当数据量增大到超出了单个物理计算机存储容量时,有必要把它分开存储在多个不同的计算机中。那些管理存储在多个网络互连的计算机中的文件系统被称为“分布式文件系统”。由于这些计算机是基于网络连接的,所以网络编程的那些复杂性都会涉及,这也造成了分布式文件系统比一般的磁盘存储文件系统更复杂。例如,其中最大的一个难题是如何使文件系统因其中一个节点失败而不造成数据丢失。
Hadoop使用的分布式文件系统称为HDFS,即Hadoop Distributed Filesystem。在非正式或早期文档或配置文件中见到DFS也指的是HDFS。HDFS是Hadoop最重要的文件系统,是这章节要讲的核心。但是Hadoop实际上具有通用文件系统抽象层,所以我们也顺便看一下Hadoop如何与其它存储系统集成,例如本地文件系统和Amazon S3。
HDFS的设计
设计HDFS的目的是为了能够存储非常大体积的文件,这些文件能够以流的方式访问,并能够运行于一般日常用的硬件设备集群中。让我们更详细地说明一下这句话的意思。
非常大体积的文件
这里的"非常大"意思是文件的大小是几百M,几百G或者几百T。今天的运行的Hadoop集群能够存储P级数据。
流式数据访问
HDFS认为一次写入,多次读取的模式是最高效的处理模式,它围绕着这个模式建立。数据集通常都是自生成或从源数据复制,然后随着时间推移会进行多次分析。每次分析可能不是所有数据,但也会是占数据集很大比例的数据,所以读取整个数据集所花的时间比读取第一条数据延迟的时间更重要。
日常用的硬件设备
Hadoop不要求昂贵的,高可靠的硬件。它被设计能够运行于一般常用的硬件之上。常用的硬件指的是能够从多个供应商购买到的一般的可用的硬件。这种便件集群中节点失败的可能性更大,至少对于大的集群来说是这样。HDFS被设计的目的就是当节点失败时能够继续运行,而不会让用户察觉到明显的中断。
并不是所有应用领域HDFS都有出色的表现,虽然这可能在将来改变。有如下领域HDFS不太适合:
- 低延迟数据读取
那些要求数据读取几十毫秒延迟的应用不适合使用HDFS。记住,HDFS对于传输高吞吐量数据进行了优化,这也许以延迟为代价。HBase当前是低延迟比较好的选择,见第20章节。 - 大量的小文件
由于文件元数据存储在内存中的名称结点中,所以内存中名称节点大小决定了能够存储文件的数量。根据经验,每一个文件名,目录或块名占用150字节,所以如果你有一百万个文件,每一个文件占一块,你将至少需要300M内存空间。虽然存储几百万个文件是没问题的,但存储十亿个文件就超出了当前硬件能够容纳的数量。 - 多个写入器,文件任意修改
HDFS的文件只有一个写入器,并且只在文件结束时以追加的方式写入。不支持多个写入器或者能在文件当中任意一个位置修改。这也许在将来被支持,但它们很可能相对低效一些。
Hadoop概念
块
硬盘中的块指一次读取或写入的最小单位数量。基于此的单块硬盘的文件系统处理多块中的数据,处理的块大小是单块大小的整数倍。文件系统块大小通常是几M大小,而硬盘中的块大小正常是512字节。这对于操作文件系统的用户来说是透明的。这些用户仅仅需要读取或写入任意长度的文件即可,不用关心块大小。然后,有一些工具可以维护文件系统,例如df和fsck.这些工具直接在块级别操作。
HDFS也有块的概念。但它的块单元要大小一些,一般默认是128MB。和单块硬盘的文件系统一样,HDFS中的文件也会按照块大小被拆分独立存储,而不同的是,比一块大小小的数据不会占用一块的空间,例如块大小是128M,而文件大小是1M,则此文件只使用了1M空间,而不是128M。没有特殊说明,本书中的"块"指的是HDFS中的块。
为什么HDFS中的块默认这么大?
HDFS块跟比硬盘中块要大的多,目的是为了减少查找的开销。如果块足够大,将数据从硬盘中读取出来的时间将会比寻找块起始地址所花的时候要多的多。因此传输一个由多个块组成的大文件时,传输时间主要取决于硬盘的传输速率。
让我们简单计算一下,如果寻址时间是10ms,传输速率是100M/s。为了使寻址时间占传输时间的1%,我们设置块大小为100M。默认块大小时128M,而一些HDFS安装说明建议设置更大的块。随着新一代的硬盘驱动安装,传输速率增加,这个值会越来越大。然而这个值不能设置的太大,因为MapReduce中的map任务通常一次在一块上执行,如果你有很多map任务,比集群中的节点还多,这时候,作业运行的时候比它应该运行的时间要慢一些。
对分布系统来说,有抽象的块有几个优势。第一个优势也是最明显的:一个文件可能比互联网中任意一个单块硬盘容量都要大,也没有理由要求文件的块都存储在一块硬盘中。所以可以利用集群中所有的硬盘。事实上,一个文件的块可以占满集群中所有硬盘的空间,虽然这不常发生。
第二,将块做为抽象单元而不是文件简化了存储子系统。简单是所有系统都努力追求的。这对于分布式系统来说尤其重要,因为分布式系统失败的情况各种各样。存储子系统操作块仅仅是简单地管理存储,因为块的大小固定,所以很容易计算出指定的硬盘中能够有多少块。并且存储子系统不需要关心元数据。因为块仅存储数据,文件的元数据,例如权限信息不需要存储在块中,有另外一个系统单独管理。
最后,块对于容灾和数据获取都表现不错。为了应对块,硬盘或计算机损块,每一个块中的数据都会被复制到独立的几个物理计算机中(通常是3个)。如果某一块中的数据不能获取,可以以某一种方法从另外一个位置读取块的复本。这些操作对客户来说是透明的。而且如果一个块数据不能读取,Hadoop就会从其它替代位置读取块内容到另外一个正在运行的计算机中以便让复制参数回到正常水平(可以看"数据健壮性"那一章节了解更多应对数据损多方法)。类似的,许多应用对于经常使用的文件选择设置高的复制参数,以便在集群中更多地方可以读取到。
像文件系统中的fsck一样,hadoop的fsck命令也能操作块,例如运行下面命令:
% hdfs fsck / -files -blocks
就会列出文件系统中包含文件数据的所有块(可以参看"文件系统检查(fsck)"章节)。
名称节点和数据节点
一个HDFS集群有两种节点类型。它们以主-从形式工作。一个名称节点(主)和多个数据节点(从)。名称节点管理文件系统命名空间。维护文件系统树和树中所有文件和目录的元信息。这些信息以命名空间镜像和更改日志两种形式永久存储在本地硬盘中。从名称节点可以查到数据节点。这些数据节点存储着文件的块数据。然而这些块并不会永久存储。因为当系统启动时,这些块会重新在数据节点中建立。
代表用户的客户端通过与名称节点和数据节点沟通操作文件系统。客户端会提供类似可移植操作系统接口(Portable Operating System Interface POSIX)的文件系统接口。所以用户开发的时候不需要知道怎么操作名称节点和数据节点。
数据节点是文件系统中苦力劳作者。他们存储块数据,并按照客户端或名称节点的要求返回块数据。他们会定期地向名称节点返回他们存储的块列表。
没有名称节点,文件系统无法使用。事实上,如果运行名称节点的计算机彻底损毁了,所有文件将会丢失。因为根本没法知道怎么样根据数据节点中的块重新生成文件。由于这个原因,能够在当名称节点损坏后恢复显得非常重要。Hadoop提供了两种机制达到这个目的。
第一种方法是备份存储着文件元信息的文件。能够配置Hadoop使名称节点中的数据能够自动地同步地写入多个文件系统。通常的配置是一份存储在本地系统,另外一份存储在远程的NFS系统中。
第二种方法是运行另外一个名称节点,尽管它叫做名称节点,但它和名称节点的作用不一样。它的作用主要是根据更改日志合并名称节点镜像文件,以免更改日志过大。第二名称节点通常在单独的一个物理机中运行,因为它需要大量占用CPU,并且需要与名称节点一样多的内存空间以便执行合并。它还保持着合并后名称节点的复本,以便当名称节点失败后能够使用。然而,由于第二名称节点的状态更新比主计算机慢,所以当主计算机完全损坏时,数据几乎肯定会丢失。这种情况发生时,通常的做法是从远程NFS复制一份名称节点元数据文件到第二节点,并把第二节点所在的计算机做为主计算机运行(注意:可以运行一个热备用名称节点而不使用第二节点,如“HDFS高可用性”中所讨论的那样),可以参看"文件系统镜像和更改日志"章节了解更详细信息。
块缓存
正常情况下,数据节点会从硬盘中读取块数据。但是对于需要频繁读取的文件,这些块数据可以被缓存在非堆栈的数据节点内存中。虽然在以文件为基础的系统中,可以配置一个块数据缓存在几个数据节点中,但默认情况下,一个块数据仅仅缓存在一个数据节点内存中。作业调试器(例如:MapReduce,Spark或者其它框架)在缓存了块数据的数据节点上运行任务时能够利用这些缓存的块数据以提高读取性能。例如,一个小的用于连接查询的表就比较适合于缓存。
用户或应用通过向缓存池中发送一个缓存命令告诉名称节点那些文件需要缓存,缓存多久。缓存池是一个管理型组织,管理着缓存权和资源使用权。
HDFS联盟
名称节点会在内存中保存文件系统中所有文件和块的引用。也就是说在有着非常多的文件的大集群中,内存的大小存为了集群扩充的限制(看"一个名称节点需要多大内存?"章节)。HDFS联盟是Hadoop 2.x系统介绍的一种解决方法。它允许集群可以通过增加名称节点扩充。每一个名称节点管理着文件系统的一部分。例如:一个名称节点管理着/user目录下所有文件,另一个名称节点管理着/share目录下所有文件。
在联盟形式下,每一个名称空间管理一个命名空间卷和一个块池。命名空间卷由命名空间的元信息组成。块池则包括命名空间下所有文件的所有块数据。命名空间卷相互独立,意味着名称节点相互独立,更进一步地讲,某一个名称节点毁坏了不会影响到被其它名称节点管理的命名空间的数据获取。然而,块池不是分区的,所以集群中数据节点可以被注册在任意一个名称节点中,并且可以存储来自多个块池中的块。
为了配置一个HDFS联盟的集群,客户端需使用存放在客户端的表来把文件路径映射每一个名称节点。可以通过ViewFileSystem和viewfs://URIs进行配置。
HDFS高可用性
将名称节点中保存在多个文件系统中和使用第二名称节点创建检查点,这两者的目的都是为了防止数据丢失,然后它并不能保证文件系统的高可用性。名称节点仍然会有单点故障。如果出现故障,所有的客户端包括MapReduce作业等将将不能读取,写入数据或者显示文件。因为名称节点是元数据和文件与块对应关系存储的唯一仓库。如果出现如此情况,整个Hadoop系统将很快中断服务,直到一个新的名称节点启用。
在名称节点失败后,为了恢复,管理者必须从所有文件系统元数据备份中选择一个备份作为主名称节点启用,并配置数据节点和客户端使用这个新的名称节点。启用后这个新节点并不能立即投入使用。直到(1)节点中命名空间镜像载入内存;(2)重新根据更改日志执行一遍失败的操作;(3)收到足够多的来自数据节点中块的报告表明其已离开安全模式,这三步完成后才会启用。在有大量文件和块的集群中,冷启动一个名称节点需要花费30分钟或更多。
长的恢复时间对于运维来说是一个问题。事实上,名称节点不可预料的失败发生的情况少之又少,而计划的停机事件在实际中显得更重要。
Hadoop2通过提供HDFS高可用性(HA)改善了这种状况。实现上是有两个名称节点,一个激活状态,一个备用状态。当激活状态的名称节点失败之后,备用名称节点立即会接替它的任务,服务客户端的请求。客户端不会感觉到明显的中断。要想实现HA,需要做一些结构上的改变。
- 两个名称节点必须能够使用高速访问的存储空间共享更改日志。当备用的名称节点运行的时候,它会读取更改日志所有内容,并同步状态,然后当激活名称节点写入新内容时,再读取新的状态同步。
- 数据节点必须将块报告发送给这两个名称节点,因为块之间的映射关系存储在名称节点内存中,而不是在硬盘中。
- 使用一种对用户透明的机制,客户端必须要被设置成能够处理名称节点的失败后的备援。
- 这个备用的名称节点包含了第二节点的角色,会对激活的名称节点中的命名空间进行定期检查。
对于高访问的共享存储有两种选择:NFS和QJM(a quorum journal manager)。QJM是专门为HDFS实现的,设计的唯一目的就是能够快速访问更改日志,它是大部分HDFS安装说明推荐的选择。QJM以日志节点组形式运行,每一次更改都会被写入大量的日志节点中。通常会有三个日志节点,所以系统能够容忍它们其中的一个损坏。这样的方式与ZooKeeper工作方式类似,但是QJM的实现并没有使用ZooKeeper。然后,需要注意的是,HDFS HA确实使用了ZooKeeper来选择激活的名称节点,下一部分会讲到。
如果激活的名称节点失败了,备用名称节点一般会在几十秒之内替代失败的节点。因为还需要获取最新的更改日志和更新的块映射关系。实际观察到的替代时间将会更长,一般在一分钟左右,因为系统需要确定激活的名称节点确实失败了。
还有一种不太可能发生的情况,当激活的名称节点失败后,备用的也停止了工作,管理员仍然能够冷启动备用名称节点。这也比没有HA的情况要好。从可操作性角度来看,这是一个进步,因为这个过程是一个内嵌在Hadoop中的标准操作过程。
失败备援(Failover)和筑围(Fencing)
从激活的名称节点切换到备用节点由系统中"失败备援控制器"管理。有各种各样的失败备援控制器,但是默认是使用ZooKeeper确保只有一个名称节点是激活的。每一个名称节点都对应运行一个轻量级的失败备援控制器进程,这些控制器进程的作用是通过简单心跳的机制监视名称节点,看它是否失败,并激活备用节点。
失败备援也能够由管理员发起,例如在日常维护中。这被称为"优雅的失败备援"。因为控制器会在在这两个名称节点间进行有序地过渡以交换角色。然而在不优雅地失败备援情况下,不可能确定失败的名称节点已经停止运行了。例如,缓慢的网络或网络不通都能触发失败备援切换。被切换掉的前一个激活的名称节点仍然在运行,仍然认为它自己是激活的节点。HA的实例会使用叫做"筑围(Fencing)"的方法尽全力确保先前的激活节点不能够对系统造成任何损害或引起系统瘫痪。
QJM仅仅允许同一时间有一个名称节点编辑更改日志。然而先前激活的名称节点仍然可能会响应切换前来自客户端的请求。所以好的办法是启动一个SSH筑围命令杀死这个名称节点的进程。当使用NFS做为更改日志存储的时候,需要更强大的筑围,因为此时不可能保证同一时间只有一个名称节点编辑更改日志(这也是推荐使用QJM的原因)。这种更强大的筑围机制的作用包括撤消名称节点访问共享存储目录权限(通常情况下使用供应商提供的NFS命令)和通过远程管理命令关闭它的网络端口。还有最后一种方法,使用被大众所熟知的“STONITH”技术(shoot the other node in the head),它会通过专业的电源分配单元强制关闭主机电源。
失败备援由客户端库透明处理,最简单的实现方法是配置客户端的配置文件。在配置文件中,HDFS URI使用一个逻辑主机名,并把它映射到两个名称节点地址。客户端库会尝试每一个名称节点地址直到操作成功完成。
命令行接口
我们将以命令行的方式来看一看怎么样与HDFS交互。有很多其它针对HDFS的接口,但是命令行是最简单的方式之一,也是许多开发者欢迎的方式。
我们首先在一台服务器上运行HDFS,按照附录A中的说明搭建一台伪分布式的Hadoop服务器。稍后,我们将在集群中运行HDFS,让它具备可扩展和容错性。
配置伪分布的系统,需要配置两个属性。第一个是属性是fs.defaultFS,设置成hdfs://localhost/,这个属性用于设置HDFS默认的文件系统。文件系统通过URI来指定,这里我们配置了hdfs URI,让Hadoop默认使用HDFS。HDFS将根据这个属性得到主机名和端口,给HDFS名称节点使用。HDFS将会在localhost,默认8020端口上运行。客户端也能根据这个属性知道名称节点在哪里运行,以便客户端能连接到名称节点。
第二个属性dfs.replication设置成1,这样HDFS不会按照默认值3复制文件系统块。当在单个数据节点上运行时,HDFS不能够将数据块复制到3个数据节点中时,它将会一直警告块需要复制。配置成1就解决了这个问题。
基本的文件系统操作
当文件系统准备好的时候,我们就能够进行一些常规的文件操作了。例如读取文件,创建目录,移动文件,删除数据,列出文件目录等操作。你可以在每一个命令后键入hadoop fs -help得到命令详细帮助信息。
将本地硬盘上的一个文件复制到HDFS中:
% hadoop fs -copyFromLocal input/docs/quangle.txt \
hdfs://localhost/user/tom/quangel.txt
这条命令使用了Hadoop文件系统Shell命令fs。这个命令包含一些子命令。我们刚才用-copyFromLocal 来表示将quangle.txt复制到HDFS中的/user/tom/quangle.txt中。事实上,我们可以隐去URI中的协议和主机名,hadoop会默认去core-site.xml中去取hdfs://localhost.
% hadoop fs -copyFromLocal input/docs/quangle.txt /user/tom/quangle.txt
我们也可以使用相对路径,将文件复制到HDFS的根目录中。我们这个例子中根目录是/user/tom:
% hadoop fs -copyFromLocal input/docs/quangle.txt quangle.txt
让我们再把文件从HDFS中复制回本地文件系统,并检查一下他们是否一样。
% hadoop fs -copyToLocal quangle.txt quangle.copy.txt
%md5 input/docs/quangle.txt quangle.copy.txt
MD5 (input/docs/quangle.txt) = e7891a2627cf263a079fb0f18256ffb2
MD5 (quangle.copy.txt) = e7891a2627cf263a079fb0f18256ffb2
可以看出MD5码是一样的,表明这个文件成功复制到HDFS后,仍然完好无损地复制回来了。
最后,让我们看一下一个列举HDFS文件的命令。我们首先创建了一个目录,然后看看怎么列举文件:
% hadoop fs -mkdir books
% hadoop fs -ls
drwxr-xr-x - tom supergroup 0 2014-10-04 13:22 books
-rw-r--r-- 1 tom supergroup 119 2014-10-04 13:21 quangle.txt
返回的信息跟Unix命令ls -l返回的信息很相似。但有一些小的区别。第一列显示文件权限模式,第二列显示文件的复制参数(这是传统的Unix文件系统没有的)。还记得我们在站点范围的配置文件中配置的默认复制参数是1吧,这就是为什么我们能在这里看见了相同的值。这个值对于目录来说是空的,因为复制不会应用到目录,目录属于元数据,它们被存储在名称节点中,不是数据节点。第三和第四列分别显示这个文件的所有者和所属的组。第五列以字节形式显示这个文件的大小,目录大小为0。第6和第7列显示文件或目录最后被编辑的日期和时间。最后,第8列显示文件或目录的名字。
HDFS中文件的权限
HDFS对于文件和目录有一种权限控制模式,就像POSIX一样。有三种权限:读权限(r),写权限(w),,执行权限(x)。读权限可以用于读取文件或列举目录下的所有文件内容。写权限可以用于编辑文件,对于目录来说,可以创建或删除目录中的文件或目录。HDFS中的文件没有执行权限,因为HDFS不允许执行文件,这与POSIX不一样,至于目录,执行权限可以用于获取子目录。
每一个文件或目录都有一个所有者,一个组和一个模型。这个模型由三部分用户地权限组成,一部分是所有者权限,一部分是组中成员权限,还有一部分是既不是所有者也不是组成员的用户权限。
默认情况下,Hadoop没有开启安全验证功能,这就意味着客户的身份不会被验证。因为客户是远程的,客户就可以简单地通过创建账号变成任意一个用户。如果开启了安全验证功能,这就不可能发生,详细信息见"安全性"章节。还有另外一个值得开启安全验证的原因,那就是为了避免文件系统的重要部分遭到意外的修改或删除,不管是被用户或者自动修改的工具或程序修改。
权限验证开启后,如果客户端的用户是所有者,则使用所有者权限验证,如果客户端用户是组中的一个成员,则使用组权限验证,如果都不是,则使用其它设定的权限验证。
Hadoop文件系统
Hadoop的文件系统是一个抽象概念。HDFS仅仅是其中一个实现。org.apache.hadoop.fs.FileSystem这个Java抽象类定义了客户访问Hadoop文件的一系统接口。有很多具体的文件系统,表3-1列举出了几个适用于Hadoop的文件系统。
| 文件系统 | URI协议 | Java的实现(所有类在包org.apache.hadoop下) | 描述 |
|---|---|---|---|
| Local | file | fs.LocalFileSystem | 一个用于本地的具体客户端校验硬盘的文件系统。对于没有校验的硬盘使用RawLocal FileSystem。见"本地文件系统" |
| HDFS | hdfs | hdfs.DistributedFileSystem | Hadoop的分布式文件系统。HDFS被设计用于和MapReduce连接进行高效地工作 |
| WebHDFS | webhdfs | hdfs.web.WebHdfsFileSystem | 提供对基于HTTP读写HDFS进行权限验证的文件系统,见"HTTP" |
| 安全的WebHDFS | swebhdfs | hdfs.web.SWebHdfsFileSystem | WebHDFS的HTTPS版本 |
| HAR | har | fs.HarFileSystem | 在另一个文件系统之上的一个文件系统,用于归档文件。Hadoop归档用于将HDFS中的文件打包归档进一个文件中,以减少名称节点所占的内存。使用hadoop archive命令创建HAR文件 |
| View | viewfs | viewfs.ViewFileSystem | 一个客户端挂载表,作用于另外一个Hadoop文件系统,通常用于对联盟名称节点创建挂载点。见"HDFS联盟" |
| FTP | ftp | fs.ftp.FTPFileSystem | 基于FTP服务的文件系统 |
| S3 | s3a | fs.s3a.S3AFileSystem | 基于Amazon S3的文件系统,代替旧的s3n(S3 native) |
| Azure | wasb | fs.azure.NativeAzureFileSystem | 基于微软Azure的文件系统 |
| Swift | swift | fs.swift.snative.SwiftNativeFile | 基于OpenStack Swift 的文件系统 |
Hadoop提供了很多接口用于操作文件系统,通常使用URI协议来选择正确的文件系统实例进行交互。我们之前所使用的文件系统shell适用于hadoop所有文件系统。例如为了列举本地硬盘根目录下所有文件,使用如下命令:
% hadoop fs -ls file:///
虽然可以运行MapReduce程序从以上任意一个文件系统获取数据,有时甚至非常方便。但当我们处理非常大批量的数据时,我们应该选择能够进行数据本地优化的分布式文件系统,尤其是HDFS(见"扩展"内容)。
接口
Hadoop是用JAVA开发的,所以大多数的Hadoop文件系统交互都是以JAVA API作为中间沟通的桥梁。例如文件系统shell就是一个JAVA应用程序,这个应用程序使用JAVA类FileSystem来操作文件。其它的文件系统接口也会在这一块简单地讨论。这些接口大多数通常在HDFS中使用,因为HDFS中一般都有现存的访问底层文件系统的接口,例如FTP客户端访问FTP,S3工具使用S3等等。但是他们中的一些适用于任意的hadoop文件系统。
HTTP
Hadoop系统的文件系统接口是用Java开发的,这就使用非JAVA应用很难与HDFS交互。当其它语言需要与HDFS交互时,我们可以使用WebHDFS提供的HTTP REST API接口,这将会容易许多。但是要注意的是HTTP接口会比原生的JAVA客户端慢,所以如果可以的话,应尽量避免进行大数据量传输。
通过HTTP协议,有两种与HDFS交互的方式。一种是直接通过HTTP与HDFS交互,还有一种是通过代理方式。客户端访问代理,代理再代表客户,通常使用DistributedFileSystem API访问HDFS。图3-1说明了这两种方式,这两种方式都是使用了WebHDFS协议.
使用第一种方法时,内嵌在名称节点和数据节点中的webservice作为WebHDFS协议的终结点(WebHDFS默认是启动的,因为dfs.webhdfs.enabled设置成了true)。文件元数据由名称节点处理,文件的读或写操作请求会首先传给名称节点,然后名称节点会向客户端返回一个HTTP重启向链接,指向数据节点,以便进行文件的流式操作。
使用第二种方法时,通过使用一个或多个独立的代理服务基于HTTP访问HDFS。这些代理是无状态的,所以它们能够在标准的负载均衡器之后。所以传向集录的请求必须经过代理,所以客户端不会直接与名称节点和数据节点交互。我们可以在代理层加入更严格的防火墙和带宽限制策略。通常Hadoop集群分布在不同的数据中心时或者需要访问外部网络云中的集群时,使用代理来传输数据。
HTTPFS代理暴露了与WebHDFS一样的HTTP(HTTPS)接口。所以客户端能够通过webhdfs(swebhdfs) URIs访问二者。HTTPFS使用httpfs.sh.script启动,并独立于名称节点和数据节点服务器,默认使用一个不同的端口监听,一般是14000端口。
C
Hadoop提供了一个叫做libhdfs的C函数库,与Java FileSystem接口功能相同。尽管它是一个访问HDFS的C函数库,但却能被用于访问任何任意的hadoop文件系统。它通过使用JNI调用Java文件系统接口。与上面讲解的WebHDFS接口类似,对应地有一个libwebhdfs库。
C API与JAVA很像,但它不如JAVA API。因为一些新的特性不支持。你可以在头文件hdfs.h中看到。这个头文件位于Apache Hadoop二进制文件分布目录中。
Apache Hadoop二进制文件中已经有为64位LInux系统预先构建好的libhdfs二进制文件。但对其它系统,你需要自己构建,可以按照原始树目录顶层的BUILDING.txt说明来构建。
NFS
通过使用Hadoop的NFSv3网关可以将HDFS挂载到本地的文件系统。然后就可以使用Unix工具,(例如ls和cat)来与文件系统交互,上传文件。通常还可以使用任意编程语言调用POSIX函数库与文件系统交互。可以向文件中追加内容,但不能随机修改文件,因为HDFS仅仅可以在文件末尾写入内容。
可以看Hadoop文档了解如何配置运行NFS网关以及怎么样从客户端连接它。
FUSE
用户空间文件系统(FileSystem in userspace)允许用户空间中实现的因为有人系统可以被集成进Unix文件系统。Hadoop的Fuse-DFS模块可以使HDFS或任意其它文件系统挂载成一个标准的本地文件系统。Fuse-DFS使用C语言实现,通过libhdfs与HDFS交互。当需要写数据的时间,Hadoop NFS网关仍然是挂载HDFS更有效的解决方案,所以应该优先于Fuse-DFS考虑。
JAVA接口
这部分,我们将会深入了解与Hadoop文件系统交互的Hadoop FileSystem类。虽然我们一般主要关注对于HDFS的实现即DistributedFileSystem,但是通常来说,你应该基于FileSystem抽象类实现你自己的代码,能够尽可能地跨文件系统。例如当测试程序的时候,这显示非常有用。因为你能够快速地测试在本地文件系统的数据。
从Hadoop URL读取数据
从hadoop文件系统读取文件最简单的方法之一是使用java.net.URL类,这个类会打开文件的流用于读取。一般的写法是:
InputStream in = null;
try {
in = new URL("hdfs://host/path").openStream();
// process in
} finally {
IOUtils.closeStream(in);
}
我们还需要做一些工作让Java能够识别Hadoop的hdfs的URL。调用URL的setURLStreamHandlerFactory()方法,传递一个FsUrlStreamHandlerFactory类的实例。一个JVM只允许调用一次这个方法。所以它通常在静态块中执行。这个限制意味着如果你的程序中某一部分,也许是不在你控制范围内的第三方组件设置了URLStreamHandlerFactory,你就不能通过这种途径从Hadoop中读取数据,下一部分将讨论另一种方法。
示例3-1显示了从Hadoop文件系统中读取文件并显示在标准输出中,就像Unix的cat命令一样。
public class URLCat {
static {
URL.setURLStreamHandlerFactory(new
FsUrlStreamHandlerFactory());
}
public static void main(String[] args) throws
Exception {
InputStream in = null;
try {
in = new URL(args[0]).openStream();
IOUtils.copyBytes(in, System.out, 4096, false);
} finally {
IOUtils.closeStream(in);
}
}
}
我们充分利用Hadoop提供的现成的IOUtils类用于在finally语句中关闭流,也能用于从输入流中复制字节并输出到指定的输出流中(示例中是System.out)。copyBytes最后面两个参数是字节数大小和当复制完成后是否关闭输入流。我们自己手工关闭输入流,System.out不需要关闭。
看一下示例的调用:
% export HADOOP_CLASSPATH=hadoop-examples.jar
% hadoop URLCat hdfs://localhost/user/tom/quangle.txt
On the top of the Crumpetty Tree
The Quangle Wangle sat,
But his face you could not see,
On account of his Beaver Hat.
使用FileSystem API读取数据
正如上一部分所讲的那样,有时我们不能够使用SetURLStreamHandlerFactory。这时候,我们就需要使用文件系统的API打开一个文件的输入流。
Hadoop文件系统中的文件由一个Hadoop路径对象表示(不是java.io.File对象,虽然它的语义与本地文件系统很接近)。你可以把一个路径想象成Hadoop文件系统URI,例如:hdfs://localhost/user/tom/quangle.txt。
FileSystem是常用的文件系统API。所以第一步获取一个FileSystem实例。本例中,需要获取操作HDFS的FileSystem实例。有几个静态方法可以获取FileSystem实例。
public static FileSystem get(Configuration conf) throws IOException
public static FileSystem get(URI uri, Configuration conf) throws IOException
public static FileSystem get(URI uri, Configuration conf, String user)
throws IOException
Configuration对象封装了客户端或服务器的配置。这些配置来自于classpath指定路径下的配置文件,例如:etc/hadoop/core-site.xml。第一个方法返回默认的filesystem对象(core-site指定的对象,如果没指定,则默认是本地的filesystem对象)。第二个方法使用给定的URI协议和权限决定使用的filesystem,如果URI中没有指定协议,则按照配置获取filesystem。第三个方法获取指定用户的filesystem,这对于上下文的安全性很重要。可以参看"安全"章节。
在某些情况下,你需要获取一个本地文件系统的实例对象,这时,你可以方便地使用getLocal()方法即可。
public static LocalFileSystem getLocal(Configuration conf) throws IOException
获得了filesystem实例对象后,我们可以使用open()方法获取一个文件的输入流。
public FSDataInputStream open(Path f) throws IOException
public abstract FSDataInputStream open(Path f, int bufferSize) throws IOException
第一个方法使用默认的buffer大小:4KB.
将以上方法合起来,我们可以重写示例3-1,见示例3-2:
示例:3-2
public class FileSystemCat {
public static void main(String[] args) throws Exception {
String uri = args[0];
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(URI.create(uri), conf);
InputStream in = null;
try {
in = fs.open(new Path(uri));
IOUtils.copyBytes(in, System.out, 4096, false);
} finally {
IOUtils.closeStream(in);
}
}
}
程序的运行结果如下:
% hadoop FileSystemCat hdfs://localhost/user/tom/quangle.txt
On the top of the Crumpetty Tree
The Quangle Wangle sat,
But his face you could not see,
On account of his Beaver Hat.
FSDataInputStream
FileSystem的open()方法实际返回了一个FSDataInputStream对象而不是标准的java.io.class对象。这个类继承了java.io.DataInputStream,支持随机访问,所以你可以从文件流任意部分读取。
package org.apache.hadoop.fs;
public class FSDataInputStream extends DataInputStream
implements Seekable, PositionedReadable {
// 实现部分省略
}
Seekable接口允许定位到文件中的某个位置并且提供了一个方法查询当前位置距离文件开始位置的位移。
public interface Seekable {
void seek(long pos) throws IOException;
long getPos() throws IOException;
}
如果调用seek()方法传入了一个比文件长度长的值,则会抛出IOException异常。Java.io.InputStream中方法skip()方法也可以传入一个位置,但这个位置必须在当前位置之后,而seek()能够移动到文件任意一个位置。
简单对示例3-2修改一下,见示例3-3.将文件中内容两次写入标准输出。在第一次写入后,跳回到文件起始位置,再写一次。
示例:3-3
public class FileSystemDoubleCat {
public static void main(String[] args) throws Exception {
String uri = args[0];
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(URI.create(uri), conf);
FSDataInputStream in = null;
try {
in = fs.open(new Path(uri));
IOUtils.copyBytes(in, System.out, 4096, false);
in.seek(0); // 返回到文件起始位置
IOUtils.copyBytes(in, System.out, 4096, false);
} finally {
IOUtils.closeStream(in);
}
}
}
本次运行结果如下:
% hadoop FileSystemDoubleCat hdfs://localhost/user/tom/quangle.txt
On the top of the Crumpetty Tree
The Quangle Wangle sat,
But his face you could not see,
On account of his Beaver Hat.
On the top of the Crumpetty Tree
The Quangle Wangle sat,
But his face you could not see,
On account of his Beaver Hat.
FSDataInputStream也实现了PositionedReadable接口,可以基于给定的位置,读取文件的一部分。
public interface PositionedReadable {
public int read(long position, byte[] buffer, int offset, int length)
throws IOException;
public void readFully(long position, byte[] buffer, int offset, int length)
throws IOException;
public void readFully(long position, byte[] buffer) throws IOException;
}
read()方法从给定的position位置处,读取length长度的字节放到给定的offset位移开始的buffer中。返回值是实际读取的字节数。调用者应该检查这个值,因为它也许比length小。
readFully()方法读取length长度的字节放入buffer中,对于是字节数组的buffer,读取buffer.length长度字节数到buffer中。如果到文件末尾,就中断操作,抛出一个EOFException异常。
所有这些方法都能保持文件当前位移的占有,是线程安全的。所以它们在读取文件内容的时候,还提供了一个获取文件文件元信息的方法。但FSDataInputStream设计时不是线程安全的,因此最好还是创建多个实例。
最后,记住调用sekk()方法是一个相当耗时的操作,所以应该尽量少调用。你应该将你的应用中访问文件的模式结构化,使用流数据的形式,例如使用MapReduce,而不是执行大量的seek。
写数据
FileSystem有许多创建文件的方法。最简单的方法是传入一个文件路径,返回文件输出流,然后向输出流中写入数据。
public FSDataOutputStream create(Path f) throws IOException
这个方法还有一些重载的方法,可以让你指定是否强制覆盖存在的文件,文件的复制参数(复制到几个节点),向文件写数据时buffer的大小,文件所用块的大小以及文件权限。
如果文件所在的父路径中目录不存在,create()方法将会创建它。虽然这很方便,但是这种形为也许是不希望发生的。你希望如果父目录不存在,就不写入数据,那么就应该在调用这个方法之前,先调用exists()方法检查一下父目录是否存在。另一种方法,你可以使用FileContext类,它可以让你控制父目录不存在时,创建还是不创建目录。
仍然有一个重载方法,接收一个回调接口,Progressable。实现此接口后,当数据写入数据节点时,你可以知道数据写入的进度。
package org.apache.hadoop.util;
public interface Progressable {
public void progress();
}
再介绍另外一个创建文件的方法,可以使用append()方法向已经存在的文件中添加内容。当然这个方法也有许多重载方法。
public FSDataOutputStream append(Path f) throws IOException
这个append操作允许一个writer操作一个已经存在的文件,打开并从文件末尾处开始写入数据。使用这个方法,那些能够生成没有大小限制的文件(例如日志文件)的应用可以在关闭文件后仍然能写入数据。append操作是可选的,并不是所有的hadoop文件系统都实现了它,例如HDFS实现了,而S3文件系统没有实现。
示例3-4显示了怎么样将本地的一个文件复制到Hadoop文件系统中。当Hadoop每次调用progress方法的时候,我们通过打印输出句号显示进度(当每一次有64KB数据写入数据节点通道后,hadoop就会调用progress方法)。注意这种特殊的行为并不是create()方法要求的,它仅仅是想让你知道有事情正在发生,这在下一个Hadoop版本中将有所改变。
public class FileCopyWithProgress {
public static void main(String[] args) throws Exception {
String localSrc = args[0];
String dst = args[1];
InputStream in = new BufferedInputStream(new FileInputStream(localSrc));
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(URI.create(dst), conf);
OutputStream out = fs.create(new Path(dst),
new Progressable() {
public void progress() {
System.out.print(".");
}
});
IOUtils.copyBytes(in, out, 4096, true);
}
}
调用示范:
% hadoop FileCopyWithProgress input/docs/1400-8.txt
hdfs://localhost/user/tom/1400-8.txt
.................
目前除了HDFS,没有其它Hadoop文件系统会在写数据的过程中调用progress()。进度在MapReduce应用中是重要的,你将在接下来的章节中还会看到。
FSDataOutputStream
FileSystem的create()方法返回一个FSDataOutputStream实例,和FSDataInputStream类似,它有一个查询文件当前位置的方法。
package org.apache.hadoop.fs;
public class FSDataOutputStream extends DataOutputStream implements Syncable {
public long getPos() throws IOException {
// implementation elided
}
// implementation elided
}
然而,和FSDataInputStream不一样的是,它不允许寻址(seeking)。因为HDFS仅仅允许连续地向打开的文件中写入内容或者向一个可写入内容的文件中追加内容。换句话说,不允许随意地要任意位置写入内容,只能在文件末尾写入。所以写入的时候寻址没有意义。
目录
FileSystem提供了一个创建目录的方法
public boolean mkdirs(Path f) throws IOException
这个方法会创建所有必要的父目录,如果它们不存在的话,就像java.io.File的mkdirs()方法一样。当目录(或所有的父目录)创建成功后,返回true。
一般,你不需要显式地创建一个目录,因为当调用create()方法创建一个文件时会自动地创建任何父目录。
文件系统查询
文件元数据:文件状态
任何文件系统都有一个重要的特性。那就是能够进行目录结构导航和获取它所存储的文件或目录的信息。FileStatus类封装了文件和目录的元信息,包括文件长度,块大小,复制参数,修改时间,所有者和权限信息。
FileSystem中的getFileStatus()方法提供了一个获取某个文件或目录状态的FileStatus对象的方法。示例3-5显示了它的使用方法。
public class ShowFileStatusTest {
private MiniDFSCluster cluster; // use an in-process HDFS cluster for testing
private FileSystem fs;
@Before
public void setUp() throws IOException {
Configuration conf = new Configuration();
if (System.getProperty("test.build.data") == null) {
System.setProperty("test.build.data", "/tmp");
}
cluster = new MiniDFSCluster.Builder(conf).build();
fs = cluster.getFileSystem();
OutputStream out = fs.create(new Path("/dir/file"));
out.write("content".getBytes("UTF-8"));
out.close();
}
@After
public void tearDown() throws IOException {
if (fs != null) { fs.close(); }
if (cluster != null) { cluster.shutdown(); }
}
@Test(expected = FileNotFoundException.class)
public void throwsFileNotFoundForNonExistentFile() throws IOException {
fs.getFileStatus(new Path("no-such-file"));
}
@Test
public void fileStatusForFile() throws IOException {
Path file = new Path("/dir/file");
FileStatus stat = fs.getFileStatus(file);
assertThat(stat.getPath().toUri().getPath(), is("/dir/file"));
assertThat(stat.isDirectory(), is(false));
assertThat(stat.getLen(), is(7L));
assertThat(stat.getModificationTime(),
is(lessThanOrEqualTo(System.currentTimeMillis())));
assertThat(stat.getReplication(), is((short) 1));
assertThat(stat.getBlockSize(), is(128 * 1024 * 1024L)); assertThat(stat.getOwner(),
is(System.getProperty("user.name")));
assertThat(stat.getGroup(), is("supergroup"));
assertThat(stat.getPermission().toString(), is("rw-r--r--"));
}
@Test
public void fileStatusForDirectory() throws IOException {
Path dir = new Path("/dir");
FileStatus stat = fs.getFileStatus(dir);
assertThat(stat.getPath().toUri().getPath(), is("/dir"));
assertThat(stat.isDirectory(), is(true));
assertThat(stat.getLen(), is(0L));
assertThat(stat.getModificationTime(),
is(lessThanOrEqualTo(System.currentTimeMillis())));
assertThat(stat.getReplication(), is((short) 0));
assertThat(stat.getBlockSize(), is(0L));
assertThat(stat.getOwner(), is(System.getProperty("user.name")));
assertThat(stat.getGroup(), is("supergroup"));
assertThat(stat.getPermission().toString(), is("rwxr-xr-x"));
}
}
如果文件或目录不存在,则会抛出一个FileNotFoundException。然而,如果你仅仅关注文件或目录是否存在,FileSystem的exists()方法会更方便。
public boolean exists(Path f) throws IOException
列举文件
查询单个文件或目录的信息是有用的,但你也经常需要列举目录下的内容,那就是FileSystem的listStatus()方法所做的:
public FileStatus[] listStatus(Path f) throws IOException
public FileStatus[] listStatus(Path f, PathFilter filter) throws IOException
public FileStatus[] listStatus(Path[] files) throws IOException
public FileStatus[] listStatus(Path[] files, PathFilter filter)
throws IOException
当参数是单个文件的时候,最简单变量的那个方法返回一个FileStatus对象数组,长度为1.当参数是一个目录的时候,返回零或多个FileStatus对象,代表该目录下的所有文件或目录。
重载的方法中,允许传入一个PathFileter对象,限制匹配的文件或目录。你将在“PathFilter”部分看到一个示例。最后,如果你传入一个路径数组,相当于对每个路径都调用listStatus()方法,然后将每个路径返回的FileStatus对象合并到一个数组中。这将非常有用,当Input文件夹中的文件来自文件系统中不同路径时。示例3-6就是这方面简单的应用示例。注意其中使用了Hadoop的FileUtil类中的stat2Paths()方法将FileStatus数组转换成Path对象数组。
示例:3-6 显示来自Hadoop文件系统中多个路径的文件状态使用示例
public class ListStatus {
public static void main(String[] args) throws Exception {
String uri = args[0];
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(URI.create(uri), conf);
Path[] paths = new Path[args.length];
for (int i = 0; i < paths.length; i++) {
paths[i] = new Path(args[i]);
}
FileStatus[] status = fs.listStatus(paths);
Path[] listedPaths = FileUtil.stat2Paths(status);
for (Path p : listedPaths) {
System.out.println(p);
}
}
}
运行结果如下:
% hadoop ListStatus hdfs://localhost/ hdfs://localhost/user/tom
hdfs://localhost/user
hdfs://localhost/user/tom/books
hdfs://localhost/user/tom/quangle.txt
文件模式
我们经常需要同时操作大量文件。例如,一个处理日志的MapReduce作业也许需要分析一个月的日志文件,这些文件存放在多个目录中。通常我们可以很方便地使用一个通配符表达式匹配多个文件,而不是遍历每一个目录下的每一个文件。Hadoop提供了两个使用通配符表达式的方法。
public FileStatus[] globStatus(Path pathPattern) throws IOException
public FileStatus[] globStatus(Path pathPattern, PathFilter filter)
throws IOException
globStatus()方法会返回符合通配符表达式的FileStatus对象数组,并按路径排序。可选的PathFileter参数能够进一步限制匹配的路径。
Hadoop支持与Unix Shell一样的通配符集合,见表3-2
| 通配符 | 名称 | 匹配项 |
|---|---|---|
| * | 星号 | 匹配零或多个字符 |
| ? | 问号 | 匹配单个字符 |
| [ab] | 字符集 | 匹配在集合{a,b}中的某个字符 |
| [^ab] | 排除字符集 | 匹配不在集合{a,b}中单个的字符 |
| [a-b] | 字符范围 | 匹配在范围[a,b]内的单个字符,a要小于或等于b |
| [^a-b] | 排除字符范围 | 匹配不在范围[a,b]内的单个字符,a要小于等于b |
| {a,b} | 二选一 | 匹配表达式a或b中一个 |
| \c | 转义字符 | 当c是特殊字符时,使用\c匹配c字符 |
假设日志文件按照日期以层级结构形式存储在目录下。例如:2007最后一天的日志文件存储在目录2007/12/31下。假设完整的文件列表如下:
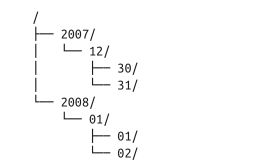
下面是一些文件通配符和它们的匹配结果:
| 通配符 | 匹配结果 |
|---|---|
| /* | /2007 /2008 |
| // | /2007/12 /2008/01 |
| //12/ | /2007/12/30 /2007/12/31 |
| /200? | /2007 /2008 |
| /200[78] | /2007 /2008 |
| /200[7-8] | /2007 /2008 |
| /200[^01234569] | /2007 /2008 |
| ///{31,01} | /2007/12/31 /2008/01/01 |
| ///3{0,1} | /2007/12/30 /2007/12/31 |
| /*/{12/31,01/01} | /2007/12/31 /2008/01/01 |
路径过滤(PathFilter)
通配符并不是总能够获取你想要的文件集合。例如,使用通配符不太可能排除某些特殊的文件。FileSystem的listStatus()和globStatus()方法都可以接受一个可选的PathFilter参数,允许通过编程控制能够匹配的文件。
package org.apache.hadoop.fs;
public interface PathFilter {
boolean accept(Path path);
}
PathFilter和java.io.FileFilter类对于Path对象的操作功能一样,而与File类不一样。示例3-7排除符合正则表达式的路径
示例:3-7
public class RegexExcludePathFilter implements PathFilter {
private final String regex;
public RegexExcludePathFilter(String regex) {
this.regex = regex;
}
public boolean accept(Path path) {
return !path.toString().matches(regex);
}
}
这个过滤器仅仅允许不符合正则表达式的文件通过。globStatus()方法接收一个初始化的文件集合后,使用filter过滤出符合条件的结果。
fs.globStatus(new Path("/2007/*/*"), new RegexExcludeFilter("^.*/2007/12/31$"))
将得到结果:/2007/12/30
过滤器仅仅作用于以路径表示的文件名,不能使用文件的属性例如创建时间作为过滤条件。然而,他们可以匹配通配符和正则表达式都不能够匹配的文件,例如如果你将文件存储在按照日期分类的目录下,你就可以使用PathFileter筛选出某个日期范围之间的文件。
删除数据
使用FileSystem的delete()方法可以永久地删除文件或目录。
public boolean delete(Path f, boolean recursive) throws IOException
如果f是一个文件或一个空目录,则recursive值被忽略。如果recursive值为true,则一个非空目录连同目录下的内容都会被删除,否则,抛出IOException异常。
由于本章节内容较多,达到了单页最大长度限制,本章其它内容将另起一篇书写,见Hadoop分布式文件系统(2)。
本文是笔者翻译自《OReilly.Hadoop.The.Definitive.Guide.4th.Edition》第一部分第3章,后续将继续翻译其它章节。虽尽力翻译,但奈何水平有限,错误再所难免,如果有问题,请不吝指出!希望本文对你有所帮助。