哪一层,即重要程度
- 实验的原因: 即为什么作者会做这个实验?因为这里选择第几层其实是一个人为干预的值,所以有必要做实验
- 实验如何做:作者直接将不通层的特征输入给SVM训练并且分类,实验这里制作了pool5,fc6和fc7
- 是你会怎么做:当你思考这个问题的时候可能就会疑问:为什么只实验到pool5,不试试conv4,或者conv5呢?
 实验结果pascal 2007
实验结果pascal 2007 - 实验结果分析:fc7的效果不如fc6,而且pool5的效果已经足够好了,因为全连接占据了很多的权值。
- 这个实验对未来的帮助: 在没有fine-tune的情况下是否pre-trained只要加载到fc6就好了呢?
2.2 验证fine-tune效果的重要性:
- 实验内容: 判断不同层经过fine-tune之后再检测效果上面的影响
- 实验的原因: 验证fine-tune的有效性,另一方面,我们不知道不同层和fine-tune的的配合情况,有必要进行实验,为什么作者不直接拿实验2.1效果最好的来进行fine-tune进行对比呢?而是全部3组来进行对比?我觉得主要是因为fine-tune是一种有步骤的技巧,你必须先pre-train,然后在fine-tune,这样的话pre-train里面的人为因素,你在fine-tune有必要在进行一次实验进行对比
- 实验如何做: 将经过ImageNet预训练的CNN重新再最后检测的pascal VOC训练集上面训练,更详细的:是使用selective search 的 proposals 进行训练的,不是使用pascal voc的ground truth进行训练的。然后后续SVM使用的特征分别是pascal voc数据集上训练完后的pool5,fc6和fc7的特征。
1)那么你就有新的疑问,为什么不使用pascal VOC ground truth进行训练呢?
我现在的理解是:因为pascal voc比赛规定是使用IOU>0.5就为检测正确的依据,那么检测正确的情况肯定远比ground truth来得多。也就是正样本空间比ground truth来的多。所以为了提高效果就在IOU>0.5的采样空间来使用,其实如果采用ground truth 正样本会很少也是其中一个原因。
2)但是通过我的解释我自己又提出一个新的问题:为什么不在ground truth那边进行IOU>0.5的随机采样作为训练样本呢?
其实我感觉使用ground truth的随机采样貌似更合理,毕竟你用了proposal的方法有些目标本身已经被忽略了,这些domain的样本就无法在fine-tune的时候被训练到吧。这个是不是一条fine-tune改进的途径呢?但是针对例如faster RCNN 他的proposal是RPN提出来的,如果是使用ground truth随机采样进行训练,也就是最后classification和bbox regression的部分训练使用 proposal网络的feature map层的IOU>0.5的随机ROI pooling进行训练。那么proposal学习能力会不会被“减弱”?这个放在faster RCNN里面进行讨论! - 是你会怎么做: 你是否只会拿2.1实验中的最好结果来进行fine-tune看下效果呢?从中也回答了作者做实验的原因。
 实验结果
实验结果 - 实验结果分析: 这里可以看到fine-tune对pool5的特征影响比较小,对fc6,和fc7对结果的影响提升很大。这说名了pool5之前学到的是general的特征,fc6和fc7学到的是domain的特征。所以这也是为什么现在pre-train的时候大家加载的一般都是conv5之前的权值,而随机初始化fc6和fc7,来学习domain的特征。
- 你有可能会问:那我一定要初始化时候加上fc6和fc7不行吗?当然可以,比如你么domain很相近模型不想变的时候。如果domain不相近的话,1)这样可能收敛比较慢,可以从感性的理解一下,它已经是局部最优点了,不利于跳出去到你的domain里面的局部最优点。2)而且这样意义不是很大也不利于后期设计模型,毕竟全连接之后输入的大小规模被限定了,要求你的模型到fc6只能是4096,而卷积模型呢?他理论上是支持任意大小的图片。
2.3.模型采用的是CNN +SVM而不直接采用softmax输出,这个是什么原因呢?
这个问题在TPAMI版本的R-CNN上面有解释,这里我引自别人的博客的结论:文中7.2部分给出了作者的理由:采用softmax层分类相比SVM分类,mAP从54.2%降到了50.9%;这可能有两方面造成:第一,fine-tuning过程定义的正样本只要求IOU>=0.5,这不适合precision localization;第二,softmax是在随机采样的背景样本上进行训练,而SVM采用的则是hard-negative mining,这提高了分类准确度。
相比较现阶段,这个结论现在都没有被采用,他的不足在哪里呢?
虽然R-CNN中的补充实验已经说明 基于hard-negative mining的SVM得到的 mAP比softmax要高。但是将SVM和detection network的训练隔开,那么用于分类的SVM和提取特征的CNN model并不能完全对应。更好的方式当然是要考虑将提取特征和分类放在一起进行联合训练。其实这也是后面fast RCNN后提出来end2end训练的由来。
2.4 可视化:
实验提出了ZFnet之外的可视化技巧:
- 实验内容: 可视化网络模型学到什么东西
- 实验的原因: 更好的理解网络学到的什么,试图探究里面的奥秘,对后续分析研究有好处
- 实验如何做: 首先选取了识别主体占据region的大部分的那种图片大约10w规模,针对10w个图片都计算主pool5层feature map,拿其中一个pixel来说,针对这个pixel 10w张图片都分别对应有自己的激活值,然后让10w张图片按照这样的激活值进行排序。考前的图片如果有明显的模式特征,并且激活值都比较大,那么就可以确定这个pixel学到了相应的特征。然后将这个pixel对应的感受野画到原来的图片上面。其实相比于227227 这个receipt filed 的大小已经是196196。
- 实验这样做的原因,可视化的理由: 因为unit值越大相当于他越重要,然后将重要的进行计算其原图中感受野看哪个区域更重要。同时也从另一个角度说明了这个网络学到了什么特征。比如有些单元输出后对人比较感兴趣
- 实验结果分析: 可以看出有些神经元对人较敏感例如第一行,有些是对文本,点阵,说明学习到了有用的特征。
 image.png
image.png
也可以发现,有些同一个神经元学到了两种以上的特征(比如第二个的学到了狗脸和点阵的特征),那这个是否就可以说明这个分类效果不好呢,有进一步boosting的必要呢?进一步强化的必要呢?
这个可视化可以更加深入:其实这里还没有研究具体哪个神经元对那种特征敏感做相应的实验并探寻其中的原因(可能这个也启发了后续的attention机制)。
2.5误差分析:
如何做:excellent detection analysis tool from “D. Hoiem, Y. Chodpathumwan, and Q. Dai. Diagnosing error in object detectors. In ECCV. 2012.” 这一篇文章放到以后去补,学会这种检测误差分析工具。

检测分为4中错误类型,画一条竖线,相当于每个错误所占的比例,横坐标代表修改IOU的阈值
越往右IOU阈值设定越低,然后导致false positive越多。
Loc-poor:Loc—poor localization (a detection with an IoU overlap with the correct class between 0.1 and 0.5, or a duplicate)
Sim:confusion with a similar category;
Oth:confusion with a dissimilar object category;
BG:a FP that fired on background.
- 分析结果:可以看出这篇RCNN主要的误差来之poor localization,那么如何提高呢?可能从region proposal方面提高,因为定位来自selective search,有没有更好的算法呢,为后续研究提供了方向。
本文作者为了降低loc-poor也用了bbox regression(DPM中使用的) 也提高了3-4%的map。
那么具体的bbox regression是如何做的呢?
训练:
- 输入:
1)N个{(P,G)}其中P是指proposal的(x,y,w,h)其中x和y是中心点在图像空间的坐标。G是指与P对应的ground truth的(x,y,w,h)x,y 也是中心点
2)proposals 相对应的 pool5 feature maps ( proposals 只选取IOU>0.6的进行训练) - 模型:
- 1.整体模型目标:学习一个映射,将P 经过这个函数映射到 G(建模采用的是平移和放缩变换)
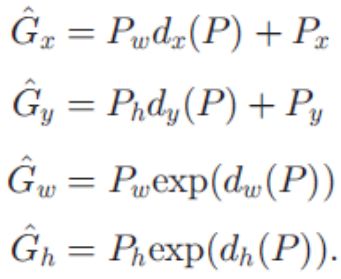
对于第一个公式和第二个公式来说来说P w d x(P)其实就是用proposal的宽乘上某个映射因子d x(P),乘积即为x的平移量,所以这两个公式相当于是平移变换。对于第三个公式和第四个公式来说p wexp(d w(P))其中exp(dw(P)) 其实就是scale的缩放因子所以这4个映射函数d*(P)实际上就是 建模平移和尺度变换。
- 2.对d*(P)的建模(*代表x,y,w,h)
这里作者简单的采用线性建模(可以思考是否有更好的建模方式),d*(P)其实就可以写成 w*φ(P) 其中w是线性参数.φ(p) 是相应的proposals的pool5的feature值,即输入ROI的(x,y,w,h)坐标,然后得到其pool5层的ROI对应的feature maps。
所以目标函数是:

其中t i 可以使用上面 1的整体模型目标推导而来,得到如下t的公式:

这个是一个线性模型,分别学习w h,w w,w x,w y参数,然后使用梯度下降等算法进行更新。
为什么这么设计?
1.可能你会感到疑惑的是为什么设计尺度变化的时候是exp(d(p))而不是直接乘上d(p),这里面博客中给出的一个解释是因为这样可以确保乘出来的数值>0.
2.另外你可能也会疑惑,为什么输入要设计成feature map的特征即d(p)=wφ(pool5),而不直接输入P的坐标,我个人觉得这样输入特征才是有效的因素,不同的部分有不同的回归的参数。而只是输入P的坐标,那么很可能无法收敛。太多的P对应太多的G了。我们设计的时候,尽量让P和G是一一对应的关系,尽量让相近的P对应的G也尽量相同。这样的话会比较好收敛。显然,如果这个P在这个样本下是对应G1,在另一个样本得到相同P则对应另一个G2,那么显然训练的时候就不好收敛。为什么作者会想到这么设计?
其实想到这种思路也是比较简单的,就是建模平移和尺度变化的过程。那么这时候你可以问下自己,如果你建模旋转,你该如何设计呢?这里还有个问题,就是作者说当proposals和ground truth相差很远的时候这种回归就没有作用了,所以这里相差很远具体的定义是什么,为什么相差很远就不起作用呢?
文中是用IOU>0.6 来界定相差不远。因为相差很远了就不是线性变换了。用线性模型建模就不合理。但其实这里应该还能做一些更深入的研究。
2.6 其他:
对模型时间和训练内存的讨论
如何讨论:模型会耗费这些时间的原因,比其他模型慢或者快的原因即对比分析
结论:13s/image on a GPU or 53s/image on a CPU(还是很慢的)相同模型应用于新的任务(分割)
将这个模型应用于分割任务,会后续分割任务提供了方向。再次就不谈了。
参考文献:
- Girshick R, Donahue J, Darrell T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2014: 580-587.
- 参考博客:作者:研究路上 链接:https://www.jianshu.com/p/52e6e184b786 來源: