句柄与指针的区别
学习C++的人都知道句柄和指针,而且我发现很多人在句柄与指针之间直接划等号,对我们来说两者都是地址,我觉的这也造成很多人将句柄和指针划等号的直接原因。
首先说指针吧。通俗一点就是地址,他是内存的编号,通过它我们可以直接对内存进行操作,只要地址不变,我们每次操作的物理位置是绝对不变,记住这句话,这是句柄和指针的重大区别所在。
再说说句柄吧,一般是指向系统的资源的位置,可以说也是地址。但是这些资源的位置真的不变,我们都知道window支持虚拟内存的技术,同一时间内可能有些资源被换出内存,一些被换回来,这就是说同一资源在系统的不同时刻,他在内存的物理位置是不确定的,那么window是如何解决这个问题呢,就是通过句柄来处理资源的物理位置不断变化的这个问题的。window会在物理位置固定的区域存储一张对应表,表中记录了所有的资源实时地址,句柄其实没有直接指向资源的物理地址,而是指向了这个对应表中的一项,这样无论资源怎样的换进换出,通过句柄都可以找到他的实时位置。
总的来说,通过句柄可以屏蔽系统内部的细节,让程序设计可以不必考虑操作系统实现的细节。如果还不能理解句柄与指针之间的区别,可以想象指向指针的指针,可以把句柄当作一个指向指针的指针来理解。
文件描述符fd(句柄)
在Linux系统中一切皆可以看成是文件,文件又可分为:普通文件、目录文件、链接文件和设备文件。文件描述符(file descriptor)是内核为了高效管理已被打开的文件所创建的索引,其是一个非负整数(通常是小整数),用于指代被打开的文件,所有执行I/O操作的系统调用都通过文件描述符。
在linux系统中,设备也是以文件的形式存在,要对该设备进行操作就必须先打开这个文件,打开文件就会获得文件描述符,它是个很小的正整数。每个进程在PCB(Process Control Block)中保存着一份文件描述符表,文件描述符就是这个表的索引,每个表项都有一个指向已打开文件的指针。文件描述符的优点:兼容POSIX标准,许多Linux和UNIX系统调用都依赖于它。文件描述符的缺点:不能移植到UNIX以外的系统上去,也不直观。
pipe
在Linux上,使用POSIX的condition+mutex,也能完成线程间通知,但是这种方式在linux中用得相对较少,而是大量使用pipe,创建两个fd(writeFD,readFD)。当线程1想唤醒线程2的时候,就可以往writeFD中写数据,这样线程2阻塞在readFD中就能返回。
我之前及其没搞明白为何要使用pipe,后来突然想明白了。因为Linux上阻塞的方法就是用select,poll和epoll,其中等待的都是FD,那么采用FD这种方式,能够统一调用方法。
Linux上阻塞的方法
首先我们来定义流的概念,一个流可以是文件,socket,pipe等等可以进行I/O操作的内核对象。
不管是文件,还是套接字,还是管道,我们都可以把他们看作流。
之后我们来讨论I/O的操作,通过read,我们可以从流中读入数据;通过write,我们可以往流写入数据。现在假定一个情形,我们需要从流中读数据,但是流中还没有数据,(典型的例子为,客户端要从socket读如数据,但是服务器还没有把数据传回来),这时候该怎么办?
-
阻塞:阻塞是个什么概念呢?比如某个时候你在等快递,但是你不知道快递什么时候过来,而且你没有别的事可以干(或者说接下来的事要等快递来了才能做);那么你可以去睡觉了,因为你知道快递把货送来时一定会给你打个电话(假定一定能叫醒你)。
-
非阻塞忙轮询:接着上面等快递的例子,如果用忙轮询的方法,那么你需要知道快递员的手机号,然后每分钟给他挂个电话:"你到了没?"
很明显一般人不会用第二种做法,不仅显很无脑,浪费话费不说,还占用了快递员大量的时间。
大部分程序也不会用第二种做法,因为第一种方法经济而简单,经济是指消耗很少的CPU时间,如果线程睡眠了,就掉出了系统的调度队列,暂时不会去瓜分CPU宝贵的时间片了。
缓冲区
为了了解阻塞是如何进行的,我们来讨论缓冲区,以及内核缓冲区,最终把I/O事件解释清楚。
缓冲区的引入是为了减少频繁I/O操作而引起频繁的系统调用(你知道它很慢的),当你操作一个流时,更多的是以缓冲区为单位进行操作,这是相对于用户空间而言。对于内核来说,也需要缓冲区。
假设有一个管道,进程A为管道的写入方,B为管道的读出方。
-
假设一开始内核缓冲区是空的,B作为读出方,被阻塞着。然后首先A往管道写入,这时候内核缓冲区由空的状态变到非空状态,内核就会产生一个事件告诉B该醒来了,这个事件姑且称之为" 缓冲区非空"。
-
但是" 缓冲区非空"事件通知B后,B却还没有读出数据;且内核许诺了不能把写入管道中的数据丢掉这个时候,A写入的数据会滞留在内核缓冲区中,如果内核也缓冲区满了,B仍未开始读数据,最终内核缓冲区会被填满,这个时候会产生一个I/O事件,告诉进程A,你该等等(阻塞)了,我们把这个事件定义为" 缓冲区满"。
-
假设后来B终于开始读数据了,于是内核的缓冲区空了出来,这时候内核会告诉A,内核缓冲区有空位了,你可以从长眠中醒来了,继续写数据了,我们把这个事件Y1叫做" 缓冲区非满"。
-
也许事件Y1已经通知了A,但是A也没有数据写入了,而B继续读出数据,直到内核缓冲区空了。这个时候内核就告诉B,你需要阻塞了!,我们把这个时间定为" 缓冲区空"。
这四个情形涵盖了四个I/O事件,缓冲区满,缓冲区空,缓冲区非空,缓冲区非满(注:都是说的内核缓冲区,且这四个术语都是我生造的,仅为解释其原理而造)。这四个I/O事件是进行阻塞同步的根本。
select/poll
然后我们来说说阻塞I/O的缺点。阻塞I/O模式下,一个线程只能处理一个流的I/O事件。如果想要同时处理多个流,要么多进程(fork),要么多线程(pthread_create),很不幸这两种方法效率都不高。
于是再来考虑非阻塞忙轮询的I/O方式,我们发现我们可以同时处理多个流了(把一个流从阻塞模式切换到非阻塞模式再此不予讨论):
while true { for i in stream[]; { if i has data read until unavailable } }
我们只要不停的把所有流从头到尾问一遍,又从头开始。这样就可以处理多个流了,但这样的做法显然不好,因为如果所有的流都没有数据,那么只会白白浪费CPU。这里要补充一点,阻塞模式下,内核对于I/O事件的处理是阻塞或者唤醒,而非阻塞模式下则把I/O事件交给其他对象(后文介绍的select以及epoll)处理甚至直接忽略。
为了避免CPU空转,可以引进了一个代理(一开始有一位叫做select的代理,后来又有一位叫做poll的代理,不过两者的本质是一样的)。这个代理比较厉害,可以同时观察许多流的I/O事件,在空闲的时候,会把当前线程阻塞掉,当有一个或多个流有I/O事件时,就从阻塞态中醒来,于是我们的程序就会轮询一遍所有的流(于是我们可以把"忙"字去掉了)。代码长这样:
while true { select(streams[]) for i in streams[] { if i has data read until unavailable } }
于是,如果没有I/O事件产生,我们的程序就会阻塞在select处。但是依然有个问题,我们从select那里仅仅知道了,有I/O事件发生了,但却并不知道是那几个流(可能有一个,多个,甚至全部),我们只能无差别轮询所有流,找出能读出数据,或者写入数据的流,对他们进行操作。
但是使用select,我们有O(n)的无差别轮询复杂度,同时处理的流越多,每一次无差别轮询时间就越长。再次说了这么多,终于能好好解释epoll了。
epoll
epoll可以理解为event poll,不同于忙轮询和无差别轮询,epoll会把哪个流发生了怎样的I/O事件通知我们。此时我们对这些流的操作都是有意义的。(复杂度降低到了O(1))
epoll支持四类事件,分别是EPOLLIN(句柄可读)、EPOLLOUT(句柄可写),EPOLLERR(句柄错误)、EPOLLHUP(句柄断)。
在讨论epoll的实现细节之前,先把epoll的相关操作列出:
-
epoll_create 创建一个epoll对象,一般epollfd = epoll_create()
-
epoll_ctl (epoll_add/epoll_del的合体),往epoll对象中增加/删除某一个流的某一个事件
-
epoll_ctl(epollfd, EPOLL_CTL_ADD, socket, EPOLLIN);//注册缓冲区非空事件,即有数据流入
-
epoll_ctl(epollfd, EPOLL_CTL_DEL, socket, EPOLLOUT);//注册缓冲区非满事件,即流可以被写入
-
-
epoll_wait(epollfd,...)等待直到注册的事件发生
(注:当对一个非阻塞流的读写发生缓冲区满或缓冲区空,write/read会返回-1,并设置errno=EAGAIN。而epoll只关心缓冲区非满和缓冲区非空事件)。
一个epoll模式的代码大概的样子是:
while true { active_stream[] = epoll_wait(epollfd) for i in active_stream[] { read or write till } }
限于篇幅,我只说这么多,以揭示原理性的东西,至于epoll的使用细节,请参考man和google,实现细节,请参阅linux kernel source。
1.Android中为什么主线程不会因为Looper.loop()里的死循环卡死?
这里涉及线程,先说说说进程/线程,进程:每个app运行时前首先创建一个进程,该进程是由Zygote fork出来的,用于承载App上运行的各种Activity/Service等组件。进程对于上层应用来说是完全透明的,这也是google有意为之,让App程序都是运行在Android Runtime。大多数情况一个App就运行在一个进程中,除非在AndroidManifest.xml中配置Android:process属性,或通过native代码fork进程。
线程:线程对应用来说非常常见,比如每次new Thread().start都会创建一个新的线程。该线程与App所在进程之间资源共享,从Linux角度来说进程与线程除了是否共享资源外,并没有本质的区别,都是一个task_struct结构体,在CPU看来进程或线程无非就是一段可执行的代码,CPU采用CFS调度算法,保证每个task都尽可能公平的享有CPU时间片。
有了这么准备,再说说死循环问题:
对于线程既然是一段可执行的代码,当可执行代码执行完成后,线程生命周期便该终止了,线程退出。而对于主线程,我们是绝不希望会被运行一段时间,自己就退出,那么如何保证能一直存活呢?简单做法就是可执行代码是能一直执行下去的,死循环便能保证不会被退出,例如,binder线程也是采用死循环的方法,通过循环方式与不同Binder驱动进行读写操作,当然并非简单地死循环,无消息时会休眠。但这里可能又引发了另一个问题,既然是死循环又如何去处理其他事务呢?通过创建新线程的方式。
真正会卡死主线程的操作是在回调方法onCreate/onStart/onResume等操作时间过长,会导致掉帧,甚至发生ANR,looper.loop本身不会导致应用卡死。
ActivityThread的main源码:
public static void main(String[] args) { ......(省略) Looper.prepareMainLooper(); ActivityThread thread = new ActivityThread(); thread.attach(false); if (sMainThreadHandler == null) { sMainThreadHandler = thread.getHandler(); } if (false) { Looper.myLooper().setMessageLogging(new LogPrinter(Log.DEBUG, "ActivityThread")); } // End of event ActivityThreadMain. Trace.traceEnd(Trace.TRACE_TAG_ACTIVITY_MANAGER); Looper.loop();// 会死循环,从而使主线程一直运行下去 throw new RuntimeException("Main thread loop unexpectedly exited"); }
2.没看见哪里有相关代码为这个死循环准备了一个新线程去运转?
事实上,会在进入死循环之前便创建了新binder线程,在代码ActivityThread.main()中:
public static void main(String[] args) { .... //创建Looper和MessageQueue对象,用于处理主线程的消息 Looper.prepareMainLooper(); //创建ActivityThread对象 ActivityThread thread = new ActivityThread(); //建立Binder通道 (创建新线程) thread.attach(false); Looper.loop(); //消息循环运行 throw new RuntimeException("Main thread loop unexpectedly exited"); }
thread.attach(false);便会创建一个Binder线程(具体是指ApplicationThread,Binder的服务端,用于接收系统服务AMS发送来的事件),该Binder线程通过Handler将Message发送给主线程,具体过程可查看 startService流程分析,这里不展开说,简单说Binder用于进程间通信,采用C/S架构。关于binder感兴趣的朋友,可查看我回答的另一个知乎问题:
为什么Android要采用Binder作为IPC机制? - Gityuan的回答
另外,ActivityThread实际上并非线程,不像HandlerThread类,ActivityThread并没有真正继承Thread类,只是往往运行在主线程,给人以线程的感觉,其实承载ActivityThread的主线程就是由Zygote fork而创建的进程。
3.主线程的死循环一直运行是不是特别消耗CPU资源呢?
其实不然,这里就涉及到Linux pipe/epoll机制,简单说就是在主线程的MessageQueue没有消息时,便阻塞在loop的queue.next()中的nativePollOnce()方法里,详情见Android消息机制1-Handler(Java层),此时主线程会释放CPU资源进入休眠状态,直到下个消息到达或者有事务发生,通过往pipe管道写端写入数据来唤醒主线程工作。这里采用的epoll机制,是一种IO多路复用机制,可以同时监控多个描述符,当某个描述符就绪(读或写就绪),则立刻通知相应程序进行读或写操作,本质同步I/O,即读写是阻塞的。 所以说,主线程大多数时候都是处于休眠状态,并不会消耗大量CPU资源。
4.Activity的生命周期是怎么实现在死循环体外能够执行起来的?
ActivityThread的内部类H继承于Handler,通过handler消息机制,简单说Handler机制用于同一个进程的线程间通信。
Activity的生命周期都是依靠主线程的Looper.loop,当收到不同Message时则采用相应措施:
在H.handleMessage(msg)方法中,根据接收到不同的msg,执行相应的生命周期。
比如收到msg=H.LAUNCH_ACTIVITY,则调用ActivityThread.handleLaunchActivity()方法,最终会通过反射机制,创建Activity实例,然后再执行Activity.onCreate()等方法;
再比如收到msg=H.PAUSE_ACTIVITY,则调用ActivityThread.handlePauseActivity()方法,最终会执行Activity.onPause()等方法。 上述过程,我只挑核心逻辑讲,真正该过程远比这复杂。
主线程的消息又是哪来的呢?
当然是App进程中的其他线程通过Handler发送给主线程,请看接下来的内容:
最后,从进程与线程间通信的角度,通过一张图加深大家对App运行过程的理解: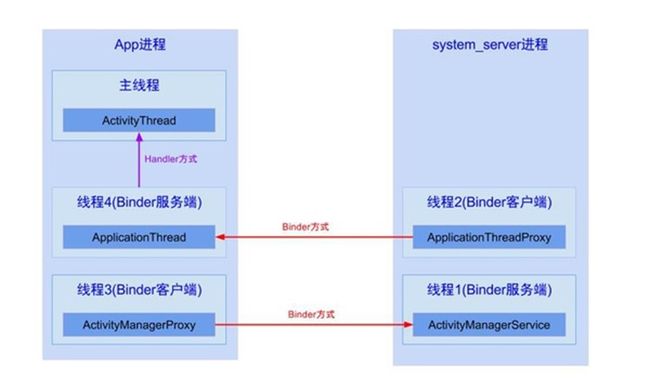
system_server进程是系统进程,java framework框架的核心载体,里面运行了大量的系统服务,比如这里提供ApplicationThreadProxy(简称ATP),ActivityManagerService(简称AMS),这个两个服务都运行在system_server进程的不同线程中,由于ATP和AMS都是基于IBinder接口,都是binder线程,binder线程的创建与销毁都是由binder驱动来决定的。
App进程则是我们常说的应用程序,主线程主要负责Activity/Service等组件的生命周期以及UI相关操作都运行在这个线程; 另外,每个App进程中至少会有两个binder线程 ApplicationThread(简称AT)和ActivityManagerProxy(简称AMP),除了图中画的线程,其中还有很多线程,比如signal catcher线程等,这里就不一一列举。
Binder用于不同进程之间通信,由一个进程的Binder客户端向另一个进程的服务端发送事务,比如图中线程2向线程4发送事务;而handler用于同一个进程中不同线程的通信,比如图中线程4向主线程发送消息。
结合图说说Activity生命周期,比如暂停Activity,流程如下:
-
线程1的AMS中调用线程2的ATP;(由于同一个进程的线程间资源共享,可以相互直接调用,但需要注意多线程并发问题)
-
线程2通过binder传输到App进程的线程4;
-
线程4通过handler消息机制,将暂停Activity的消息发送给主线程;
-
主线程在looper.loop()中循环遍历消息,当收到暂停Activity的消息时,便将消息分发给ActivityThread.H.handleMessage()方法,再经过方法的调用,最后便会调用到Activity.onPause(),当onPause()处理完后,继续循环loop下去。