序
本文主要研究一下storm trident的coordinator
实例
代码示例
@Test
public void testDebugTopologyBuild(){
FixedBatchSpout spout = new FixedBatchSpout(new Fields("user", "score"), 3,
new Values("nickt1", 4),
new Values("nickt2", 7),
new Values("nickt3", 8),
new Values("nickt4", 9),
new Values("nickt5", 7),
new Values("nickt6", 11),
new Values("nickt7", 5)
);
spout.setCycle(false);
TridentTopology topology = new TridentTopology();
Stream stream1 = topology.newStream("spout1",spout)
.each(new Fields("user", "score"), new BaseFunction() {
@Override
public void execute(TridentTuple tuple, TridentCollector collector) {
System.out.println("tuple:"+tuple);
}
},new Fields());
topology.build();
}
- 这里使用的spout为FixedBatchSpout,它是IBatchSpout类型
拓扑图
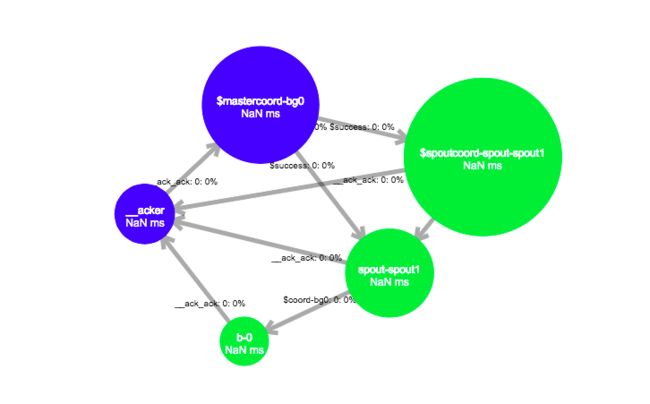
MasterBatchCoordinator
storm-1.2.2/storm-core/src/jvm/org/apache/storm/trident/topology/MasterBatchCoordinator.java
public class MasterBatchCoordinator extends BaseRichSpout {
public static final Logger LOG = LoggerFactory.getLogger(MasterBatchCoordinator.class);
public static final long INIT_TXID = 1L;
public static final String BATCH_STREAM_ID = "$batch";
public static final String COMMIT_STREAM_ID = "$commit";
public static final String SUCCESS_STREAM_ID = "$success";
private static final String CURRENT_TX = "currtx";
private static final String CURRENT_ATTEMPTS = "currattempts";
private List _states = new ArrayList();
TreeMap _activeTx = new TreeMap();
TreeMap _attemptIds;
private SpoutOutputCollector _collector;
Long _currTransaction;
int _maxTransactionActive;
List _coordinators = new ArrayList();
List _managedSpoutIds;
List _spouts;
WindowedTimeThrottler _throttler;
boolean _active = true;
public MasterBatchCoordinator(List spoutIds, List spouts) {
if(spoutIds.isEmpty()) {
throw new IllegalArgumentException("Must manage at least one spout");
}
_managedSpoutIds = spoutIds;
_spouts = spouts;
LOG.debug("Created {}", this);
}
public List getManagedSpoutIds(){
return _managedSpoutIds;
}
@Override
public void activate() {
_active = true;
}
@Override
public void deactivate() {
_active = false;
}
@Override
public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) {
_throttler = new WindowedTimeThrottler((Number)conf.get(Config.TOPOLOGY_TRIDENT_BATCH_EMIT_INTERVAL_MILLIS), 1);
for(String spoutId: _managedSpoutIds) {
_states.add(TransactionalState.newCoordinatorState(conf, spoutId));
}
_currTransaction = getStoredCurrTransaction();
_collector = collector;
Number active = (Number) conf.get(Config.TOPOLOGY_MAX_SPOUT_PENDING);
if(active==null) {
_maxTransactionActive = 1;
} else {
_maxTransactionActive = active.intValue();
}
_attemptIds = getStoredCurrAttempts(_currTransaction, _maxTransactionActive);
for(int i=0; i<_spouts.size(); i++) {
String txId = _managedSpoutIds.get(i);
_coordinators.add(_spouts.get(i).getCoordinator(txId, conf, context));
}
LOG.debug("Opened {}", this);
}
@Override
public void close() {
for(TransactionalState state: _states) {
state.close();
}
LOG.debug("Closed {}", this);
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
// in partitioned example, in case an emitter task receives a later transaction than it's emitted so far,
// when it sees the earlier txid it should know to emit nothing
declarer.declareStream(BATCH_STREAM_ID, new Fields("tx"));
declarer.declareStream(COMMIT_STREAM_ID, new Fields("tx"));
declarer.declareStream(SUCCESS_STREAM_ID, new Fields("tx"));
}
@Override
public Map getComponentConfiguration() {
Config ret = new Config();
ret.setMaxTaskParallelism(1);
ret.registerSerialization(TransactionAttempt.class);
return ret;
}
//......
}
- prepare方法首先从Config.TOPOLOGY_TRIDENT_BATCH_EMIT_INTERVAL_MILLIS(
topology.trident.batch.emit.interval.millis,在defaults.yaml默认为500)读取触发batch的频率配置,然后创建WindowedTimeThrottler,其maxAmt值为1 - 这里使用TransactionalState在zookeeper上维护transactional状态
- 之后读取Config.TOPOLOGY_MAX_SPOUT_PENDING(
topology.max.spout.pending,在defaults.yaml中默认为null)设置_maxTransactionActive,如果为null,则设置为1
MasterBatchCoordinator.nextTuple
storm-1.2.2/storm-core/src/jvm/org/apache/storm/trident/topology/MasterBatchCoordinator.java
@Override
public void nextTuple() {
sync();
}
private void sync() {
// note that sometimes the tuples active may be less than max_spout_pending, e.g.
// max_spout_pending = 3
// tx 1, 2, 3 active, tx 2 is acked. there won't be a commit for tx 2 (because tx 1 isn't committed yet),
// and there won't be a batch for tx 4 because there's max_spout_pending tx active
TransactionStatus maybeCommit = _activeTx.get(_currTransaction);
if(maybeCommit!=null && maybeCommit.status == AttemptStatus.PROCESSED) {
maybeCommit.status = AttemptStatus.COMMITTING;
_collector.emit(COMMIT_STREAM_ID, new Values(maybeCommit.attempt), maybeCommit.attempt);
LOG.debug("Emitted on [stream = {}], [tx_status = {}], [{}]", COMMIT_STREAM_ID, maybeCommit, this);
}
if(_active) {
if(_activeTx.size() < _maxTransactionActive) {
Long curr = _currTransaction;
for(int i=0; i<_maxTransactionActive; i++) {
if(!_activeTx.containsKey(curr) && isReady(curr)) {
// by using a monotonically increasing attempt id, downstream tasks
// can be memory efficient by clearing out state for old attempts
// as soon as they see a higher attempt id for a transaction
Integer attemptId = _attemptIds.get(curr);
if(attemptId==null) {
attemptId = 0;
} else {
attemptId++;
}
_attemptIds.put(curr, attemptId);
for(TransactionalState state: _states) {
state.setData(CURRENT_ATTEMPTS, _attemptIds);
}
TransactionAttempt attempt = new TransactionAttempt(curr, attemptId);
final TransactionStatus newTransactionStatus = new TransactionStatus(attempt);
_activeTx.put(curr, newTransactionStatus);
_collector.emit(BATCH_STREAM_ID, new Values(attempt), attempt);
LOG.debug("Emitted on [stream = {}], [tx_attempt = {}], [tx_status = {}], [{}]", BATCH_STREAM_ID, attempt, newTransactionStatus, this);
_throttler.markEvent();
}
curr = nextTransactionId(curr);
}
}
}
}
- nextTuple就是调用sync方法,该方法在ack及fail中均有调用;sync方法首先根据事务状态,如果需要提交,则会往MasterBatchCoordinator.COMMIT_STREAM_ID(
$commit)发送tuple;之后根据_maxTransactionActive以及WindowedTimeThrottler限制,符合要求才启动新的TransactionAttempt,往MasterBatchCoordinator.BATCH_STREAM_ID($batch)发送tuple,同时对WindowedTimeThrottler标记下windowEvent数量
MasterBatchCoordinator.ack
storm-1.2.2/storm-core/src/jvm/org/apache/storm/trident/topology/MasterBatchCoordinator.java
@Override
public void ack(Object msgId) {
TransactionAttempt tx = (TransactionAttempt) msgId;
TransactionStatus status = _activeTx.get(tx.getTransactionId());
LOG.debug("Ack. [tx_attempt = {}], [tx_status = {}], [{}]", tx, status, this);
if(status!=null && tx.equals(status.attempt)) {
if(status.status==AttemptStatus.PROCESSING) {
status.status = AttemptStatus.PROCESSED;
LOG.debug("Changed status. [tx_attempt = {}] [tx_status = {}]", tx, status);
} else if(status.status==AttemptStatus.COMMITTING) {
_activeTx.remove(tx.getTransactionId());
_attemptIds.remove(tx.getTransactionId());
_collector.emit(SUCCESS_STREAM_ID, new Values(tx));
_currTransaction = nextTransactionId(tx.getTransactionId());
for(TransactionalState state: _states) {
state.setData(CURRENT_TX, _currTransaction);
}
LOG.debug("Emitted on [stream = {}], [tx_attempt = {}], [tx_status = {}], [{}]", SUCCESS_STREAM_ID, tx, status, this);
}
sync();
}
}
- ack主要是根据当前事务状态进行不同操作,如果之前是AttemptStatus.PROCESSING状态,则更新为AttemptStatus.PROCESSED;如果之前是AttemptStatus.COMMITTING,则移除当前事务,然后往MasterBatchCoordinator.SUCCESS_STREAM_ID(
$success)发送tuple,更新_currTransaction为nextTransactionId;最后再调用sync触发新的TransactionAttempt
MasterBatchCoordinator.fail
storm-1.2.2/storm-core/src/jvm/org/apache/storm/trident/topology/MasterBatchCoordinator.java
@Override
public void fail(Object msgId) {
TransactionAttempt tx = (TransactionAttempt) msgId;
TransactionStatus stored = _activeTx.remove(tx.getTransactionId());
LOG.debug("Fail. [tx_attempt = {}], [tx_status = {}], [{}]", tx, stored, this);
if(stored!=null && tx.equals(stored.attempt)) {
_activeTx.tailMap(tx.getTransactionId()).clear();
sync();
}
}
- fail方法将当前事务从_activeTx中移除,然后清空_activeTx中txId大于这个失败txId的数据,最后再调用sync判断是否该触发新的TransactionAttempt(
注意这里没有变更_currTransaction,因而sync方法触发新的TransactionAttempt的_txid还是当前这个失败的_currTransaction)
TridentSpoutCoordinator
storm-1.2.2/storm-core/src/jvm/org/apache/storm/trident/spout/TridentSpoutCoordinator.java
public class TridentSpoutCoordinator implements IBasicBolt {
public static final Logger LOG = LoggerFactory.getLogger(TridentSpoutCoordinator.class);
private static final String META_DIR = "meta";
ITridentSpout- TridentSpoutCoordinator的nextTuple根据streamId分别做不同的处理
- 如果是MasterBatchCoordinator.SUCCESS_STREAM_ID(
$success)则表示master那边接收到了ack已经成功了,然后coordinator就清除该txId之前的数据,然后回调ITridentSpout.BatchCoordinator的success方法 - 如果是MasterBatchCoordinator.BATCH_STREAM_ID(
$batch)则要启动新的TransactionAttempt,则往MasterBatchCoordinator.BATCH_STREAM_ID($batch)发送tuple,该tuple会被下游的bolt接收(在本实例就是使用TridentSpoutExecutor包装了用户spout的TridentBoltExecutor)
TridentBoltExecutor
storm-1.2.2/storm-core/src/jvm/org/apache/storm/trident/topology/TridentBoltExecutor.java
public class TridentBoltExecutor implements IRichBolt {
public static final String COORD_STREAM_PREFIX = "$coord-";
public static String COORD_STREAM(String batch) {
return COORD_STREAM_PREFIX + batch;
}
RotatingMap _batches;
@Override
public void prepare(Map conf, TopologyContext context, OutputCollector collector) {
_messageTimeoutMs = context.maxTopologyMessageTimeout() * 1000L;
_lastRotate = System.currentTimeMillis();
_batches = new RotatingMap<>(2);
_context = context;
_collector = collector;
_coordCollector = new CoordinatedOutputCollector(collector);
_coordOutputCollector = new BatchOutputCollectorImpl(new OutputCollector(_coordCollector));
_coordConditions = (Map) context.getExecutorData("__coordConditions");
if(_coordConditions==null) {
_coordConditions = new HashMap<>();
for(String batchGroup: _coordSpecs.keySet()) {
CoordSpec spec = _coordSpecs.get(batchGroup);
CoordCondition cond = new CoordCondition();
cond.commitStream = spec.commitStream;
cond.expectedTaskReports = 0;
for(String comp: spec.coords.keySet()) {
CoordType ct = spec.coords.get(comp);
if(ct.equals(CoordType.single())) {
cond.expectedTaskReports+=1;
} else {
cond.expectedTaskReports+=context.getComponentTasks(comp).size();
}
}
cond.targetTasks = new HashSet<>();
for(String component: Utils.get(context.getThisTargets(),
COORD_STREAM(batchGroup),
new HashMap()).keySet()) {
cond.targetTasks.addAll(context.getComponentTasks(component));
}
_coordConditions.put(batchGroup, cond);
}
context.setExecutorData("_coordConditions", _coordConditions);
}
_bolt.prepare(conf, context, _coordOutputCollector);
}
//......
@Override
public void cleanup() {
_bolt.cleanup();
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
_bolt.declareOutputFields(declarer);
for(String batchGroup: _coordSpecs.keySet()) {
declarer.declareStream(COORD_STREAM(batchGroup), true, new Fields("id", "count"));
}
}
@Override
public Map getComponentConfiguration() {
Map ret = _bolt.getComponentConfiguration();
if(ret==null) ret = new HashMap<>();
ret.put(Config.TOPOLOGY_TICK_TUPLE_FREQ_SECS, 5);
// TODO: Need to be able to set the tick tuple time to the message timeout, ideally without parameterization
return ret;
}
}
- prepare的时候,先创建了CoordinatedOutputCollector,之后用OutputCollector包装,再最后包装为BatchOutputCollectorImpl,调用ITridentBatchBolt.prepare方法,ITridentBatchBolt这里头使用的实现类为TridentSpoutExecutor
- prepare初始化了RotatingMap
- prepare主要做的是构建CoordCondition,这里主要是计算expectedTaskReports以及targetTasks
TridentBoltExecutor.execute
storm-1.2.2/storm-core/src/jvm/org/apache/storm/trident/topology/TridentBoltExecutor.java
@Override
public void execute(Tuple tuple) {
if(TupleUtils.isTick(tuple)) {
long now = System.currentTimeMillis();
if(now - _lastRotate > _messageTimeoutMs) {
_batches.rotate();
_lastRotate = now;
}
return;
}
String batchGroup = _batchGroupIds.get(tuple.getSourceGlobalStreamId());
if(batchGroup==null) {
// this is so we can do things like have simple DRPC that doesn't need to use batch processing
_coordCollector.setCurrBatch(null);
_bolt.execute(null, tuple);
_collector.ack(tuple);
return;
}
IBatchID id = (IBatchID) tuple.getValue(0);
//get transaction id
//if it already exists and attempt id is greater than the attempt there
TrackedBatch tracked = (TrackedBatch) _batches.get(id.getId());
// if(_batches.size() > 10 && _context.getThisTaskIndex() == 0) {
// System.out.println("Received in " + _context.getThisComponentId() + " " + _context.getThisTaskIndex()
// + " (" + _batches.size() + ")" +
// "\ntuple: " + tuple +
// "\nwith tracked " + tracked +
// "\nwith id " + id +
// "\nwith group " + batchGroup
// + "\n");
//
// }
//System.out.println("Num tracked: " + _batches.size() + " " + _context.getThisComponentId() + " " + _context.getThisTaskIndex());
// this code here ensures that only one attempt is ever tracked for a batch, so when
// failures happen you don't get an explosion in memory usage in the tasks
if(tracked!=null) {
if(id.getAttemptId() > tracked.attemptId) {
_batches.remove(id.getId());
tracked = null;
} else if(id.getAttemptId() < tracked.attemptId) {
// no reason to try to execute a previous attempt than we've already seen
return;
}
}
if(tracked==null) {
tracked = new TrackedBatch(new BatchInfo(batchGroup, id, _bolt.initBatchState(batchGroup, id)), _coordConditions.get(batchGroup), id.getAttemptId());
_batches.put(id.getId(), tracked);
}
_coordCollector.setCurrBatch(tracked);
//System.out.println("TRACKED: " + tracked + " " + tuple);
TupleType t = getTupleType(tuple, tracked);
if(t==TupleType.COMMIT) {
tracked.receivedCommit = true;
checkFinish(tracked, tuple, t);
} else if(t==TupleType.COORD) {
int count = tuple.getInteger(1);
tracked.reportedTasks++;
tracked.expectedTupleCount+=count;
checkFinish(tracked, tuple, t);
} else {
tracked.receivedTuples++;
boolean success = true;
try {
_bolt.execute(tracked.info, tuple);
if(tracked.condition.expectedTaskReports==0) {
success = finishBatch(tracked, tuple);
}
} catch(FailedException e) {
failBatch(tracked, e);
}
if(success) {
_collector.ack(tuple);
} else {
_collector.fail(tuple);
}
}
_coordCollector.setCurrBatch(null);
}
private TupleType getTupleType(Tuple tuple, TrackedBatch batch) {
CoordCondition cond = batch.condition;
if(cond.commitStream!=null
&& tuple.getSourceGlobalStreamId().equals(cond.commitStream)) {
return TupleType.COMMIT;
} else if(cond.expectedTaskReports > 0
&& tuple.getSourceStreamId().startsWith(COORD_STREAM_PREFIX)) {
return TupleType.COORD;
} else {
return TupleType.REGULAR;
}
}
private void failBatch(TrackedBatch tracked, FailedException e) {
if(e!=null && e instanceof ReportedFailedException) {
_collector.reportError(e);
}
tracked.failed = true;
if(tracked.delayedAck!=null) {
_collector.fail(tracked.delayedAck);
tracked.delayedAck = null;
}
}
- TridentBoltExecutor的execute方法首先判断是否是tickTuple,如果是判断距离_lastRotate的时间(
prepare的时候初始化为当时的时间)是否超过_messageTimeoutMs,如果是则进行_batches.rotate()操作;tickTuple的发射频率为Config.TOPOLOGY_TICK_TUPLE_FREQ_SECS(topology.tick.tuple.freq.secs),在TridentBoltExecutor中它被设置为5秒;_messageTimeoutMs为context.maxTopologyMessageTimeout() * 1000L,它从整个topology的component的Config.TOPOLOGY_MESSAGE_TIMEOUT_SECS(topology.message.timeout.secs,defaults.yaml中默认为30)最大值*1000 - _batches按TransactionAttempt的txId来存储TrackedBatch信息,如果没有则创建一个新的TrackedBatch;创建TrackedBatch时,会回调_bolt的initBatchState方法
- 之后判断tuple的类型,这里分为TupleType.COMMIT、TupleType.COORD、TupleType.REGULAR;如果是TupleType.COMMIT类型,则设置tracked.receivedCommit为true,然后调用checkFinish方法;如果是TupleType.COORD类型,则更新reportedTasks及expectedTupleCount计数,再调用checkFinish方法;如果是TupleType.REGULAR类型(
coordinator发送过来的batch信息),则更新receivedTuples计数,然后调用_bolt.execute方法(这里的_bolt为TridentSpoutExecutor),对于tracked.condition.expectedTaskReports==0的则立马调用finishBatch,将该batch从_batches中移除;如果有FailedException则直接failBatch上报error信息,之后对tuple进行ack或者fail;如果下游是each操作,一个batch中如果是部分抛出FailedException异常,则需要等到所有batch中的tuple执行完,等到TupleType.COORD触发检测checkFinish,这个时候才能fail通知到master,也就是有一些滞后性,比如这个batch中有3个tuple,第二个tuple抛出FailedException,还会继续执行第三个tuple,最后该batch的tuple都处理完了,才收到TupleType.COORD触发检测checkFinish。
TridentBoltExecutor.checkFinish
storm-1.2.2/storm-core/src/jvm/org/apache/storm/trident/topology/TridentBoltExecutor.java
private void checkFinish(TrackedBatch tracked, Tuple tuple, TupleType type) {
if(tracked.failed) {
failBatch(tracked);
_collector.fail(tuple);
return;
}
CoordCondition cond = tracked.condition;
boolean delayed = tracked.delayedAck==null &&
(cond.commitStream!=null && type==TupleType.COMMIT
|| cond.commitStream==null);
if(delayed) {
tracked.delayedAck = tuple;
}
boolean failed = false;
if(tracked.receivedCommit && tracked.reportedTasks == cond.expectedTaskReports) {
if(tracked.receivedTuples == tracked.expectedTupleCount) {
finishBatch(tracked, tuple);
} else {
//TODO: add logging that not all tuples were received
failBatch(tracked);
_collector.fail(tuple);
failed = true;
}
}
if(!delayed && !failed) {
_collector.ack(tuple);
}
}
private void failBatch(TrackedBatch tracked) {
failBatch(tracked, null);
}
private void failBatch(TrackedBatch tracked, FailedException e) {
if(e!=null && e instanceof ReportedFailedException) {
_collector.reportError(e);
}
tracked.failed = true;
if(tracked.delayedAck!=null) {
_collector.fail(tracked.delayedAck);
tracked.delayedAck = null;
}
}
- TridentBoltExecutor在execute的时候,在tuple是TupleType.COMMIT以及TupleType.COORD的时候都会调用checkFinish
- 一旦_bolt.execute(tracked.info, tuple)方法抛出FailedException,则会调用failBatch,它会标记tracked.failed为true
- checkFinish在发现tracked.failed为true的时候,会调用_collector.fail(tuple),然后回调MasterBatchCoordinator的fail方法
TridentSpoutExecutor
storm-1.2.2/storm-core/src/jvm/org/apache/storm/trident/spout/TridentSpoutExecutor.java
public class TridentSpoutExecutor implements ITridentBatchBolt {
public static final String ID_FIELD = "$tx";
public static final Logger LOG = LoggerFactory.getLogger(TridentSpoutExecutor.class);
AddIdCollector _collector;
ITridentSpout- TridentSpoutExecutor使用的BatchOutputCollector为TridentBoltExecutor在prepare方法构造的,经过几层包装,先是CoordinatedOutputCollector,然后是OutputCollector,最后是BatchOutputCollectorImpl;这里最主要的是CoordinatedOutputCollector包装,它维护每个taskId发出的tuple的数量;而在这个executor的prepare方法里头,该collector又被包装为AddIdCollector,主要是添加了batchId信息(
即TransactionAttempt信息) - TridentSpoutExecutor的ITridentSpout就是包装了用户设置的原始spout(
IBatchSpout类型)的BatchSpoutExecutor(假设原始spout是IBatchSpout类型的,因而会通过BatchSpoutExecutor包装为ITridentSpout类型),其execute方法根据不同stream类型进行不同处理,如果是master发过来的MasterBatchCoordinator.COMMIT_STREAM_ID($commit)则调用emitter的commit方法提交当前TransactionAttempt(本文的实例没有commit信息),然后将该tx从_activeBatches中移除;如果是master发过来的MasterBatchCoordinator.SUCCESS_STREAM_ID($success)则先把_activeBatches中txId小于该txId的TransactionAttempt移除,然后调用emitter的success方法,标记TransactionAttempt成功,该方法回调原始spout(IBatchSpout类型)的ack方法 - 非MasterBatchCoordinator.COMMIT_STREAM_ID(
$commit)及MasterBatchCoordinator.SUCCESS_STREAM_ID($success)类型的tuple,则是启动batch的消息,这里设置batchId,然后调用emitter的emitBatch进行数据发送(这里传递的batchId就是TransactionAttempt的txId),同时将该TransactionAttempt放入_activeBatches中(这里的batch相当于TransactionAttempt)
FixedBatchSpout
storm-1.2.2/storm-core/src/jvm/org/apache/storm/trident/testing/FixedBatchSpout.java
public class FixedBatchSpout implements IBatchSpout {
Fields fields;
List- 用户使用的spout是IBatchSpout类型,这里缓存了每个batchId对应的tuple数据,实现的是transactional spout的语义
TridentTopology.newStream
storm-1.2.2/storm-core/src/jvm/org/apache/storm/trident/TridentTopology.java
public Stream newStream(String txId, IRichSpout spout) {
return newStream(txId, new RichSpoutBatchExecutor(spout));
}
public Stream newStream(String txId, IBatchSpout spout) {
Node n = new SpoutNode(getUniqueStreamId(), spout.getOutputFields(), txId, spout, SpoutNode.SpoutType.BATCH);
return addNode(n);
}
public Stream newStream(String txId, ITridentSpout spout) {
Node n = new SpoutNode(getUniqueStreamId(), spout.getOutputFields(), txId, spout, SpoutNode.SpoutType.BATCH);
return addNode(n);
}
public Stream newStream(String txId, IPartitionedTridentSpout spout) {
return newStream(txId, new PartitionedTridentSpoutExecutor(spout));
}
public Stream newStream(String txId, IOpaquePartitionedTridentSpout spout) {
return newStream(txId, new OpaquePartitionedTridentSpoutExecutor(spout));
}
public Stream newStream(String txId, ITridentDataSource dataSource) {
if (dataSource instanceof IBatchSpout) {
return newStream(txId, (IBatchSpout) dataSource);
} else if (dataSource instanceof ITridentSpout) {
return newStream(txId, (ITridentSpout) dataSource);
} else if (dataSource instanceof IPartitionedTridentSpout) {
return newStream(txId, (IPartitionedTridentSpout) dataSource);
} else if (dataSource instanceof IOpaquePartitionedTridentSpout) {
return newStream(txId, (IOpaquePartitionedTridentSpout) dataSource);
} else {
throw new UnsupportedOperationException("Unsupported stream");
}
}
- 用户在TridentTopology.newStream可以直接使用IBatchSpout类似的spout,使用它的好处就是TridentTopology在build的时候会使用BatchSpoutExecutor将其包装为ITridentSpout类型(
省得用户再去实现ITridentSpout的相关接口,屏蔽trident spout的相关逻辑,使得之前一直使用普通topology的用户可以快速上手trident topology) - BatchSpoutExecutor实现了ITridentSpout接口,将IBatchSpout适配为ITridentSpout,使用的coordinator是EmptyCoordinator,使用的emitter是BatchSpoutEmitter
- 如果用户在TridentTopology.newStream使用的spout是IPartitionedTridentSpout类型,则TridentTopology在newStream方法内部会使用PartitionedTridentSpoutExecutor将其包装为ITridentSpout类型,对于IOpaquePartitionedTridentSpout则使用OpaquePartitionedTridentSpoutExecutor将其包装为ITridentSpout类型
小结
- TridentTopology在newStream或者build方法里头会将ITridentDataSource中不是ITridentSpout类型的IBatchSpout(
在build方法)、IPartitionedTridentSpout(在newStream方法)、IOpaquePartitionedTridentSpout(在newStream方法)适配为ITridentSpout类型;分别使用BatchSpoutExecutor、PartitionedTridentSpoutExecutor、OpaquePartitionedTridentSpoutExecutor进行适配(TridentTopologyBuilder在buildTopology的时候,对于ITridentSpout类型的spout先用TridentSpoutExecutor包装,再用TridentBoltExecutor包装,最后转换为bolt,而整个TridentTopology真正的spout就是MasterBatchCoordinator;这里可以看到一个IBatchSpout的spout先经过BatchSpoutExecutor包装为ITridentSpout类型,之后再经过TridentSpoutExecutor及TridentBoltExecutor包装为bolt) - IBatchSpout的ack是针对batch维度的,也就是TransactionAttempt维度,注意这里没有fail方法,如果emitBatch方法抛出了FailedException异常,则TridentBoltExecutor会调用failBatch方法(
一个batch的tuples会等所有tuple执行完再触发checkFinish),进行reportError以及标记TrackedBatch的failed为true,之后TridentBoltExecutor在checkFinish的时候,一旦发现tracked.failed为true的时候,会调用_collector.fail(tuple),然后回调MasterBatchCoordinator的fail方法 - MasterBatchCoordinator的fail方法会将当前TransactionAttempt从_activeTx移除,然后一并移除txId大于失败的txId的数据,最后调用sync方法继续TransactionAttempt(
注意这里没有更改_currTransaction值,因而会继续从失败的txId开始重试,只有在ack方法里头会更改_currTransaction为nextTransactionId) - TridentBoltExecutor的execute方法会根据tickTuple来检测距离上次rotate是否超过_messageTimeoutMs(
取component中Config.TOPOLOGY_MESSAGE_TIMEOUT_SECS最大值*1000,这里*1000是将秒转换为毫秒),超过的话进行rotate操作,_batches的最后一个bucket将会被移除掉;这里的tickTuple的频率为5秒,Config.TOPOLOGY_MESSAGE_TIMEOUT_SECS按30秒算的话,_messageTimeoutMs为30*1000,相当于每5秒检测一下距离上次rotate时间是否超过30秒,如果超过则进行rotate,丢弃最后一个bucket的数据(TrackedBatch),这里相当于重置超时的TrackedBatch信息 - 关于MasterBatchCoordinator的fail的情况,有几种情况,一种是下游componnent主动抛出FailException,这个时候会触发master的fail,再次重试TransactionAttempt;一种是下游component处理tuple时间超过Config.TOPOLOGY_MESSAGE_TIMEOUT_SECS(
topology.message.timeout.secs,defaults.yaml中默认为30),这个时候ack会触发master的fail,导致该TransactionAttempt失败继续重试,目前没有对attempt的次数做限制,实际生产过程中要注意,因为只要该batchId的一个tuple失败,整个batchId的tuples都会重发,这个时候下游如果没有做好处理,可能会出现一个batchId中前面部分tuple成功,后面部分失败,导致成功的tuple不断重复处理(要避免失败的batch中tuples部分处理成功部分处理失败这个问题就需要配合使用Trident的State)。
doc
- Trident Spouts
- Trident State
- 聊聊storm TridentTopology的构建