英文第二版(i1d6) 无奈中文的电子版画质太渣,顺便复习一下英语吧.
***2016.12.19 *** 多读书,多实践,程序员是靠思想和代码喂出来的.
- 2007年 cuda发布,之前都是gpgpu接口进行并行计算
How does the hardware works?
nvidia gpu
硬件架构
这篇文章写的很不错,介绍软硬件原理.
- sp(streaming processor)
显卡的最基本的指令执行单元,也被称为CUDA core - sm(streaming multiprocessor)类似于一个cpu核,多个sp共享一个sm内的资源,active warps被sm资源限制.
- 多个sp
- Shared Memory/L1Cache
- Register File
- Load/Store Units
- Special Function Units
- Warp Scheduler

软件架构
- thread
- block
数个threads会被群组成一个block,同一个block必须在同一个sm中运行,同一个block中的threads可以同步,也可以通过shared memory通信。 - grid
- warp
GPU执行程序时的调度单位,目前cuda的warp的大小为32,同在一个warp的线程,以不同数据资源执行相同的指令.warp通常被硬件的SIMD模块执行.
对应关系
一个SP可以执行一个thread,但是实际上并不是所有的thread能够在同一时刻执行。Nvidia把32个threads组成一个warp,warp是thread调度和运行的基本单元。warp中所有threads并行的执行相同的指令。一个warp需要占用一个SM运行,多个warps需要轮流进入SM。由SM的硬件warp scheduler负责调度。目前每个warp包含32个threads。所以,一个GPU上resident thread最多只有 SM*warp个。
- bank conflict
DMA
传统的数据拷贝方式,通过DMA在cpu执行的指令的同时,和设备进行数据交换.
GPU基本处理单元
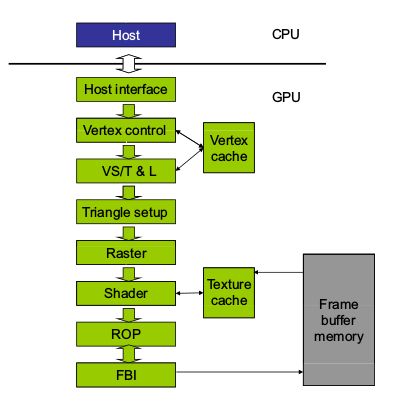
- 着色器完成渲染之后,数据存储在GPU内部的Frame buffer momory中,cpu端通过接口将这部分数据写入到显示器的frame buffer中,这就要求二者的带宽足够高.着色器到frame buffer的带宽足够高,另一个显示的frame buffer 到Frame buffer 有多个通道连接Frame buffer的多个memory bank,这样二者的带宽将大幅提升.这奠定了早期的GPU模型架构.
the vertex shader and the pixel shader 是GPU处理的基本部件.前者负责读入三角顶点的位置,并计算输出新的三角顶点的x\y\z坐标.后者每一个着色器处理每一个像素的对应位置的RGB颜色.这两者的可编程和数据无关的可并行奠定了GPU并行处理的基础.

可编程的接口要比固定接口的性能稍逊色,但是二者的合理配合可以发挥GPU的最大性能.
warp
NVIDIA通常32个线程作为一个warp,当一个block中有众多的warp等待执行的时候,硬件将挑选出最快被执行完毕的warp有限执行,而有长延迟的warp(例如访问global内存,分支判断,浮点计算)将在其长延迟的操作完毕之后,进入准备状态的时候才会等待调度运行,我们可以认为这种warp调度机制是零延迟的.这样就可以最大限度的让sm中的sp满负荷运行,不会将时间浪费在等待上.
- 每个在sm足够多的时候block数要和sm数相匹配,但是每个sm上激活的thread要满足最小值.
同一个block中的warp数足够多的时候(thread足够多)可以大大隐藏一些长延迟操作的时间代价. - 当block中不够warp数的时候,会追加一些不会被执行的thread到最后一个warp中
访存
在大多数情况下计算的速度并不是GPU上最耗时的地方,瓶颈主要在于访问device上的global内存的带宽和并发访问.
- global memory/share memory/register
- 通过线程合作,先将频繁访存的数据段load到share Memory中,然后再从share Memory中load数据可以大大降低访存延迟.
- 但是每个thread占用的资源越多,每个sm中存在的thread就越少.


一维的线程直接按照顺序依次组成一个warp去执行
二维或三维的线程格将按照较小的一维去线性展开,三维的先展开成一个二维的,然后按照上图的方式将线程展开拼接成warp去执行.这样就应该考虑多维线程访问数据和程序组织的方式.
*** EG***:
2 x 8 x 4 (four in the x dimension, eight in the y dimension, and two in the z dimension), the 64 threads will be parti-tioned into two warps, with T 0,0,0 through T 0,7,3 in the first warp and T 1,0,0 through T 1,7,3 in the second warp.
当warp中有分之跳转的时候,simd模块将先做一部分分之(如 if),再做另一部分分之(else)二者串行执行,不会相互干扰,这无疑将增加kernel的执行时间,在程序中应该尽可能减少分支预测.
reduction


global内存效率
Global Memory 通常是由DRAM构成,在同一个warp内的线程如果连续访问同一块区域的DRAM内存,可以将这些访存命令合并成一次访存命令,让带宽接近峰值.

以矩阵乘法为例,图a每一个线程遍历一行,b每一个线程遍历一列,从这两种方式来看,b可以形成内存合并访问,因为连续的线程号访问连续的内存空间(如下图).
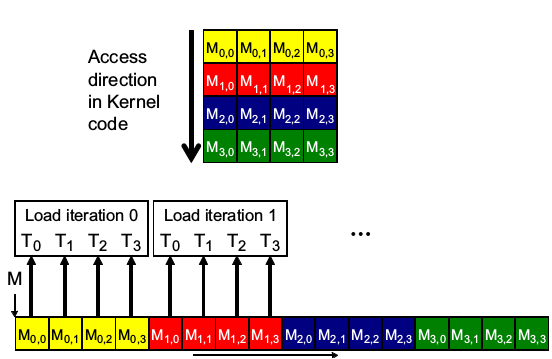
若在算法上必须每一个线程处理一行,可以用共享内存的方式提高访存效率.首先通过线程合作将数据load到共享内存中,然后再从共享内存中获取数据.
sm资源分配
- 每个sm中 thread slots /block slots/ register 都是有限的

- 复用寄存器,减少访存,提高内存带宽
grid,block,thread
- 关于三者配置关系请移步这里,这篇文章写的还是挺不错的.
dim3 grid,block; <<
grid里面限制每一维有多少个block,而block里面限制每个block里面的每一维有多少个thread.
常量内存
- cache coherence issue
- 常量内存的申请方式类似于c中的全局变量,无需用参数传入
- *** 常量内存在程序运行过程中不会被修改,硬件会积极缓存这部分内存到cache中 ***
- 在多核上保证cache一致性是很难的,而常量内存在运行过程中不会引发缓存不一致的问题,常能内存因此能够在众核架构中轻松的实现缓存机制.
- 在同一个warp的线程会以极大的带宽访问常量内存.
卷积操作例子
- 主要研究共享内存和常量内存的使用
[todo] 16
[todo] 41
[todo] 125
[todo] 179
[todo] 185
软硬件映射
这篇文章讲解的还是不错的.
看了几天书,概念还是比较混乱的,整理一下.
软件层面:
- grid,block,thread
软件抽象,所有的thread都是并发同时执行的.
硬件层面:
- sm,gpc(处理核集群),sp,share memory,register
再看这图,这是一个sm,含有4个gpc,一块share memory.每个gpc里面含有1个Warp Scheduler,16384x32bit的register资源.该sm共有128个cuda core.
- 同一个grid的不同block会被发射到不同的sm上执行.
- 同一个sm上会有来自不同kernel的block执行.
- 每个thread的局部变量存储在register中.
- register和share memory的数量限制该sm上可以同时存在的block数.
- block里面的thread会按照warp划分,分组到cuda core中执行,这里gpc中有32个core正好warp也是32,这样一个warp到一个gpc中的32个core中执行.
warp调度
- cuda通过warp的切换掩盖掉寄存器的访存延迟,为了掩盖延迟,至少需要24个warp轮流执行(当某一个warp访存的时候,其余23个warp轮流执行),那么则需要768个thread来掩盖这种延迟.保持充分的Occupancy,让硬件足够忙碌,则可以掩盖访存延迟,达到性能最佳的状态.
每个sm上最多的block数:
寄存器的个数是按照block分配的,例如每个block含有128个线程,每个线程占用10个寄存器,那么该block要占用1280个寄存器,sm上激活的block数取决于能够分配几个block的寄存器.
block thread数量抉择:
一般来说,block数量应该大于sm数量,这样保证每个sm上都有block运行.block 中的thread 数也应该越大越好,但是,要考虑该sm上最多的线程数,要让sm100%占用,thread数量*block数量应该是sm最大的thread数的整数倍.到达50%的占用率之后,提高占用率不会提高性能,相反低占用率可以使thread使用更多的register 降低访存延迟.这里有关于低thread数量的优点测试
基本法则:
- Threads per block should be a multiple of warp size to avoid wasting computation on under-populated warps and to facilitate coalescing.
- A minimum of 64 threads per block should be used, and only if there are multiple concurrent blocks per multiprocessor.
- Between 128 and 256 threads per block is a better choice and a good initial range for experimentation with different block sizes.
Use several (3 to 4) smaller thread blocks rather than one large thread block per multiprocessor if latency affects performance. This is particularly beneficial to kernels that frequently call __syncthreads()
.