本文介绍图的几种基本操作:BFS,DFS,求有向图连通分量的Tarjan算法以及拓扑排序。
图的表示
一张图是由若干顶点和顶点之间的边组成的,可以形式化为G(V, E),V代表顶点集合,E代表边集,本文中为了书写方便,定义顶点数|V|=n,边数|E|=m。根据边是否有方向,可以分为有向图和无向图,本文讨论的内容都是有向图。下面是一个无向图的示例。

在编码中,图的存储方式常见的有两种:邻接表和邻解矩阵,在C++中的写法是:
// adjacency matrix
const int MAXV = 1e5;
int G1[MAXV][MAXV];
//adjacency lists
struct Edge1 {
int dst, dis;
};
std::vector > G2;
这两种存储方法对应的基本操作时间复杂度如下:
| 空间复杂度 | 查看u,v之间边的权值 | 遍历所有的边 | |
|---|---|---|---|
| 邻接表 | O(m+n) | O(degree(u)) | O(m + n) |
| 邻接矩阵 | O(n^2) | O(1) | O(n^2) |
一般来说,邻接表的方式使用的多一些,因为稠密图并不是很常见,在图的遍历上邻接表有优势。但也有特定场景邻接矩阵会更方便,如Floyd算法的实现。
图的遍历(BFS & DFS)
图算法中最基础的就是图的遍历了,基本方法有两种:广度优先搜索(BFS)和深度优先搜索(DFS)。为了方便描述,我们定义图上从顶点i到顶点j的一条简单路径为一系列的点i, k1, k2, ..., j,其中没有重复出现的顶点,连续出现的点之间有边相连,路径上点的个数减1代表路径的长度。
BFS的大致思想就是先遍历和起点最短路径长度为0的点(起点本身),再遍历长度为1的点(从起点出发1步可达的点),再遍历长度为2的点....直到所有点都被访问过。时间复杂度O(m+n),下图是一个更形式化的描述:
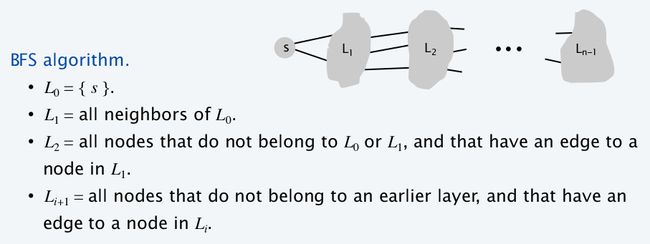
在C++中,BFS常配合队列(queue)这一数据结构实现:
std::vector > g;
bool vis[MAXV];
// implementation of breath-first search
std::vector bfs(int s) {
std::vector seq;
std::queue q;
memset(vis, 0, sizeof(vis)); // initialize data
q.push(s); vis[s] = true; // insert starting node into queue
while(!q.empty()) {
int hd = q.front();
q.pop();
seq.push_back(hd);
for(int i = 0; i < g[hd].size(); i++) {
int next = g[hd][i];
if(vis[next]) continue;
q.push(next); vis[next] = true;
}
}
return seq;
}
DFS的大致思想是从当前点出发,沿着一条简单路径走到没有点可以访问,再回溯到之前访问过的节点,沿着另一条简单路径走下去。直到所有点都被访问一遍,时间复杂度同样是O(m+n)。DFS通常通过递归实现。
std::vector > g;
std::vector seq; // store the visiting order
bool vis[MAXV];
// implementation of depth-first search
void dfs(int s) {
if(vis[s]) return;
seq.push_back(s); vis[s] = true;
for(int i = 0; i < g[s].size(); i++)
dfs(g[s][i]);
}
回顾BFS/DFS的搜索过程,除了起点,每个点都是通过父节点指向它的一条边被引入的,如果把这个过程建图,那么这个图中一共有n个节点和n-1条边,且整个图是连通的(假设图中的边是无向的),满足这两条性质的无向图称之为树,通过BFS/DFS得到的树被称为搜索树。
最后补充一点,在状态数很多的搜索问题中,BFS被认为是完备的,即解如果存在,一定可以搜到,DFS则不是,可能需要和迭代加深这些策略配合。
Tarjan算法
在一次BFS或DFS中,我们其实并不能保证一定访问到图中的所有节点,因为有些图可能是不连通的。我们把从一个点出发,所有可达点的集合称为这个点所在的连通分量。给定一个无向图,我们找所有连通分量的方法叫做灌水法(Flood Fill),其实就是对当前未访问过的点做BFS/DFS,直到所有的点都被访问过1次。
Tarjan算法是为了解决有向图中类似的问题提出的。只不过有向图中我们可以定义强连通分量,有向图中一个强连通分量中的任意两个点u,v都是强连通的,即存在从u到v的路径,也存在从v到u的路径。

很明显,Flood Fill并不能用来求强连通分量。但只使用BFS/DFS,我们可以给出一个求给定点所在强连通分量的方法:1) 从该点出发做一次BFS/DFS;2) 把所有边反向,再从这个点做一次BFS/DFS;3) 把两次搜索访问的顶点集合做一次交,就可以得到该点所在的极大强连通分量。如果用这种方法求所有强连通分量的话,需要对每个点做两次BFS/DFS,时间复杂度为O(n^2)。更好的方法是Kosaraju算法或Tarjan算法,这里只介绍Tarjan。
Tarjan算法中,图中每个节点维护两个属性:
- dfu(i):节点i在DFS中第dfu(i)个被访问到(时间戳);
- low(i):DFS搜索树中,以节点i为根节点的子树中的节点集合记为T(i)。T(i)中的点在原图中所指向的点的集合记为S(i)。S(i)中最小的时间戳就是low(i),low(i)可以用下面的递归式表示:
low(i) = min(dfn(i), dfn(j), low(j)) (j为i的子节点)
Tarjan算法的描述如下:
- 初始化一个空的栈和一个每访问一个节点加1的计时器
- 对图做DFS,每次访问新的顶点时,设定dfn(i)为当前时间,把该节点压栈,接着求low(i):对于还没被访问的后继节点j,递归访问j,
low(i) = min(dfn(i), low(j)),对于已经访问过的后继节点k,low(i) = min(low(i), dfn(j))。如果最终得到的low(i) = dfn(i),就把栈中当前节点以上的节点全部弹出,这些节点就是一个极大强连通分量
Tarjan算法只需要做一遍DFS,所以一定会终止,时间复杂度O(m+n)。
C++实现:
void tarjan(int u) {
dfn[u] = low[u] = ++cnt;
st[++top] = u;
instack[u] = true;
for(Edge *p = e[u]; p; p = p->next) {
int v = p->dst;
if(!dfn[v]) {
tarjan(v);
low[u] = std::min(low[u], low[v]);
}
else if(instack[v])
low[u] = std::min(low[u], dfn[v]);
}
if(dfn[u] == low[u]) {
cluster++;
int hd;
do {
hd = st[top--];
instack[hd] = false;
belong[hd] = cluster;
}
while(hd != u);
}
}
(PS:一道经典的求强连通分量的题 Networks of School
拓扑排序
在图论中,我们经常讨论有向无环图DAG(Directed Acyclic Graph),这类图常用来描述节点之间的依赖关系(先修课程、软件包的安装依赖)。对于DAG,我们可以对其进行拓扑排序。
一个DAG的拓扑排序是图中所有顶点的一个排列:v1, v2, ..., vn,对于原图中每条边(vi, vj)都有i < j。下图就展示了一个拓扑排序的例子:

拓扑排序可以通过一个很直观的策略求得:选取当前所有入度为0的点,把它们加入拓扑序列中,再把这些点的出边删去,反复这两个操作,直到所有的点都加入拓扑序列中。对应的C++实现如下:
std::vector topsort(const std::vector > &g) {
int n = g.size();
std::vector d(n);
for(int i = 0; i < n; i++)
for(int j = 0; j < g[i].size(); j++)
d[g[i][j]]++;
std::queue q;
std::vector seq;
for(int i = 0; i < n; i++)
if(!d[i]) q.push(i);
while(!q.empty()) {
int hd = q.front();
q.pop();
seq.push_back(hd);
for(int i = 0; i < g[hd].size(); i++) {
int dst = g[hd][i];
d[dst]--;
if(!d[dst]) q.push(dst);
}
}
return seq;
}
正确性证明:
结论1:算法一定会终结。队列中最多会压入n个顶点,每次循环都会取出第一个元素,因此最多循环n次,同时,每次循环内会访问当前队列第一个点的所有出边,这个点不会再加入队列,因此每条边最多被访问一次,算法总的复杂度O(m+n)。
结论2:对于连通的DAG,算法一定会返回一个长度为n的序列。如果当前序列长度不足n,说明连通图中还有点没有被加入序列,而此时如果队列为空,则说明没有入度为0的点了,这在无环图是不可能的。这同时提醒我们,对于没有保证连通性的图,需要多次的拓扑排序已确保每个连通分量中的点都加入了序列。同时,如果考虑所有连通分量后,最终返回序列的长度小于n,那么说明原图中有环。
结论3:对于返回的序列v1, v2, ..., vn,原图中不存在边(vi, vj)使得i > j。假如有这样一条边从vi指向vj,且在拓扑序列中vj在vi之前。算法中vj在被删除时,vi还没被删除,因此vj的入度不会为0,矛盾!
(PS:一道不错的拓扑排序的题 All Discs Considered
附
本文图片来自 Lecture Slides for Alogorithm Design by Jon Kleinberg and Éva Tardos.