最近工作需要绘制ROC曲线,对该曲线的计算细节进行了一番摸索。当前搜索ROC曲线一般跟机器学习相关联,导致我对它的概念有了曲解,理所当然地以为它只是一个用于机器学习的分类器评估标准,所以在绘制曲线前使用逻辑回归(我的响应变量是0-1类型)对数据建模分析。实则不然,ROC曲线适用于任何判断0-1类型(真假、成功失败等二分类)响应结果阈值分割效果的评估。
关于ROC曲线的概念,可以参考ROC曲线与AUC值这篇博文学习和理解,如果你能看懂下面这条曲线,基本上你就理解了ROC存在的意义。
对于0,1两类分类问题,一些分类器得到的结果往往不是0,1这样的标签,如神经网络得到诸如0.5,0.8这样的分类结果。这时,我们人为取一个阈值,比如0.4,那么小于0.4的归为0类,大于等于0.4的归为1类,可以得到一个分类结果。同样,这个阈值我们可以取0.1或0.2等等。取不同的阈值,最后得到的分类情况也就不同。如下面这幅图:
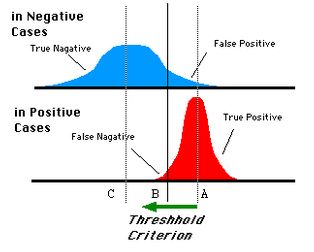
蓝色表示原始为负类分类得到的统计图,红色表示原始为正类得到的统计图。那么我们取一条直线,直线左边分为负类,直线右边分为正类,这条直线也就是我们所取的阈值。阈值不同,可以得到不同的结果,但是由分类器决定的统计图始终是不变的。这时候就需要一个独立于阈值,只与分类器有关的评价指标,来衡量特定分类器的好坏。还有在类不平衡的情况下,如正样本有90个,负样本有10个,直接把所有样本分类为正样本,得到识别率为90%,但这显然是没有意义的。如上就是ROC曲线的动机。
-- ROC曲线与AUC值
在R里面,有ROCR与专门的机器学习包mlr可以进行建模和绘制ROC曲线,以及相关参量的计算。实际上,不需要使用任何模型,也可以绘制ROC曲线,因为ROC曲线的绘制就是选择阈值与计算当前阈值下假阳性率与真阳性率变化的过程。
上述提到的两个包使用有些复杂,实际上我要用的也不是它们,关于ROC的计算,仔细思考写个程序就能搞定。核心是计算假阳性、真阳性率,首先要计算下方混淆矩阵中的各个参数。
calcROC <- function(.data, predict_var, target, group_var, positive="success"){
# predic_var here must be a numeric value
require(tidyverse)
predict_var <- enquo(predict_var)
target <- enquo(target)
group_var <- enquo(group_var)
groups <- .data %>% filter(!is.na(!! predict_var)) %>% select(!! group_var) %>%
unlist() %>% table() %>% names()
total_res <- list()
# process groups one by one
j <- 1
for (i in groups){
df <- list()
df <- .data %>% filter(!is.na(!! predict_var), !! group_var == i) %>%
arrange(desc(!! predict_var)) %>%
mutate(isPositive = ifelse(!! target == positive, 1, 0))
# select a threshold, calculate true positive and false positive value
ths <- df %>% select(!! predict_var) %>% unlist
mat <- base::sapply(ths, function(th){
# true positive
tp <- df %>% filter(!! predict_var >= th) %>% filter(isPositive == 1) %>% nrow
# false positive
fp <- df %>% filter(!! predict_var >= th) %>% filter(isPositive == 0) %>% nrow
# true negative
tn <- df %>% filter(!! predict_var < th) %>% filter(isPositive == 0) %>% nrow
# false negative
fn <- df %>% filter(!! predict_var < th) %>% filter(isPositive == 1) %>% nrow
# true positive rate
tpr <- tp / (tp + fn)
# false positive rate
fpr <- fp / (fp + tn)
return(c(tp, fp, tn, fn, tpr, fpr))
})
res <- t(mat)
res <- data.frame(res)
# fake a (0, 0) point
res <- rbind(c(rep(NA, 4), 0, 0), res)
colnames(res) <- c("tp", "fp", "tn", "fn", "tpr", "fpr")
res$Group <- i
total_res[[j]] <- res
j <- j + 1
}
dat <- base::Reduce(rbind, total_res)
return(dat)
}
上面函数的运行需要保证tidyverse包已经安装,写法遵从tidyverse语法,涉及不少管道操作,如果你只想使用,直接拷贝运行即可,如果想要理解过程,需要dplyr使用和编程(列举一篇笔记)的一些知识。
略微讲解一下使用:
> args(calcROC)
function (.data, predict_var, target, group_var, positive = "success")
函数有5个参数,第一个是包含数据的数据框;第二个是预测变量,一个数值向量;第三个是目标变量,包含0-1信息(成功或失败,等等);第四个是一个分组参数,一般我们会比较两组或多组ROC曲线的差异;第五个是给出成功(或1)是用什么指定的,比如目标变量中success指代成功。
结果会返回一个数据框:
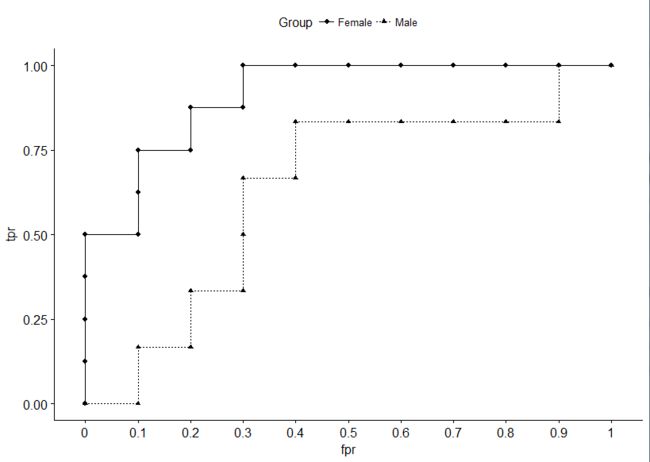
calcROC(dat, mut, isBenefit, Gender)
tp fp tn fn tpr fpr Group
1 NA NA NA NA 0.0000000 0.0 Female
TMB_NonsynSNP1 1 0 10 7 0.1250000 0.0 Female
TMB_NonsynSNP2 2 0 10 6 0.2500000 0.0 Female
TMB_NonsynSNP3 3 0 10 5 0.3750000 0.0 Female
TMB_NonsynSNP4 4 0 10 4 0.5000000 0.0 Female
TMB_NonsynSNP5 4 1 9 4 0.5000000 0.1 Female
TMB_NonsynSNP6 5 1 9 3 0.6250000 0.1 Female
TMB_NonsynSNP7 6 1 9 2 0.7500000 0.1 Female
TMB_NonsynSNP8 6 2 8 2 0.7500000 0.2 Female
TMB_NonsynSNP9 7 2 8 1 0.8750000 0.2 Female
TMB_NonsynSNP10 7 3 7 1 0.8750000 0.3 Female
TMB_NonsynSNP11 8 3 7 0 1.0000000 0.3 Female
TMB_NonsynSNP12 8 4 6 0 1.0000000 0.4 Female
TMB_NonsynSNP13 8 5 5 0 1.0000000 0.5 Female
TMB_NonsynSNP14 8 6 4 0 1.0000000 0.6 Female
TMB_NonsynSNP15 8 7 3 0 1.0000000 0.7 Female
TMB_NonsynSNP16 8 8 2 0 1.0000000 0.8 Female
TMB_NonsynSNP17 8 9 1 0 1.0000000 0.9 Female
TMB_NonsynSNP18 8 10 0 0 1.0000000 1.0 Female
11 NA NA NA NA 0.0000000 0.0 Male
TMB_NonsynSNP19 0 1 9 6 0.0000000 0.1 Male
TMB_NonsynSNP21 1 1 9 5 0.1666667 0.1 Male
TMB_NonsynSNP31 1 2 8 5 0.1666667 0.2 Male
TMB_NonsynSNP41 2 2 8 4 0.3333333 0.2 Male
TMB_NonsynSNP51 2 3 7 4 0.3333333 0.3 Male
TMB_NonsynSNP61 3 3 7 3 0.5000000 0.3 Male
TMB_NonsynSNP71 4 3 7 2 0.6666667 0.3 Male
TMB_NonsynSNP81 4 4 6 2 0.6666667 0.4 Male
TMB_NonsynSNP91 5 4 6 1 0.8333333 0.4 Male
TMB_NonsynSNP101 5 5 5 1 0.8333333 0.5 Male
TMB_NonsynSNP111 5 6 4 1 0.8333333 0.6 Male
TMB_NonsynSNP121 5 7 3 1 0.8333333 0.7 Male
TMB_NonsynSNP131 5 8 2 1 0.8333333 0.8 Male
TMB_NonsynSNP141 5 9 1 1 0.8333333 0.9 Male
TMB_NonsynSNP151 6 9 1 0 1.0000000 0.9 Male
TMB_NonsynSNP161 6 10 0 0 1.0000000 1.0 Male
注意函数调用时写法符合dplyr,相关参数可没有打引号,注意下~
左边第一列不用管,是一个无意义的行名,结果共有7列,而画图只需要最后的三列。每个组都有一行是伪造的,用于填充图像中的(0,0)点,也即阈值取无穷大时。
调用ggpubr包画图:
ggpubr::ggline(data = calcROC(dat, mut, isBenefit, Gender), x = "fpr", y = "tpr", linetype = "Group", shape = "Group")
如果想实际画出美丽的曲线,请参考新文章【r<-ROC|包】分析与可视化ROC——plotROC、pROC