一、自定义分词器
这里我们自定义一个停用分词器,也就是在进行分词的时候将某些词过滤掉。
MyStopAnalyzer.java
package cn.itcast.util;
import java.io.Reader;
import java.util.Set;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.LetterTokenizer;
import org.apache.lucene.analysis.LowerCaseFilter;
import org.apache.lucene.analysis.StopAnalyzer;
import org.apache.lucene.analysis.StopFilter;
import org.apache.lucene.analysis.TokenStream;
import org.apache.lucene.util.Version;
public class MyStopAnalyzer extends Analyzer {
@SuppressWarnings("rawtypes")
private Set stops;//用于存放分词信息
public MyStopAnalyzer() {
stops = StopAnalyzer.ENGLISH_STOP_WORDS_SET;//默认停用的语汇信息
}
//这里可以将通过数组产生分词对象
public MyStopAnalyzer(String[] sws) {
//System.out.println(StopAnalyzer.ENGLISH_STOP_WORDS_SET);
stops = StopFilter.makeStopSet(Version.LUCENE_35, sws, true);//最后的参数表示忽略大小写
stops.addAll(StopAnalyzer.ENGLISH_STOP_WORDS_SET);
}
@Override
public TokenStream tokenStream(String fieldName, Reader reader) {
//注意:在分词过程中会有一个过滤器链,最开始的过滤器接收一个Tokenizer,而最后一个接收一个Reader流
//这里我们看到我们可以在过滤器StopFilter中接收LowerCaseFilter,而LowerCaseFilter接收一个Tokenizer
//当然如果要添加更多的过滤器还可以继续添加
return new StopFilter(Version.LUCENE_35, new LowerCaseFilter(Version.LUCENE_35,
new LetterTokenizer(Version.LUCENE_35, reader)), stops);
}
}
说明:
- 这里我们定义一个
Set集合用来存放分词信息,其中在无参构造器我们将默认停用分词器中停用的语汇单元赋给stops,这样我们就可以使用默认停用分词器中停用的语汇。而我们通过一个字符串数组将我们自己想要停用的词传递进来,同时stops不接受泛型,也就是说不能直接将字符串数组赋值给stops,而需要使用makeStopSet方法将需要停用的词转换为相应的语汇单元,然后再添加给stops进行存储。 - 自定义的分词器需要继承
Analyzer接口,实现tokenStream方法,此方法接收三个参数,第一个是版本,最后一个是停用的语汇单元,这里是stops,而第二个参数是别的分词器,因为分词过程中是一个分词器链。
测试:
TestAnalyzer.java
@Test
public void test04(){
//对中文分词不适用
Analyzer analyzer = new MyStopAnalyzer(new String[]{"I","you"});
Analyzer analyzer2 = new StopAnalyzer(Version.LUCENE_35);//停用分词器
String text = "how are you thank you I hate you";
System.out.println("************自定义分词器***************");
AnalyzerUtils.displayAllTokenInfo(text, analyzer);
System.out.println("************停用分词器***************");
AnalyzerUtils.displayAllTokenInfo(text, analyzer2);
}
说明:从测试结果中我们可以很容易看出自定义分词器和默认分词器之间的区别,自定义分词相比默认分词器多了我们自定义的词语。

二、中文分词器
这里我们使用MMSEG中文分词器,其分词信息使用的是搜狗词库。我们使用的是版本1.8.5.这个版本的包中有两个可用的jar包:
mmseg4j-all-1.8.5.jar
mmseg4j-all-1.8.5-with-dic.jar
其中第二个相比第一个多了相关的语汇信息,便于我们进行分词,当然我们可以使用第一个,但是这样便和默认分词器没有多大差别,我们在方法中直接测试:
@Test
public void test02(){
//对中文分词不适用
Analyzer analyzer1 = new StandardAnalyzer(Version.LUCENE_35);//标准分词器
Analyzer analyzer2 = new StopAnalyzer(Version.LUCENE_35);//停用分词器
Analyzer analyzer3 = new SimpleAnalyzer(Version.LUCENE_35);//简单分词器
Analyzer analyzer4 = new WhitespaceAnalyzer(Version.LUCENE_35);//空格分词器
Analyzer analyzer5 = new MMSegAnalyzer();
String text = "西安市雁塔区";
AnalyzerUtils.displayToken(text, analyzer1);
AnalyzerUtils.displayToken(text, analyzer2);
AnalyzerUtils.displayToken(text, analyzer3);
AnalyzerUtils.displayToken(text, analyzer4);
AnalyzerUtils.displayToken(text, analyzer5);
}
说明:此时我们直接使用MMSEG中文分词器,测试结果为:

我们看到和默认的分词器并无多大差别,当然我们也可以在方法中指定相关语汇信息存放的目录:
Analyzer analyzer5 = new MMSegAnalyzer(new File("E:/API/Lucene/mmseg/data"));
此时的测试结果为:

在目录
E:/API/Lucene/mmseg/data中存在四个文件:
chars.dic
units.dic
words.dic
words-my.dic
这写文件便存放了相关的语汇单元,当然如果我们想停用某些词,可以在最后一个文件中直接进行添加。
三、同义词索引(1)
3.1思路
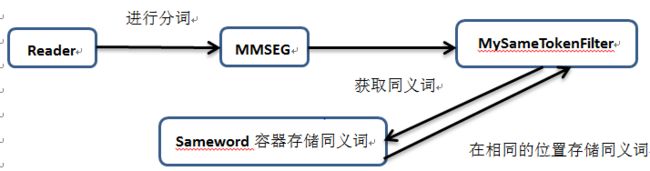
说明:首先我们需要使用
MMSEG进行分词,之后我们自定义的分词器从同义词容器中取得相关的同义词,然后将同义词存储在同一个位置,我们在之前讲过,就是同一个偏移量可以有多个语汇单元。
3.2 自定义分词器
MySameAnalyzer.java
package cn.itcast.util;
import java.io.Reader;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.TokenStream;
import com.chenlb.mmseg4j.Dictionary;
import com.chenlb.mmseg4j.MaxWordSeg;
import com.chenlb.mmseg4j.analysis.MMSegTokenizer;
public class MySameAnalyzer extends Analyzer {
@Override
public TokenStream tokenStream(String fieldName, Reader reader) {
Dictionary dic = Dictionary.getInstance("E:/API/Lucene/mmseg/data");
//我们首先使用MMSEG进行分词,将相关内容分成一个一个语汇单元
return new MySameTokenFilter(new MMSegTokenizer(new MaxWordSeg(dic), reader));
}
}
说明:和之前一样还是需要实现Analyzer接口。这里我们实例化Dictionary对象,此对象是单例的,用于保存相关的语汇信息。可以看到,首先是经过MMSEG分词器,将相关内容分成一个一个的语汇单元。
自定义同义词过滤器MySameTokenFilter.java
package cn.itcast.util;
import java.io.IOException;
import java.util.HashMap;
import java.util.Map;
import org.apache.lucene.analysis.TokenFilter;
import org.apache.lucene.analysis.TokenStream;
import org.apache.lucene.analysis.tokenattributes.CharTermAttribute;
public class MySameTokenFilter extends TokenFilter {
private CharTermAttribute cta = null;
protected MySameTokenFilter(TokenStream input) {
super(input);
cta = this.addAttribute(CharTermAttribute.class);
}
@Override
public boolean incrementToken() throws IOException {
if(!this.input.incrementToken()){//如果输入进来的内容中没有元素
return false;
}
//如果有,则需要进行相应的处理,进行同义词的判断处理
String[] sws = getSameWords(cta.toString());
if(sws != null){
//处理
for(String s : sws){
cta.setEmpty();
cta.append(s);
}
}
return true;
}
private String[] getSameWords(String name){
Map maps = new HashMap();
maps.put("中国", new String[]{"天朝", "大陆"});
maps.put("我", new String[]{"咱", "俺"});
return maps.get(name);
}
}
说明:这里我们需要定义一个CharTermAttribute 属性,在之前说过,这个类相当于在分词流中的一个标记。
相关方法AnalyzerUtils.java
public static void displayAllTokenInfo(String str, Analyzer analyzer){
try {
TokenStream stream = analyzer.tokenStream("content", new StringReader(str));
PositionIncrementAttribute pia = stream.addAttribute(PositionIncrementAttribute.class);
OffsetAttribute oa = stream.addAttribute(OffsetAttribute.class);
CharTermAttribute cta = stream.addAttribute(CharTermAttribute.class);
TypeAttribute ta = stream.addAttribute(TypeAttribute.class);
while (stream.incrementToken()) {
System.out.print("位置增量: " + pia.getPositionIncrement());//词与词之间的空格
System.out.print(",单词: " + cta + "[" + oa.startOffset() + "," + oa.endOffset() + "]");
System.out.print(",类型: " + ta.type()) ;
System.out.println();
}
} catch (IOException e) {
e.printStackTrace();
}
}
测试:
@Test
public void test05(){
//对中文分词不适用
Analyzer analyzer = new MySameAnalyzer();
String text = "我来自中国西安市雁塔区";
System.out.println("************自定义分词器***************");
AnalyzerUtils.displayAllTokenInfo(text, analyzer);
}
说明:整个执行流程就是:
- 1.首先实例化一个自定义的分词器
MySameAnalyzer,在此分词器中实例化一个MySameTokenFilter过滤器,而从过滤器中的参数中可以看到接收MMSEG分词器,而MySameTokenFilter的构造方法中接收一个分词流,然后将CharTermAttribute加入到此流中。 - 2.在
displayAllTokenInfo方法中我们调用incrementToken方法时先是调用getSameWords方法查看分词流中有没有同义词,如果没有则直接返回,否则进行相关的处理。 - 3.在这里的处理方式中,先是使用方法
setEmpty将原来的语汇单元清除,然后将此语汇单元同义词添加进去,但是这样就将原来的语汇单元删除了,这显然不符合要求。测试结果为:
 5
5
可以看到将“我”换成了“俺”,将“中国”换成了“大陆”。也就是说我们使用同义词将原来的词语替换掉了。
解决方法
我们之前说过,每个语汇单元都有一个位置,这个位置由PositionIncrTerm属性保存,如果两个语汇单元的位置相同,或者说距离为0,那么就表示是同义词了。而我们看到上面的测试结果中每个语汇单元的距离都为1,显然不是同义词。而对于上面例子中的问题,我们可以这样解决:
MySameTokenFilter.java
package cn.itcast.util;
import java.io.IOException;
import java.util.HashMap;
import java.util.Map;
import java.util.Stack;
import org.apache.lucene.analysis.TokenFilter;
import org.apache.lucene.analysis.TokenStream;
import org.apache.lucene.analysis.tokenattributes.CharTermAttribute;
import org.apache.lucene.analysis.tokenattributes.PositionIncrementAttribute;
import org.apache.lucene.util.AttributeSource;
public class MySameTokenFilter extends TokenFilter {
private CharTermAttribute cta = null;
private PositionIncrementAttribute pia = null;
private AttributeSource.State current ;
private Stack sames = null;
protected MySameTokenFilter(TokenStream input) {
super(input);
cta = this.addAttribute(CharTermAttribute.class);
pia = this.addAttribute(PositionIncrementAttribute.class);
sames = new Stack();
}
@Override
public boolean incrementToken() throws IOException {
while(sames.size() > 0){
//将元素出栈,并且获取这个同义词
String str = sames.pop();
restoreState(current);//还原到原来的状态
cta.setEmpty();
cta.append(str);
//设置位置为0
pia.setPositionIncrement(0);
return true;
}
if(!this.input.incrementToken()){//如果输入进来的内容中没有元素
return false;
}
if(getSameWords(cta.toString())){
//如果有同义词,捕获当前的状态
current = captureState();
}
return true;
}
private boolean getSameWords(String name){
Map maps = new HashMap();
maps.put("中国", new String[]{"天朝", "大陆"});
maps.put("我", new String[]{"咱", "俺"});
String[] sws = maps.get(name);
if(sws != null){
for(String s : sws){
sames.push(s);
}
return true;
}
return false;
}
}
说明:
- 1.首先我们添加了三个属性
PositionIncrementAttribute 、AttributeSource.State、Stack,分别是位置属性、当前状态、栈。其中栈用来保存同义词单元。在构造函数中初始化相关属性。 - 2.在调用
incrementToken方法开始时我们先使用方法incrementToken,让标记CharTermAttribute向后移动一个位置,同时将本位置(current)保留下来。而此时第一个语汇单元“我”已经写入到分词流中了,然后我们利用current在读取到同义词之后回到前一个位置进行添加同义词,其实就是将同义词的位置设置为0(同义词之间的位置为0),这样就将原始单元和同义词单元都写入到了分词流中了。这就将第一个单元的同义词设置好了,立即返回,进入到下一个语汇单元进行处理。 -
测试结果为:
 6
6
下面我们编写一个测试方法进行同义词查询操作:
@Test
public void test06() throws CorruptIndexException, LockObtainFailedException, IOException{
//对中文分词不适用
Analyzer analyzer = new MySameAnalyzer();
String text = "我来自中国西安市雁塔区";
Directory dir = new RAMDirectory();
IndexWriter write = new IndexWriter(dir, new IndexWriterConfig(Version.LUCENE_35, analyzer));
Document doc = new Document();
doc.add(new Field("content", text, Field.Store.YES, Field.Index.ANALYZED));
write.addDocument(doc);
write.close();
IndexSearcher searcher = new IndexSearcher(IndexReader.open(dir));
//TopDocs tds = searcher.search(new TermQuery(new Term("content", "中国")), 10);
TopDocs tds = searcher.search(new TermQuery(new Term("content", "大陆")), 10);
Document d = searcher.doc(tds.scoreDocs[0].doc);
System.out.println(d.get("content"));
System.out.println("************自定义分词器***************");
AnalyzerUtils.displayAllTokenInfo(text, analyzer);
}
说明:我们在查询的时候可以使用“中国”的同义词“大陆”进行查询。但是这种方式并不好,因为将将同义词等信息都写死了,不便于管理。
四、同义词索引(2)
(工程lucene_analyzer02)
这里我们专门创建一个类用来存放同义词:
SamewordContext.java
package cn.itcast.util;
public interface SamewordContext {
public String[] getSamewords(String name);
}
实现SimpleSamewordContext.java
package cn.itcast.util;
import java.util.HashMap;
import java.util.Map;
public class SimpleSamewordContext implements SamewordContext {
private Map maps = new HashMap();
public SimpleSamewordContext() {
maps.put("中国", new String[]{"天朝", "大陆"});
maps.put("我", new String[]{"咱", "俺"});
}
@Override
public String[] getSamewords(String name) {
return maps.get(name);
}
}
说明:这里我们只是简单的实现了接口,封装了一些同义词,之后我们在使用的时候便可以使用此类来获取同义词。测试我们需要改进相关的类:
MySameTokenFilter.java
package cn.itcast.util;
import java.io.IOException;
import java.util.HashMap;
import java.util.Map;
import java.util.Stack;
import org.apache.lucene.analysis.TokenFilter;
import org.apache.lucene.analysis.TokenStream;
import org.apache.lucene.analysis.tokenattributes.CharTermAttribute;
import org.apache.lucene.analysis.tokenattributes.PositionIncrementAttribute;
import org.apache.lucene.util.AttributeSource;
public class MySameTokenFilter extends TokenFilter {
private CharTermAttribute cta = null;
private PositionIncrementAttribute pia = null;
private AttributeSource.State current ;
private Stack sames = null;
private SamewordContext samewordContext ;//用来存储同义词
protected MySameTokenFilter(TokenStream input, SamewordContext samewordContext) {
super(input);
cta = this.addAttribute(CharTermAttribute.class);
pia = this.addAttribute(PositionIncrementAttribute.class);
sames = new Stack();
this.samewordContext = samewordContext;
}
@Override
public boolean incrementToken() throws IOException {
while(sames.size() > 0){
//将元素出栈,并且获取这个同义词
String str = sames.pop();
restoreState(current);//还原到原来的状态
cta.setEmpty();
cta.append(str);
//设置位置为0
pia.setPositionIncrement(0);
return true;
}
if(!this.input.incrementToken()){//如果输入进来的内容中没有元素
return false;
}
if(addSames(cta.toString())){
//如果有同义词,捕获当前的状态
current = captureState();
}
return true;
}
private boolean addSames(String name){
String[] sws = samewordContext.getSamewords(name);
if(sws != null){
for(String s : sws){
sames.push(s);
}
return true;
}
return false;
}
}
说明:在此类中我们太添加了一个属性SamewordContext,用来保存相关的同义词,在方法addSames中使用此类来获取相关的同义词。于是我们在后面使用MySameTokenFilter类的时候需要通过构造函数将此类传递进去。注意:这里需要面向接口编程,在后面我们需要想更换同义词存储类,只需要重现实现接口即可。