前言
索引的主要作用是起到约束和加速查找,ORM框架(sqlalchemy)是用类和对象对数据库进行操作
索引的种类
按种类去分
1.普通索引:能够加速查找
2.主键索引:能够加速查找、不能为空、不能重复
3.唯一索引:加速查找、可以为空、不能重复
4.联合索引(多列):
①联合主键索引
②联合唯一索引
③联合普通索引
按数据结构去分
1.hash索引:哈希索引。创建一个索引表,把这些数据(下面用到的'name')转化成哈希值,再把这些哈希值放入表中,并加上这个数据的存储地址。在索引表中的顺序和数据表中的数据不一定会一致,因为它里面的顺序是无序的,如果在数据表中按一个范围去找值那效能不一定会高,但是如果只找单值的时候它就会很快的查找出结果。
2.btree索引(常用):也就是binary tree索引、二元树索引。在innodb引擎中它创建btree索引。在范围内找值效率高。
索引的加速查找
首先创建一个表
create table dataset( id int not null auto_increment primary key, name varchar(32), data int, )engine = innodb default charset = utf8;
再创建一个存储过程,当我们执行的存储过程时往表里插入10w笔数据
delimiter // create procedure inserdatapro() begin declare i int default 1; -- 定义一个计数器i declare t_name varchar(16); -- 临时名字变量 declare t_data int; -- 临时数据变量 while i <= 100000 do -- 如果i小于10W就执行下面的操作 set t_name = CONCAT('aaa',i); -- 让'aaa'和i相连接变成字符串'aaa1','aaa2'...的形式 set t_data = CEIL(RAND()*100); -- 产生一个0-100的乱数 insert into dataset(name,data) values(t_name,t_data); -- 将t_name,t_data插入dataset内 set i = i + 1; -- 将i加一 end while; -- 结束循环 end // delimiter ;
执行存储过程,往表中插入数据完成要花一定的时间,具体还需要看电脑的性能
call inserdatapro();
比较两种语句的执行速度:
select * from dataset where name = 'aaa94021';
select * from dataset where id = 94021;
结果:
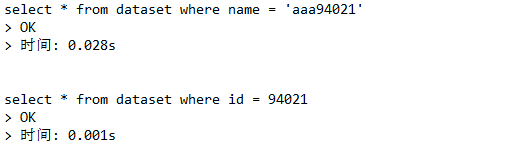
通过比较可以看出用索引(id)去查数据会比较快,像第一种查询方式因为没有索引,所以它必须要逐个去翻找出我们要的结果,因此我们可以再创建一个索引去查找数据。
create index nindex on dataset(name); -- 创建名字的索引
再去执行第一个查询语句:

可以看出效能得到了很显著的提升
查找方式:
1.无索引
从前到后依次查找
2.有索引
会创建一个数据结构或创建额外的文件,它按照某种格式去进行存储。所以它的查找方式会从这个索引文件中查询这个数据在这张表的什么位置。
查询快,但插入更行删除慢
当我们在使用索引查找资料时要命中索引,比如说:
select * from dataset where name like 'aaa94021';
索引相关操作:
1.普通索引
①创建表
create table t( nid int not null auto_increment primary key, name varchar(32), data int, index index_name(name) )
②创建索引
create index index_name on t(name);
③删除索引
drop index index_name on t;
④查看索引
show index from t;
2.唯一索引
①创建表
create table t2( id int not null auto_increment primary key, name varchar(32) not null, data int, unique index_name(name) )
②创建唯一索引
create unique index index_name on t2(name);
③删除唯一索引
drop unique index index_name on t2;
3.主键索引
①创建表
-- 写法一 create table t3( id int not null auto_increment primary key, name varchar(32) not null, int data, index index_name(name) ) -- 写法二 craete table t4( id int not null auto_increment, name varchar(32) not null, int data, primary key(id), index index_name(name) )
②创建主键
alter table t3 add primary key(id);
③删除主键
alter table t3 modify id int,drop primary key; alter table t3 drop primary key;
4.联合索引
①创建表
create table mtable( id int not null auto_increment, name varchar(32) not null, data int, primary key(id,name) )engine=innodb default charset=utf8;
②创建联合索引
create index index_id_name on mtable(id,name);