第二十二节决策树系列之概念介绍(1)
本系列我们讲一个新算法及其衍生出来的系列算法,决策树,随机森林以及集成学习。无论是线性回归,逻辑回归,SVM,最大熵模型也好,都是w做参数,而我们的最终结果无论需要预测还是要分类,都是把x跟w互相搞一搞,然后得出一个结果。我们的y是通过x跟自己学的参数计算出来的,而决策树是通过一个树形的结构,来把我们的预测和分类问题完成。
决策树既能做预测也能做分类,它本质上最直观的是用来做分类,但是通过一点点的调整也可以用来做预测。决策树的起源非常早,所谓最早时期的人工智能就是指这。
比如拿下棋举例,第1节点表示对方走了一步棋,然后再走一步棋,走到2这个节点,当走到4这个节点的时候,有可能再走回1这个节点。每一个节点之间连线代表一个状态,这个状态也叫有限状态机,所谓的有限状态机就是指就有若干的状态,每个状态之间可以互相转换。

比如说对方第一步走的是第一种状态,你就做出一个决策,对方第二步走到另外一个状态,你就跳到另一个决策,在早期的游戏AI里面通常都是用这种方式来做。它背后都是一个有限状态机,看到你做了什么情况,就跑到某一个状态去执行一个决策,发现你又变成另一个状态,它有可能跳回原来那个状态去执行之前的决策,所以它是根据不同的形式评估,然后在不同的状态之间跳转,有不同的策略执行。每一个状态其实都有可能是一个子函数,背后取做一系列的操作。当有限状态机设计的特别复杂的时候,一定程度上它就具备一定的智能。
所以那个时代里所谓的人工智能就是发现对方往前走了,下一步应该做什么?背后其是一系列特别复杂的策略写的程序存到计算机里面,就相当于在编写这个程序的时候,你替计算机想到了所有一切可能发生的情况,告诉它遇到什么情况就干什么,所以看起来像是在模仿人类做决策的过程,其实背后就是一堆的if else。
所以人工智能里面有一句笑话叫有多少人工就有多少智能,在那个时代说的确实对,人想到了多少事,计算机只是帮你记下来,遇到这个情况的时候,去执行这个程序,这个就叫显示编程。
而机器学习推翻了那种思路,它想通过不需要你显示编程的方式,让计算机从数据集中通过某些合理的算法,自己大量计算后,得到一些信息。
简单来说,人工智能主要解决两个问题,一是决策问题,就是所有数据给你之后,你应该做什么?大部分数据挖掘就是做这件事情,帮人们做一些决策。二是识别问题,把自然界中没有整理好的数据及丢给计算机,让它能认识这个东西是什么,比如图像识别,语音识别,比如自然语音处理。
决策和识别哪个更复杂一点?识别,让计算机理解人才能理解的东西更复杂。它的几个分支,一个是CV计算机视觉,一个是NLP自然语言处理,比如我们积累了大量的数据在移动互联网里,那么这些数据是未经处理的,怎么样从中提取信息,基本上是自然语言处理要做的事。
但是各个分支不会是自己独立的一部分,做决策也需要这些支撑。比如阿里天气竞赛有一个健康绿色的比赛,它里面要根据几万个人的体检报告给参赛者,去评估人的血压血脂各种指标。那里面很多数据的维度并不是整理好的数据,而是x1到xn是一组数,很多给你的原始数据是医生写的评语。那么在做数据预处理的时候,也需要用一些简单的自然语言处理模型来把它先转换成计算机可以认识的语言。
回到决策树身上,其实决策树本身作为一个树形结构其实就是一堆if else。
现在决策树也应用在了有监督机器学习模型上。
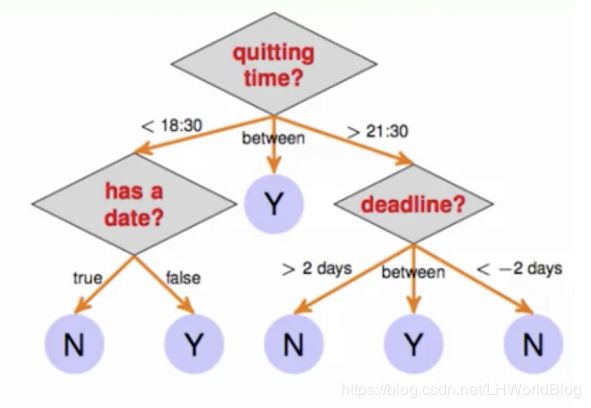
举个例子,比如quitting time是下班时间,你要做一个决策,今天到底晚上要不要学习?假如下班时间早于6点半,你会看今天要不要和女朋友去约个会;如果今天没有约会,回家也没有什么事情做,有可能就学习(Y)了;如果今天天气好,出去玩,肯定就会导致不学习(N);假如9点半之后才下班,回家已经非常累了,你看跳槽的面试时间(deadline)还有两天以上,今天就休息,不学习了(N);或者面试已经过去两天了,心情已经平复下来,暂时也不学习(N)了;明天就要面试了,就可能学习(Y)。
这就是一个简单的决策树的形式,上面的图就是一棵树,我们称这棵树quitting time这个节点叫做根节点,下面真正要去做决策的节点叫做叶子节点。
现在这棵已经做好给你了,怎么做预测?来一条数据第一个维度记录着今天这个人下班的时间,第二个维度是有没有约会,第三个维度是deadline截止日期还有多少?有了这三个数据,只要扔到这个树里边,它在每一个叶子结点要分裂的时候去读取相应的数据判断一下到底分到哪枝了,然后再读取数据来判断一下最后的结果。
树在生长的过程中可不可能出现两个同样维度?比如have a date分裂条件是true的情况下会接着再出现quitting time吗?在这个例子里面貌似是不会出现的,在实际的例子中这样是没问题的,只不过赋予它的意义有点矛盾了,但对某些数据的具体实际含义来说,也有可能出现多次的。