写在前头:限于个人对nagios的了解有限,写得不够深入与系统,甚至可能会有些错误,各位看官还多包涵。本文主要涉及的是nagios daemon、nrpe及三个部分。
1. nagios系统的功能
主机或服务状态监控
nagios是一款开源的监控软件,从它可以监控的设备类型上来看,主要包含网络设备,服务器设备。常见的网络设备如:路由器、交换机、防火墙、F5、打印机等,常见的服务器设备主要分为:UNIX类、Linux类以及Windows类。按我的理解凡是支持snmp协议的设备,包含PC都可以通过nagios进行监控。当然,nagios实现对主机资源及服务的监控并非全依靠snmp协议,它最为主要的监控手段是通过nrpe组件来实现。监控告警通知
nagios对在网络中发现的问题会及时产生告警信息并通过事先定义好的方式,如邮件、短信、微信等方式通知相关人员。随着网络运维工作更加自动化,还可以通过nagios支持的相应API接口,开发相应的程序,实现其自动或人干干预去对监控发现的问题进行自动化的处理。监控信息可视化
nagios结合web服务器,可以将整个网络所监控的所有信息以web页面的形式展现出来,还可以结合外部软件实现监控数据可视化,以图表的形式展示在web页面中,本文将介绍nagios常用的画图软件包pnp,现在叫pnp4nagios。
- 监控数据存储
nagios监控到的数据会存储下来,可以直接以文件的形式存储也可以通过NDOUtils组件存储到如mysql类的数据库中,从而可以很好支持监控历史数据的查询。
2.nagios系统的组成
nagios系统主要包含nagios daemon、nagios plugin、nrpe、web三个组件,它还包含NDOUtils、NSCA、NSClinet++组件,它们共同组成一个完整的nagios,组成逻辑图如下所示:

Nagios Daemon
nagios系统的核心组件,它负责组织与管理各组件,将它们协调起来共同完成监控任务,并完成监控信息的组织与展示。Nagios Plugins
nagios plugins主要就是nagios核心组件自带以及用户自开发的一些插件,它们是实现各项监控的具体小程序,由它们将采集到相应的数据以后,回送给nagios服务器。NRPE
nagios系统要想取得被监控主机的存活状态、http、ftp、ssh服务是否可用,可以通过程序探测的出来,但如果要想取得被监控端上如磁盘容量,cpu负载这类本地信息时,如果没有相应的权限就不行,所以就产生了代理程序,事先在被监控机上安装代理程序(Linux系统是nrpe软件),然后通过它们来获取监控数据,再回送给nagios服务器。当nrpe启动以后,它会开启5666端口。nrpe的工程原理如下图所示:
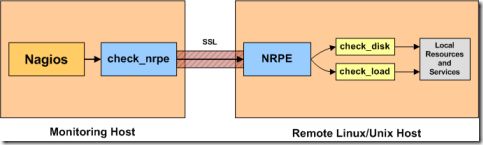
NRPE 总共由两部分组成:
check_nrpe:位于nagios server上。
NRPE daemon:位于被监控的Linux主机上。
当Nagios 需要监控某个远程Linux 主机时:
nagios 会运行check_nrpe 这个插件,告诉它要检查什么
check_nrpe 插件会连接到远程的NRPE daemon,所用的方式是SSL; NRPE daemon 会运行相应的nagios 插件来执行检查;
NRPE daemon 将检查的结果返回给check_nrpe 插件,插件将其递交给nagios做处理。
NSClinet++
NSClient++这一组件是安装在windows主机上,相当于nagios server在windows端的代理程序。NSCA
NSAC这一组件适用于部署分布式nagios监控系统时使用,它可以实现让被监控端主动将需要监控的信息发送给nagios服务端。
3.本文所用到系统环境
OS:CentOS release 6.8 (Final) 2.6.32-642.el6.x86_64
还有一个重要环境:互联网(yum、百度、Google)。
各软件包:
| 组件 | 软件包名 |
|---|---|
| nagios daemon | nagios-4.3.1.tar.gz |
| nrpe | nrpe-2.15.tar.gz |
| nagios plugin | nagios-plugins-2.2.0.tar.gz |
上述4个软件包下载链接:
链接:百度网盘 密码:ayhk
4.nagios系统软件部署
服务器侧软件安装
前提:使系统具备编译软件源码包的能力,并提前解决一些包、共享库文件之间的依赖关系,建议安装如下两个Group组件:
yum -y groupinstall "Development Tools" "Server Platform Development"
- 安装nagios依赖的软件包
nagios要通过web页面展现监控结果,所以nagios服务器同时还得是一个web服务器,因为nagios各种数据的实时展现是动态页面呈现的,因此还需要用到php。nagios要实现画图还依赖于gd、rrdtool包。按照官方说明安装如下包:
yum install httpd php
yum install gcc glibc glibc-common #如果安装那两个development包组这几个包应该已经装上了
yum install gd gd-devel
- 创建nagios用户及组
很多开源软件如果是通过源码包来进行安装,为后续的安装及服务运行做准备都需要通过事先创建好相应服务的账号及组。这里相关指令如下:
/usr/sbin/useradd -m nagios #指定不创建家目录
passwd nagios #设定nagios的密码,也可不设定
- 创建一个可以从web接口接受外部指令的用户组并将nagios及apache添加进组
/usr/sbin/groupadd nagcmd
/usr/sbin/usermod -a -G nagcmd nagios
/usr/sbin/usermod -a -G nagcmd apache
- 安装nagios core
nagios core就是前文提到的nagios daemon。解压软件包后,源码安装的通用三步骤:- configure
- make
- make install
此外相应指令如下:
./configure --with-command-group=nagcmd #nagios默认会安装在/usr/local/nagios目录下
configure完成以后若出现make all以完成编译的提示则继续执行:
make all
make install
make install-init
make install-config
make install-commandmode
make install-webconf
如果上述任一指令执行后有error发生或者某文件,某组件没有找到,务必先解决相应的错误,一般可能是某些包没有安装导致,根据提示信息中的关键字找出可能的包,然后yum安装上即可。
- 创建登录nagios web页面的用户及密码
默认系统中已存在名为nagiosadmin的账户,只需要给它指定密码,其密码会加密存储,密码文件默认为`/usr/local/nagios/etc/htpasswd.users,无需改动。
htpasswd -c /usr/local/nagios/etc/htpasswd.users nagiosadmin #根据提示输入密码即可
- 重启web服务
service httpd restart
- 安装plugin及nrpe组件
因为nagios服务器本身也同样需要被监控,自己监控自己或者被其它的nagios服务器所监控,所以它也需要安装plugin及nrpe组件。在软件包的解压目录中执行如下指令:
cd /root/softwares/nagios-plugins-2.2.0
./configure --with-nagios-user=nagios --with-nagios-group=nagios #默认安装在/usr/local/nagios路径下
make
make install
安装完plugin以后会在/usr/local/nagios/libexec目录下存放大量插件,就是用这些插件来实现最终的监控目的的。
**按着安装nrpe: **
nagios服务器安装nrpe包主要目的是为了安装check_nrpe插件,便于与被监控Linux端的NRPE daemon程序通信,如果这台nagios服务器也需要被其它nagios服务器监控,那它还必须安装nrpe daemon和nrpe daemon-config。
cd /root/softwares/nrpe-2.15
./configure #执行完会显示nrpe将会使用端口号5666
make all #configure执行完后若提示make all编译nrpe进程及客户端则执行这一指令
make install-plugin #安装check_nrpe插件,网络里就一台nagios服务器
#所以只安装这一个check_nrpe即可
- 设置web、nagios服务开机自启
chkconfig --add httpd
chkconfig --add nagios
chkconfig httpd on
chkconfig nagios on
- 通过web页面登录nagios
做完以上步骤以后,即可打开浏览器,输入http://nagios-server-ip/nagios,它会弹出提示框,输入前面提到的nagiosadmin及其密码即可登录。登录后的初始界面如下:

被监控端软件安装
在网络中需要被监控的Linux主机中安装nagios plugin和nrpe两个组件,并安装xinetd组件,用于启动nrpe程序。
- nagios plugin安装
创建nagios用户:
useradd -m nagios
将tar.gz包解压以后进入其目录,然后执行以下命令:
cd /root/softwares/nagios-plugins-2.2.0
./configure --with-nagios-user=nagios --with-nagios-group=nagios #默认安装在/usr/local/nagios路径下
make
make install
安装完成以后,建议修改安装目录/usr/local/nagios的属主为nagios,并可查看到其下有三个目录:
[root@test1 nagios]# ll
total 4
drwxr-xr-x 2 nagios nagios 6 Apr 7 23:30 include
drwxr-xr-x 2 nagios nagios 4096 Apr 7 23:30 libexec
drwxr-xr-x 3 nagios nagios 19 Apr 7 23:30 share
- 安装
nrpe:
客户端因为需要通过nrpe程序来执行从服务器侧接收到的command,因此必须安装nrpe。
cd /root/softwares/nrpe-2.15
./configure #执行完会显示nrpe将会使用端口号5666
make all #configure执行完后若提示make all编译nrpe进程及客户端则执行
make install-plugin #安装check_nrpe插件
make install-daemon #安装nrpe守护进程
make install-daemon-config #安装nrpe的配置文件
安装xinetd
根据nrpe的README文件的说明,可以将nrpe daemon作为xinetd下的一个服务来进行管理,所以需要事先将xinetd安装到系统中:
yum install xinetd -y #不要退出nrpe的解压包目录
再接着安装nrpe在xinetd下的配置文件:
make install-xinetd
修改nrpe的配置文件,以允许nagios server连接它:
vim /etc/xinetd.d/nrpe将only from改成如下内容:
only_from = 127.0.0.1 192.168.249.16 localhost #注意多个ip间以空格分开,主要是加上nagios server的ip
将nrpe服务端口号添加进去:vim /etc/services在最后一行加上nrpe 5666/tcp #Nagios-Client然后保存退出。
启动xinetd服务并设置开机自启:
chkconfig --add xinetd
chkconfig xinetd on
service xinetd start
**检查nrpe是否启动即端口5666是否处于监听状态: ss -tnl **
另一个检测nrpe是否工作正常的办法是在nagios服务器上使用check_nrpe插件来测试与这台客户端的nrpe通信是否正常:
cd /usr/local/nagios/libexec
./check_nrpe -H localhost #这里就是为何在被监控端也安装check_nrpe的原因
#这里的localhost必须在nrpe配置文件里明确允许
NRPE v2.15 #若返回NRPE的版本号,则表示NRPE工作正常
5.配置nagios监控主机及服务
5.1 nagios配置文件位置
nagios要对哪些主机监控哪些内容都是通过名为.cfg的配置文件进行定义的。
它们通常是位于/usr/local/nagios/etc目录中的*.cfg以及位于/usr/local/nagios/etc/objects目录下的*.cfg。
默认的文件如下:
[root@monitor-server1 etc]# ll /usr/local/nagios/etc
total 88
-rw-rw-r--. 1 nagios nagios 13023 Apr 7 15:35 cgi.cfg
-rw-r--r--. 1 nagios nagios 26 Apr 5 12:10 htpasswd.users
-rw-rw-r--. 1 nagios nagios 45139 Apr 7 19:20 nagios.cfg
-rw-r--r--. 1 nagios nagios 8060 Apr 5 20:49 nrpe.cfg
drwxrwxr-x. 2 nagios nagios 4096 Apr 6 01:28 objects
-rw-rw----. 1 nagios nagios 1312 Apr 5 11:59 resource.cfg
再看看/objects/目录下的内容:
[root@monitor-server1 objects]# ll
total 48
-rw-rw-r--. 1 nagios nagios 7344 Apr 6 01:28 commands.cfg
-rw-rw-r--. 1 nagios nagios 2138 Apr 5 11:59 contacts.cfg
-rw-rw-r--. 1 nagios nagios 5451 Apr 5 18:29 localhost.cfg
-rw-rw-r--. 1 nagios nagios 3070 Apr 5 11:59 printer.cfg
-rw-rw-r--. 1 nagios nagios 3252 Apr 5 11:59 switch.cfg
-rw-rw-r--. 1 nagios nagios 10716 Apr 5 18:32 templates.cfg
-rw-rw-r--. 1 nagios nagios 3180 Apr 5 11:59 timeperiods.cfg
-rw-rw-r--. 1 nagios nagios 3991 Apr 5 11:59 windows.cfg
5.2 各配置文件的作用:**
nagios.cfg主配置文件
nagios.cfg是nagios服务端的主配置文件,它可以定义其它*.cfg配置文件的位置,是否启用性能监控(收集监控数据以生成图表),性能数据处理指令,性能数据文件格式模板及存放位置等,配置nagios日志文件存放的信息级别及位置,nagios进程的启动用户及组,日志文件的切割方式,显示的日期格式等等。如果只是实现对主机及服务的监控,不出监控图的话,默认可以不改动这一文件。-
templates.cfg模板定义文件
templates.cfg是监控的模板文件,对所有主机、服务、联系人的定义为简化配置都可以根据需求定制相应的模板,然后在主机、服务、联系人配置文件中去引用模板即可。下面进行简要说明:define contact{ ;定义一个联系人相关的模板 name generic-contact ; 联系人信息的模板名称 service_notification_period 24x7 ; 对服务类的监控什么时间段可以发送告警通知 host_notification_period 24x7 ; 对主机类的监控什么时间段可以发送告警通知 service_notification_options w,u,c,r,f,s ; 对哪些服务状态进 行通知,w:警告,u:unknown未知状态,c:严重,r:recover恢复,f:flapping,s:scheduled downtime host_notification_options d,u,r,f,s ; 对哪些主机状态进行 ;通知,d:宕机了,u:主机不可达,r:主机重启了,f:flapping,s:恢复了 service_notification_commands notify-service-by-email ; 发送服务通知的方式 host_notification_commands notify-host-by-email ; 发送主机通知的方式 register 0 ; 告诉nagios daemon不要把这一项定义注册为服务,它只是一个模板 } define host{ ;定义一个用于主机的模板 name generic-host ; 主机模板的名称 notifications_enabled 1 ; 允许发送主机通知,0则为关闭 event_handler_enabled 1 ; 允许处理主机事件 flap_detection_enabled 1 ; 允许检测主机是否频繁发生状态改变 process_perf_data 1 ; 允许对主机进行性能统计 retain_status_information 1 ; Retain status information across program restarts retain_nonstatus_information 1 ; Retain non-status information across program restarts notification_period 24x7 ; 任意时间都可以发送通知消息 register 0 ; DONT REGISTER THIS DEFINITION - ITS NOT A REAL HOST, JUST A TEMPLATE! } define host{ ;定义另一个主机模板 name linux-server ; 主机模板的名称 use generic-host ; 先是引用了上面那个叫generic-host的主机模板,省去对通用项的重复定义工作 check_period 24x7 ; 定义对主机的检测周期 check_interval 5 ; 定义多长时间对主机进行一次检测 retry_interval 1 ; 当一次检测失败了隔多长时间再次检测 max_check_attempts 10 ; 最大几次失败后认定主机故障 check_command check-host-alive ; 使用哪个命令对主机进行检测,这一命令必须在commands.cfg文件中进行详细定义 notification_period workhours ; 定义什么时间段可以发送通知,这一配置在上一个叫generic_host的模板中也有,但此时此处以这个的配置为准,时间段的写法在timeperiods.cfg文件中定义 notification_interval 120 ; 发送通知的时间间隔 notification_options d,u,r ; 哪些主机状态可以发送通知 contact_groups admins ; Notifications get sent to the admins by default action_url /pnp4nagios/index.php/graph?host=$HOSTNAME$&srv=_HOST_ register 0 ; DONT REGISTER THIS DEFINITION - ITS NOT A REAL HOST, JUST A TEMPLATE! } define service{ ;定义一个服务模板 name generic-service ; 服务模板的名称 active_checks_enabled 1 ; 允许进行服务状态检测 passive_checks_enabled 1 ; 被动检测,由nagios发起,客户端nrpe接收到请求后使用plugin程序进行检测 parallelize_check 1 ; Active service checks should be parallelized (disabling this can lead to major performance problems) obsess_over_service 1 ; We should obsess over this service (if necessary) check_freshness 0 ; Default is to NOT check service 'freshness' notifications_enabled 1 ; 允许发送关于服务的通知 event_handler_enabled 1 ; Service event handler is enabled flap_detection_enabled 1 ; 允许检测服务状态漂移 process_perf_data 1 ; 开启性能数据采集 retain_status_information 1 ; Retain status information across program restarts retain_nonstatus_information 1 ; Retain non-status information across program restarts is_volatile 0 ; The service is not volatile check_period 24x7 ; 什么时间段对服务进行检测 max_check_attempts 3 ; 连续3次检测失败则认定服务故障 check_interval 10 ; 10分钟对服务进行一次检测 retry_interval 2 ; 一次检测失败了隔2分钟再次进行检测 contact_groups admins ; 将通知发给admins组里定义的成员 notification_options w,u,c,r ; Send notifications about warning, unknown, critical, and recovery events notification_interval 60 ; 对服务的告警每60分钟发一次 notification_period 24x7 ; 任何时间段都可以发送告警通知 register 0 ; DONT REGISTER THIS DEFINITION - ITS NOT A REAL SERVICE, JUST A TEMPLATE! }
以上便是templates.cfg文件中的主要内容,可以按需修改已定义的模板或者新定义模板。其中涉及到部分对command的定义,它是需要在commands.cfg文件中进行定义的。
-
commands.cfg命令定义文件
commands.cfg文件可以包含监控时需要用到的指令的定义,由这些指令来完成具体的监控工作,它们可以在services.cfg文件中被调用。配置示例如下:# 'notify-host-by-email' command definition define command{ command_name notify-host-by-email ;在templates.cfg文件 ;中即有一个叫作notify-host-by-email的 ;command引用,它引用的就是 此处定义的内容。command_name就相当于变量名 command_line /usr/bin/printf "%b" "***** Nagios *****\n\nNotification Type: $NOTIFICATIONTYPE$\nHost: $HOSTNAME$\nState: $HOSTSTATE$\nAddress: $HOSTADDRESS$ \nInfo: $HOSTOUTPUT$\n\nDate/Time: $LONGDATETIME$\n" | /bin/mail -s "** $NOTIFICATIONTYPE$ Host Alert: $HOSTNAME$ is $HOSTSTATE$ **" $CONTACTEMAIL$ ;定义命令具体的指令及参数,它就相当于是在给前面的变量赋值 } # 'notify-service-by-email' command definition define command{ command_name notify-service-by-email ;在templates.cfg文件中即有一个叫作notify-service-by-email的command引用,它引用的就是此处定义的内容 command_line /usr/bin/printf "%b" "***** Nagios *****\n\nNotification Type: $NOTIFICATIONTYPE$\n\nService: $SERVICEDESC$\nHost: $HOSTALIAS$\nAddress: $HOSTA DDRESS$\nState: $SERVICESTATE$\n\nDate/Time: $LONGDATETIME$\n\nAdditional Info:\n\n$SERVICEOUTPUT$\n" | /bin/mail -s "** $NOTIFICATIONTYPE$ Service Alert: $HOSTALIAS$/ $SERVICEDESC$ is $SERVICESTATE$ **" $CONTACTEMAIL$ # 'check-host-alive' command definition define command{ command_name check-host-alive ;定义检测主机存活的指令 command_line $USER1$/check_ping -H $HOSTADDRESS$ -w 3000.0,80% -c 5000.0,100% -p 5 } define command{ command_name check_http ;检测http服务是否可用的指令 command_line $USER1$/check_http -I $HOSTADDRESS$ $ARG1$
这里有一个名为check_nrpe的command特别重要:需要指定它才能够启动本地的check_nrpe去连接被监控端上的nrpe daemon,并在被监控端执行相应的命令,需要自己添加,默认commands.cfg文件里是没有的:
#`check_nrpe` command definition
define command{
command_name check_nrpe
command_line $USER1$/check_nrpe -H $HOSTADDRESS$ -c $ARG1$
;此处的$ARG1$这一变量指的就是在被监控端的nrpe.cfg文件
;里定义的实际命令,后面会有讲解
}
- contacts.cfg联系人定义文件
contracts.cfg这一文件定义了当需要发送告警通知时,需要发给哪些联系人组,然后不同的组里可以分别定义相应的成员,默认情况下会将通知发给名为admins的组,里面包含的email地址即为接收告警通知邮件的地址。示例如下:define contact{ contact_name nagiosadmin ; Short name of user use generic-contact ; Inherit default values from generic-contact template (defined above) alias Nagios Admin ; Full name of user email [email protected] ; <<***** CHANGE THIS TO YOUR EMAIL ADDRESS ****** }
define contactgroup{
contactgroup_name admins
alias Nagios Administrators
members nagiosadmin
}
- **timeperiods.cfg时间段模板定义文件**
`timeperiods.cfg`主要用来对要进行监控的时间段以及可以发送通知的时间段进行定义,很灵活很方便。
# notifications, etc. The classic "24x7" support nightmare. :-)
define timeperiod{
timeperiod_name 24x7
alias 24 Hours A Day, 7 Days A Week
sunday 00:00-24:00 ;这个名为24x7的时间模板包括了一周7天每天的24小时
monday 00:00-24:00
tuesday 00:00-24:00
wednesday 00:00-24:00
thursday 00:00-24:00
friday 00:00-24:00
saturday 00:00-24:00
}
# 'workhours' timeperiod definition
define timeperiod{
timeperiod_name workhours ;这个名为workhous的时间模板只包
;含了周一至周五每天的9点到17点
alias Normal Work Hours
monday 09:00-17:00
tuesday 09:00-17:00
wednesday 09:00-17:00
thursday 09:00-17:00
friday 09:00-17:00
}
- **localhost.cfg监控服务器配置文件**
`localhost.cfg`这个文件是用来定义对这台nagios服务器的哪些资源及服务进行监控的,它主要包含两部分的定义,针对host级别的和针对service级别的。示例如下:
```
define host{ ;定义一台linux主机
use linux-server ; 针对这台主机调用哪个host模
板,这里是调用templates.cfg中定义的linux-server模板,可以指定多个,
以逗号分隔
host_name localhost ;这台主机的名称
alias localhost ;这台主机的别名
address 127.0.0.1 ;这台主机的ip
process_perf_data 1 ;是否开启性能数据采集,这项
配置在linux-server模板里面也配置的有,当同一配置在不同的文件中 出现
时,配置单位越小的越优先,这里具体的单台主机肯定比一个主机模板的
范围要精细,所以这里的配置优先。
}
define hostgroup{ ;定义一个主机组,即把可以具有
;某些共同配置属性的主机放到一个组中
hostgroup_name linux-servers ; The name of the hostgroup
alias Linux Servers ; Long name of the group
members localhost ; Comma separated list of hosts that belong to this group
}
# Define a service to "ping" the local machine
define service{ ;定义一个要监控的服务
use local-service ; 针对这个服务调用的模
板,模板可以指定多个,以逗号分隔
host_name localhost ;监控哪个或哪些个主机的这
一服务,不同的主机间用逗事情隔开
service_description PING ;服务命名,简单明了即可,不要过长
check_command check_ping!100.0,20%!500.0,60% ;监
控要使用的指令,此处表示直接使用nagios服务器上/usr/local/libexec/下的
check_ping插件来进行服务监测。要查看目录中每个插件的用法,在目录下使
用./plugin_name --help查看
}
- **hosts.cfg定义要被监控的主机**
`hosts.cfg`文件可以将网络中所有需要监控的主机定义进来,并将它们根据需求分组,一台主机可以同时属于不同的组,默认情况下不允许组里面一台主机都没有,然后根据需要调用不同的主机模板(事先在templates.cfg中定义)。另一点很重要的是这个文件需要自己创建,不建议直接在localhost.cfg里添加。示例如下:
define host {
use linux-server ;调用的模板
host_name server1
alias server1
address 192.168.249.11
}
define host {
use linux-server
host_name server2
alias server2
address 192.168.249.12
}
define host {
use linux-server
host_name server3
alias server3
address 192.168.249.13
}
define host {
use linux-server
host_name server4
alias server4
address 192.168.249.14
}
define host {
use linux-server
host_name server5
alias server5
address 192.168.249.15
}
define hostgroup {
hostgroup_name loadblance-servers
alias lb-servers
members server1,server2
}
define hostgroup {
hostgroup_name web-servers
alias web-servers
members server3,server4
}
define hostgroup{
hostgroup_name database-servers
alias db-servers
members server1,server2,server5 ;根据业务需求,相同
;的主机可以属于多个不同的业务组
}
- **services.cfg定义要被监控的服务**
`services.cfg`这个文件默认也是不存在的,需要手工创建,可以以localhost.cfg里定义的service部分作为模板进行修改。在它里面可以针对不同的服务调用不同的模板,以及把这些服务应用到哪些主机或主机组上。示例如下:
# Define a service to "ping" the local machine
define service{
use local-service ; Name of service template to use
hostgroup_name web-servers,loadblance-servers,database-servers
service_description PING
check_command check_ping!100.0,20%!500.0,60%
check_interval 1
}
# Define a service to check the disk space of the root partition
# on the local machine. Warning if < 20% free, critical if
# < 10% free space on partition.
define service{
use local-service ; Name of service template to use
hostgroup_name web-servers,loadblance-servers,database-servers
service_description Root Partition
check_command check_nrpe!check_local_disk ;注意这种命令写法,凡是前面以check_nrpe!开头后面再跟上命令
;名称的,必须在commands.cfg中先定义check_nrpe这一命 令,前
;文有写,然后在到客户端上nrpe.cfg文件中定义check_nrpe!后面跟
;的命令的详细指令参数
}
# Define a service to check the number of currently logged in
# users on the local machine. Warning if > 20 users, critical
# if > 50 users.
define service{
use local-service ; Name of service template to use
hostgroup_name web-servers,loadblance-servers,database-servers
service_description Current Users
check_command check_nrpe!check_local_users
}
# Define a service to check the number of currently running procs
# on the local machine. Warning if > 250 processes, critical if
# > 400 processes.
define service{
use local-service ; Name of service template to use
hostgroup_name web-servers,loadblance-servers,database-servers
service_description Zombie Processes
check_command check_nrpe!check_local_zombie_procs
}
define service{
use local-service
hostgroup_name web-servers,loadblance-servers,database-servers
service_description Total Processes
check_command check_nrpe!check_local_total_procs
}
# Define a service to check the load on the local machine.
define service{
use local-service ; Name of service template to use
hostgroup_name web-servers,loadblance-servers,database-servers
service_description Current Load
check_command check_nrpe!check_local_load
}
# Define a service to check the swap usage the local machine.
# Critical if less than 10% of swap is free, warning if less than 20% is free
define service{
use local-service ; Name of service template to use
hostgroup_name web-servers,loadblance-servers,database-servers
service_description Swap Usage
check_command check_nrpe!check_local_swap
}
# Define a service to check SSH on the local machine.
# Disable notifications for this service by default, as not all users may have SSH enabled.
define service{
use local-service ; Name of service template to use
hostgroup_name web-servers,loadblance-servers,database-servers
service_description SSH
check_command check_ssh
notifications_enabled 0
}
# Define a service to check HTTP on the local machine.
# Disable notifications for this service by default, as not all users may have HTTP enabled.
define service{
use local-service ; Name of service template to use
hostgroup_name web-servers,loadblance-servers,database-servers
service_description HTTP
check_command check_http
notifications_enabled 0
}
由于新增加了两个配置 文件(hosts.cfg和services.cfg),所以需要在nagios主配置文件(nagios.cfg)中指明它们的位置,只需要在nagios.cfg中加上两行,搜索下`cfg_file`加到它们的下面即可:
cfg_file=/usr/local/nagios/etc/objects/hosts.cfg
cfg_file=/usr/local/nagios/etc/objects/services.cfg
### 5.3 检查配置文件
nagios自带的就有配置文件语法及逻辑检测工具,检测方式:
/usr/local/nagios/bin/nagios -v /usr/local/nagios/etc/nagios.cfg
检测如果没有问题,则可以重载nagios服务,使用最新配置文件来工作了。
Total Warnings: 0
Total Errors: 0
Things look okay - No serious problems were detected during the
pre-flight check
**重载服务**`service nagios reload`
### 5.4 客户端配置监测命令及参数
要实现对Linux主机的监控还差非常关键的一步,去到各被监控linux主机上配置实际要执行的指令,它们是在`/etc/usr/local/nagios/etc/nrpe.cfg`文件中定义的。 示例文件如下:
command[check_local_users]=/usr/local/nagios/libexec/check_users -w 5 -c 10
#注意[]中的内容,这些字符要和nagios服务端上
#services.cfg里定义command时check_nrpe!后面的字符完全一样,等号中的内容则通过
#前面介绍的方法查看每个plugin的具体用法
command[check_local_load]=/usr/local/nagios/libexec/check_load -w 15,10,5 -c 30,25,20
command[check_local_disk]=/usr/local/nagios/libexec/check_disk -w 20% -c 10% -p /dev/sda3
command[check_local_zombie_procs]=/usr/local/nagios/libexec/check_procs -w 5 -c 10 -s Z
command[check_local_total_procs]=/usr/local/nagios/libexec/check_procs -w 150 -c 200
command[check_local_swap]=/usr/local/nagios/libexec/check_swap -w 20% -c 10%
**注意**:[]中的内容,这些字符要和nagios服务端上
services.cfg里定义command时check_nrpe!后面的字符完全一样,等号中的内容则前面介绍的方法查看每个plugin的具体用法。
客户端在修改完nrpe.cfg文件以后,需要重启nrpe进程:
service xinetd restart #nrpe daemon是作为xinetd下的一个服务
#的,所以重启它也就重启了nrpe
## 6. 登录nagios web页面查看监控数据
在nagios客户端还没有配置好nrpe.cfg文件时,nagios server是无法监控到客户端的,此时应该可以通过web页面查看到一堆NRPE:undefined command之类的错误信息,当客户端nrpe服务修改完成并重启之后,过会儿就能够正常监控上这些客户端了。效果展示如下:


细心的读者可能已经发现两图中,日期格式好像更易读,默认会显示为`04-08-2017 22:30:00`这种,这是因为笔者修改了nagios.cfg的`date_format`为`iso8601`,具体可查看nagios.cfg文件获知。
## 7. 结尾
在前期安装及配置过程中要仔细留意可能出现的警告及错误信息,尽可能修复它们之后在后续操作,nagios跑起来以后,可以通过查看`/var/log/messages`或者`/usr/local/nagios/var/nagios.log`来观察错误信息,以找到解决办法。
比如:
在系统运行过程中因为nagios server和客户端nrpe间需要建立ssl会话,所以openssl,openssl-devel包是需要安装的。如果要使用snmp监控主机及服务则需要安装net-snmp包。如果对防火墙不熟悉建议关闭其服务,关闭SELinux。这些在文中未提到,但也是需要注意的地方。
通过nagios实现对主机和服务的监控基本操作方法就写到这儿,在日常使用中有很多可可以深入的地方,特别是对现网各种服务各项指标的监控工作,还需要开发插件然后部署才能够实现,这应该才是监控类软件应用真正有挑战的地方,考验运维工程师的开发能力,nagios支持使用perl、python、shell,C等语言开发插件以满足实际业务监控需求。