不管是APP(Android)自动化测试,还是Web自动化测试,都是需要进行元素的获取的。所以这次要说的就是如何获取Web页面元素。
惯例介绍:
一、页面概况
其实上次我们一个简单的脚本是如下页面:
这其实就是百度的首页,在这张页面上有输入框、按钮和文字链接,还有一些图片、页面底部的文字,以及一些设置下拉框等。自动化要做的就是模拟鼠标和键盘来操作这些元素,或单击,或输入等。通过前端工具,可以看到页面上的元素都是由一行行代码组成的,它们之间有层级的组织起来,每个元素有不同的标签名和属性值。WebDriver就是通过这些信息找到不同的元素。
二、元素概况
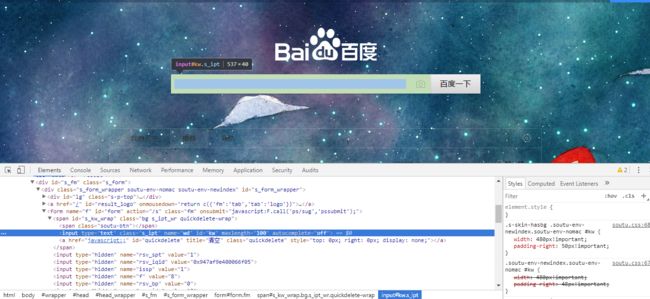
有两种方式查看页面元素:
(1)通过键盘"F12"按键可以调出来
(2)通过右击页面,选择菜单检查即可,方便定位出元素
如何获取?
一、综述
1、WebDriver提供了8种元素定位方法,在Python语言中,所对应方法如下:
1.1第一种对应方式
id —> find_element_by_id()
class name —> find_element_by_class_name()
link text —> find_element_by_link_text()
xpath —> find_element_by_xpath()
name —> find_element_by_name()
tag name —> find_element_by_tag_name()
partial link text —> find_element_by_partial_link_text()
css selector —> find_element_by_css_selector()
1.2第二种对应方式(By定位元素)
前提是需要导入相应的类:from selenium.webdriver.common.by import By
id —> find_element(By.ID,"")
class name —> find_element (By.CLASS_NAME,"")
link text —> find_element (By.LINK_TEXT,"")
xpath —> find_element (By.XPATH,"")
name —> find_element (By.NAME,"")
tag name —> find_element (By.TAG_NAME,"")
partial link text —> find_element_by (By.PARTIAL_LINK_TEXT,"")
css selector —> find_element_by (By.CSS_SELECTOR,"")
二、详解
百度首页的前端代码:
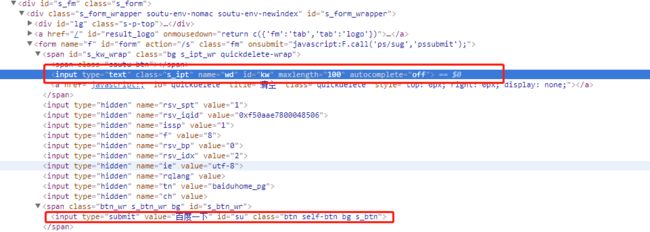
以输入框和“百度一下”为例:
1、id定位
find_element_by_id("kw")
find_element_by_id("su")
或者
find_element(By.ID,"kw")
find_element(By.ID,'"su")
2、name定位
find_element_by_name("wd")
或者
find_element(By.NAME,"wd")
3、class定位
find_element_by_class_name("s_ipt")
或者
find_element(By.CLASS_NAME,"s_ipt")
4、tag定位
find_element_by_tag_name("input")
或者
find_element(By.TAG_NAME,"input")
5、link定位
link定位与前面介绍的几种定位方法有所不同,它专门用来定位文本链接,例如:

find_element_by_link_text("新闻")
或者
find_element(By.LINK_TEXT,"新闻")
以上几个都可以使用此方式。
6、partial link定位
此定位方式和link定位类似,不过有些文本链接会比较长,这个时候就可以取文本的一部分定位,只要这一部分信息可以唯一的标示这个链接即可,例如:
find_element_by_partial_link_text("新闻大发现")
或者
find_element(By.PARTIAL_LINK_TEXT,"新闻大发现")
7、xpath定位
xpath定位方式比较多,是一种在XML文档中定位元素的语言。因为HTML可以看作XML的一种实现,所以Selenium可以使用这种强大的语言在Web应用中定位元素。
7.1绝对路径定位
参考百度首页前端代码,可以找到输入框:
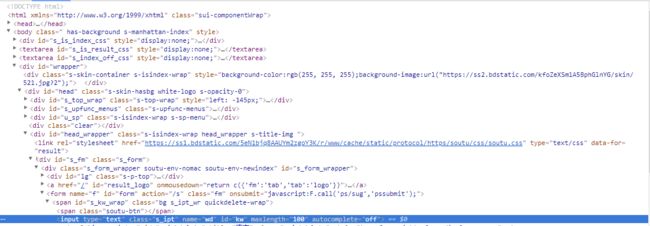
find_element_by_xpath("/html/body/div/div/div[5]/div/div/form/span/input")
或者
find_element (By.XPATH,"/html/body/div/div/div[5]/div/div/form/span/input")
7.2利用元素属性定位
这里就说一中简单的方式,百度首页右击检查定位到元素所在前端代码位置,然后右击选择"copy XPath":
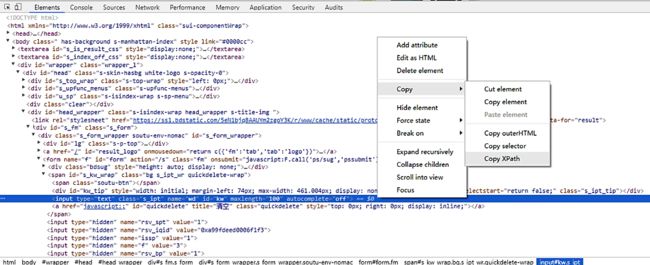
find_element_by_xpath("//*[@id="kw"]")
或者
find_element (By.XPATH,"//*[@id="kw"]")
xpath不限于所写方式,还有一些复杂定位方式(组合定位),遇到难以定位时可以使用。
8、CSS定位
CSS(Cascading Style Sheets)是一种语言,用来描述HTML和XML文档的表现。
8.1class定位
find_element_by_class_name(".s_ipt")
或者
find_element_by (By.CSS_SELECTOR,".s_ipt")
点号(.)表示通过class属性来定位元素。
8.2id定位
find_element_by_class_name("#kw")
或者
find_element_by (By.CSS_SELECTOR,"#kw")、
井号(#)表示通过id属性来定位元素。
CSS不限于所写方式,还有一些复杂定位方式(组合定位),遇到难以定位时可以使用。