一、开头要求
GitHub地址
我的伙伴的地址
二、PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟 |
| Planning | 计划 | 120 | 180 |
| · Estimate | · 估计这个任务需要多少时间 | 1440 | 1000 |
| Development | 开发 | 720 | 600 |
| · Analysis | · 需求分析 (包括学习新技术) | 300 | 240 |
| · Design Spec | · 生成设计文档 | 120 | 100 |
| · Design Review | · 设计复审 (和同事审核设计文档) | 50 | 89 |
| · Design Review | · 代码规范 (为目前的开发制定合适的规范) | 60 | 30 |
| · Design | · 具体设计 | 250 | 300 |
| · Coding | · 具体编码 | 740 | 600 |
| · Code Review | 代码复审 | 180 | 120 |
| Test | · 测试(自我测试,修改代码,提交修改) | 300 | 360 |
| Reporting | 报告 | 60 | 45 |
| · Test Report | · 测试报告 | 60 | 55 |
| · Size Measurement | · 计算工作量 | 50 | 30 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 45 | 30 |
| 合计 | 1000 | 1200 |
三、程序的实现
1、解题思路
对这个问题的大致解题阶段: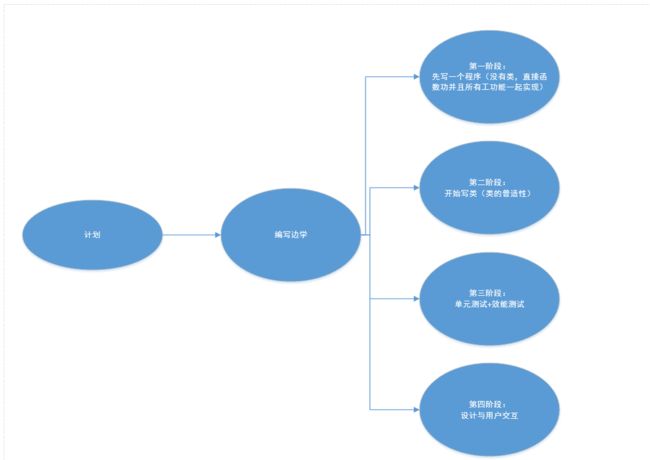
拿到这个题目的时候,因为他要实现的功能相对较多。所以,我先对每一个要实现的功能设计了函数。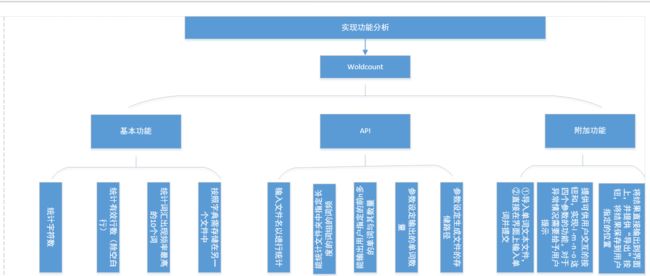
所以,我先对每一个要实现的功能设计了函数。下面是一些我认为相对来说比较麻烦的功能的实现:(1):对文件中出现的规定字符串的统计
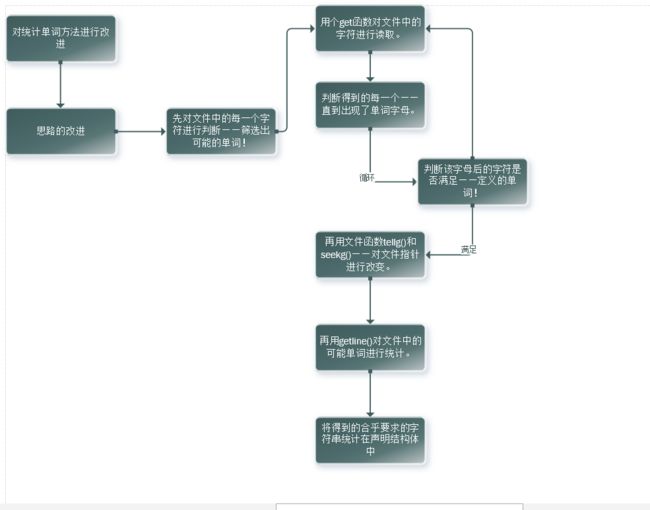
(2):统计文件中出现的规定字符串评率最大的10个字符串。
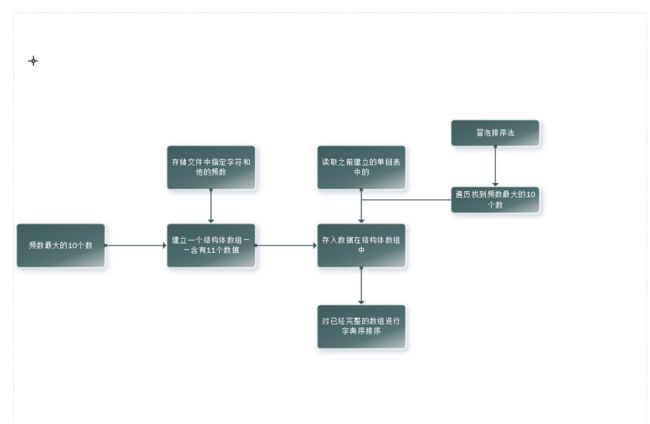
2、封装为类
一共两个类:
基类:class word_count
{
public:
void f_open();/*打开文件函数*/
void count_acill();/*统计文件中出现的acill 码*/
void count_aphabet();/*统计文件中出现的字母*/
void count_Enum();/*统计文件中出现的字母*/
void count_seperetors();/*统计文件中出现的分割符号*/
void count_line();/*存储文件中的每一行的字符串*/
void display_1();
protected:
ifstream f_in;
private:
int acill;
int aphabate;
int Enum;
int seperetors;
string line_count[MAX];
string line_count_all[MAX];
};继承类:
class word_count2 :public word_count
{
public :
void read_str();
void store_str(string s);
void display();
void count_limit();
void ruin_node();
private:
count_str *first, *rear;
};四、代码复审
(1)自我复审
写了一点代码,我发现对于像我现在这个阶段。完整的写一段代码花费时间更多的是在后面的修改代码上面。原因是:首先,自己写代码用的算法都是已经存在,没有说自己设计一个算法去写一段代码。其次,自己对很多语法不熟悉,每次编译的时候没有问题但是运行就会出错。最后,对整段代码的分析不到位,得不到自己想要的结果。
这次写代码,在写函数统计文件中出现的频数最大的10个字符串的时,就遇到了一个让我很恼火的问题。在这里我也花费了很多的时间去修改。但是最后我还是放弃了重写一段代码来代替他。
未修改前的思路: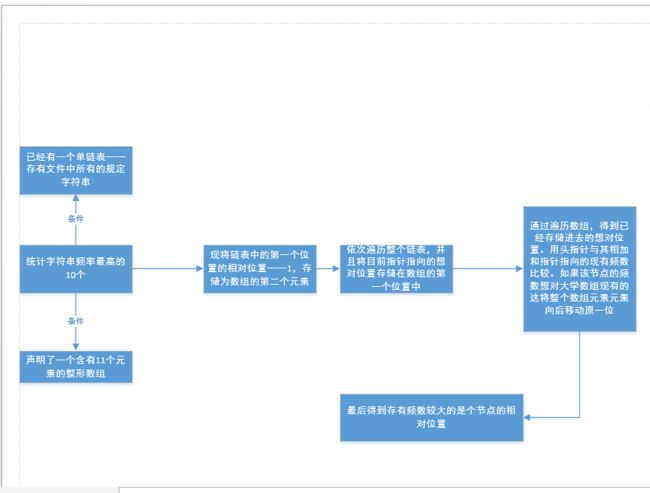
修改后的思路: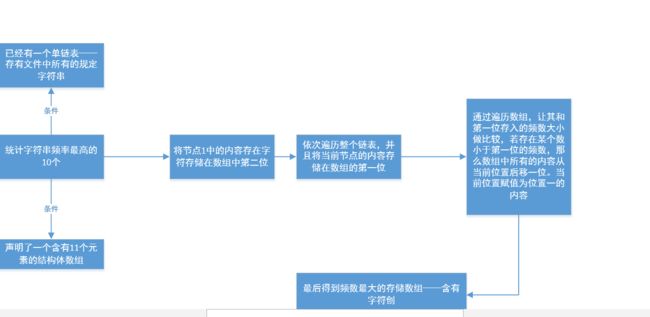
(2)同伴复审
经过了这次同伴复审后,我发觉有一个同伴来审查自己写的代码会提高自己写代码的效率。
###(1)提高自己代码的运行可信度。
这次写函数统计指定字符的时候,我忘记了"123file"这一类不是单词,不能被写入。
起始代码是这样的:void word_count2::read_str()
{
char ch;//收集每一个文件中字符
string str_1;//记录每一个规定的字符
long pos;//记录f_in的位置
int fir = 0;//判断第一个字符是否为字母
f_in.clear();
f_in.seekg(0, ios::beg);
while (!f_in.eof())
{
int read=0;
f_in.get(ch);
read++;
int k;
f_in.seekg(pos);
//f_in.get(ch);
for ( k = 1; k < 4; k++)
{
read++;
f_in.get(ch);
if ( ch<'A' || (ch > 'Z'&& ch < 'a') || ch>'z' ) break;
}
if (k == 4)
{
f_in.get(ch);
while (('a' <= ch && 'z' >= ch) || ('A' <= ch && 'Z' >= ch)|| ( '0' <= ch && ch <= '9'))
{
f_in.get(ch);
read++;
}
pos = f_in.tellg();
f_in.seekg(pos - read);
getline(f_in, str_1, ch);
store_str(str_1);
f_in.seekg(pos);
}
}
}
} 经过我的好伙伴的提醒我就有修改了代码,如下:void word_count2::read_str()
{
char ch;//收集每一个文件中字符
string str_1;//记录每一个规定的字符
long pos;//记录f_in的位置
int fir = 0;//判断第一个字符是否为字母
f_in.clear();
f_in.seekg(0, ios::beg);
while (!f_in.eof())
{
f_in.get(ch);
fir++;
if (('a' <= ch && 'z' >= ch) || ('A' <= ch && 'Z' >= ch))
{
int read=1;//记录规定字符创的长度。
//-------------------------------------------------->增加代码
if (fir == 1)
{
pos = f_in.tellg();
}
else
{
pos = f_in.tellg();
f_in.seekg(pos-1);//得到上一个字符
f_in.get(ch);
}
if (('0' <= ch && ch <= '9') || ch== '" ')
{
f_in.seekg(pos);
f_in.get(ch);
while (('a' <= ch && 'z' >= ch) || ('A' <= ch && 'Z' >= ch) || ('0' <= ch && ch <= '9'))
{
f_in.get(ch);
}
}//-------------------------------------------------------------------------------------------------------------------
else
{
read++;
int k;
f_in.seekg(pos);
//f_in.get(ch);
for ( k = 1; k < 4; k++)
{
read++;
f_in.get(ch);
if ( ch<'A' || (ch > 'Z'&& ch < 'a') || ch>'z' ) break;
}
if (k == 4)
{
f_in.get(ch);
while (('a' <= ch && 'z' >= ch) || ('A' <= ch && 'Z' >= ch)|| ( '0' <= ch && ch <= '9'))
{
f_in.get(ch);
read++;
}
pos = f_in.tellg();
f_in.seekg(pos - read);
getline(f_in, str_1, ch);
store_str(str_1);
f_in.seekg(pos);
}
}
}
}
} 这样的事情在这次的作业中还出现了很多次,这里就不在都说了。GitHub上的代码就是我和我的同伴经过相互修改后的最终结果。(2)同伴互审可以学到对方写代码很多好的方法和习惯。
1、我学到了同伴写代码时候的都看,多写的好习惯。
2、每次编写代码的时候会先写一遍伪代码。五、 计算模块部分单元测试展示。

六、异常处理
1
根据之前的作业,这一次单元测试我们仍然将**属性->链接器->输入->附加依赖项**的地址写为了Debug中的 .obj文件,但是运行包错。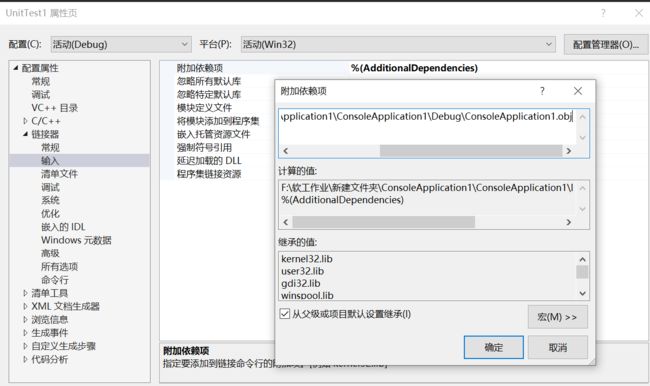

改正:
因为这一次,我们直接将类独立成了头文件,所以其实在 #include "../ConsoleApplication1/word_count.h" 这里就已经有了我们单元测试所需要的类的定义。即我们删除之前所修改的附加依赖项中的路径就好了。
2
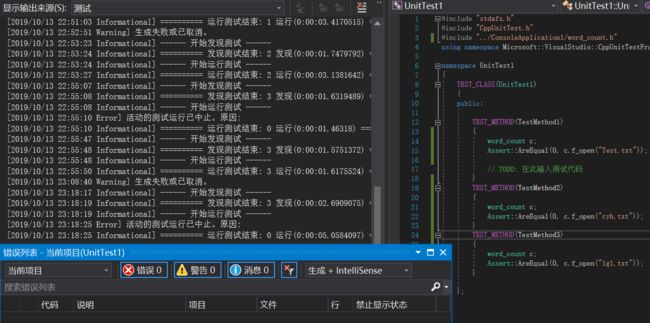
测试无法通过!
原因是我们的路径写的是相对路径,所以没办法在当前路径下找到这个 .txt文件,最后我们将文件拷贝到了Test项目下的路径。
七、性能改进
1、部分代码改进思路:

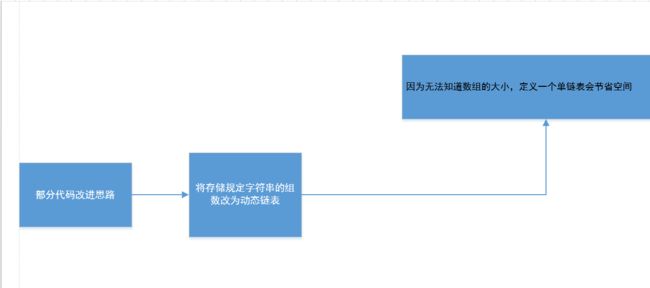
2、性能分析图:
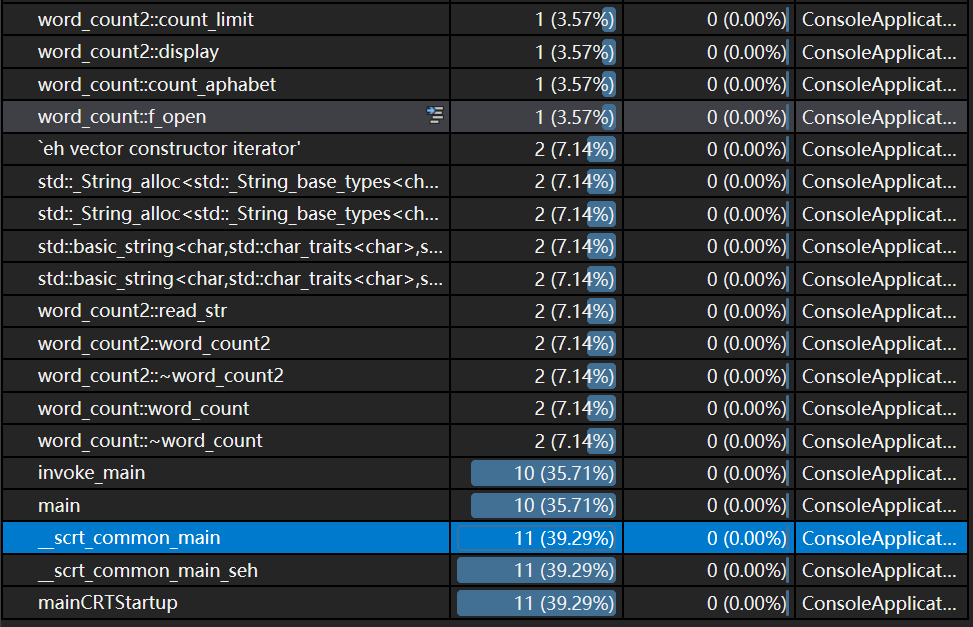
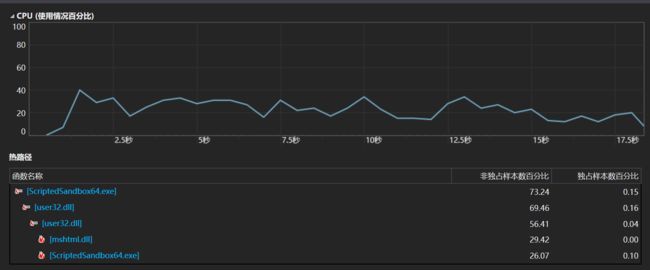
消耗最大的函数:

八代码规范
由于这是我俩第一次用c++完成一个项目,所以我们参考了网上的c++代码规范知否,知否
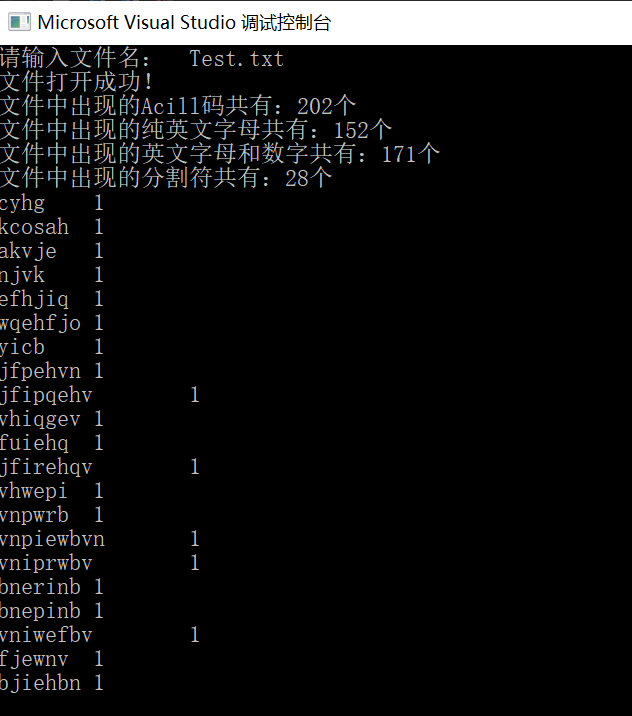
九、代码运行结果
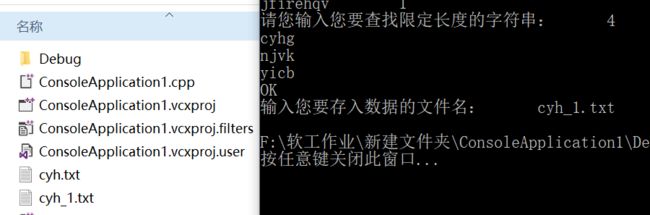
十结对编码照片

十一、作业感悟
1、结对编程让我节约了很多时间,也避免了很多不必要的错误。“人多力量大”果然正确的。就算只有两个人,也会比一个人的写代码来的好一些。
2、编写代码上思想的一些碰撞,真的会让自己收获很多!