源代码来自于基于Scrapy的Python3分布式淘宝爬虫,做了一些改动,对失效路径进行了更新,增加了一些内容。使用了随机User-Agent,scrapy-redis分布式爬虫,使用MySQL数据库存储数据。
目录
第一步 创建并配置scrapy项目
第二步 将数据导出至json文件和MySQL数据库
第三步 设置随机访问头User-Agent
第四步 配置scrapy-redis实现分布式爬虫
数据分析部分:2018.7淘宝粉底市场数据分析
开发环境
- 电脑系统:macOS High Sierra
- Python第三方库:scrapy、pymysql、scrapy-redis、redis、redis-py
- Python版本:Anaconda 4.5.8 ,集成Python版本 3.6.4
- 数据库: MySQL 8.0.11、redis 4.0.1
第一步 创建scrapy项目
cmd输入:
scrapy startproject taobao
cd taobao
scrapy genspider -t basic tb taobao.com
1. 爬虫程序编写tb.py
- 在源代码的基础上添加了销量、产品描述信息的爬取;
- 更新了url分类判断的方式;
- 抓包取得的评论数网页格式有变化,更新了正则表达式。
# -*- coding: utf-8 -*-
import scrapy
import re
from scrapy.http import Request
from taobao.items import TaobaoItem
import urllib.request
class TbSpider(scrapy.Spider):
name = 'tb'
allowed_domains = ['taobao.com']
start_urls = ['http://taobao.com/']
def parse(self, response):
key = input("请输入你要爬取的关键词\t")
pages = input("请输入你要爬取的页数\t")
print("\n")
print("当前爬取的关键词是",key)
print("\n")
for i in range(0, int(pages)):
url = "https://s.taobao.com/search?q=" + str(key) + "&s=" + str(44*i)
yield Request(url=url, callback=self.page)
pass
#搜索页
def page(self,response):
body = response.body.decode('utf-8', 'ignore')
pat_id = '"nid":"(.*?)"' #匹配id
pat_now_price = '"view_price":"(.*?)"' #匹配现价格
pat_address = '"item_loc":"(.*?)"' #匹配商家地址
pat_sale = '"view_sales":"(.*?)人付款"' #销量
all_id = re.compile(pat_id).findall(body)
all_now_price = re.compile(pat_now_price).findall(body)
all_address = re.compile(pat_address).findall(body)
all_sale = re.compile(pat_sale).findall(body)
for i in range(0, len(all_id)):
this_id = all_id[i]
now_price = all_now_price[i]
address = all_address[i]
sale_count = all_sale[i]
url = "https://item.taobao.com/item.htm?id=" + str(this_id)
yield Request(url=url, callback=self.next, meta={ 'now_price': now_price, 'address': address,'sale_count':sale_count})
pass
pass
#详情页
def next(self, response):
item = TaobaoItem()
url = response.url
#由于淘宝和天猫的某些信息采用不同方式的Ajax加载,做一个分类
if 'tmall' in url: #天猫、天猫超市、天猫国际
title = response.xpath("//html/head/title/text()").extract() #获取商品名称
#price = response.xpath("//span[@class='tm-count']/text()").extract()
#这里获取商品原价格-但一直抓到的是空值,Xpath在xpath finder里验证有效,暂时不知道为什么。。。由于后续会影响到数据库的写入,暂时隐了
#以下是产品描述信息栏内的信息获得,检索文字标签获得对应内容:
brand = response.xpath("//li[@id='J_attrBrandName']/text()").re('品牌:\xa0(.*?)$') #品牌
produce = response.xpath("//li[contains(text(),'产地')]/text()").re('产地:\xa0(.*?)$') #产地
effect = response.xpath("//li[contains(text(),'功效')]/text()").re('功效:\xa0(.*?)$') #功效
pat_id = 'id=(.*?)&'
this_id = re.compile(pat_id).findall(url)[0]
pass
else: #淘宝
title = response.xpath("/html/head/title/text()").extract() #获取商品名称
#price = response.xpath("//em[@class = 'tb-rmb-num']/text()").extract()
#获取商品原价格-和上面保持一致
brand = response.xpath("//li[contains(text(),'品牌')]/text()").re('品牌:\xa0(.*?)$') #品牌
produce = response.xpath("//li[contains(text(),'产地')]/text()").re('产地:\xa0(.*?)$') #产地
effect = response.xpath("//li[contains(text(),'功效')]/text()").re('功效:\xa0(.*?)$') #功效
pat_id = 'id=(.*?)$'
this_id = re.compile(pat_id).findall(url)[0]
pass
#抓取评论总数
comment_url = "https://rate.taobao.com/detailCount.do?callback=jsonp144&itemId="+str(this_id)
comment_data = urllib.request.urlopen(comment_url).read().decode('utf-8', 'ignore')
each_comment = '"count":(.*?)}'
comment = re.compile(each_comment).findall(comment_data)
item['title'] = title
item['link'] = url
#item['price'] = price
item['now_price'] = response.meta['now_price']
item['comment'] = comment
item['address'] = response.meta['address']
item['sale_count'] = response.meta['sale_count']
item['brand']=brand
item['produce']=produce
item['effect']=effect
yield item
2. settings.py配置
设置用户代理、不遵循robots.txt协议、取消Cookies。
# -*- coding: utf-8 -*-
# Scrapy settings for taobao project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# http://doc.scrapy.org/en/latest/topics/settings.html
# http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html
# http://scrapy.readthedocs.org/en/latest/topics/spider-middleware.html
BOT_NAME = 'taobao'
SPIDER_MODULES = ['taobao.spiders']
NEWSPIDER_MODULE = 'taobao.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:54.0) Gecko/20100101 Firefox/54.0' #设置用户代理值
# Obey robots.txt rules
ROBOTSTXT_OBEY = False #不遵循 robots.txt协议
# Configure maximum concurrent requests performed by Scrapy (default: 16)
CONCURRENT_REQUESTS = 100
# Configure a delay for requests for the same website (default: 0)
# See http://scrapy.readthedocs.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
# DOWNLOAD_DELAY = 0.25 #设置访问延迟
# The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#CONCURRENT_REQUESTS_PER_IP = 16
# Disable cookies (enabled by default)
COOKIES_ENABLED = False #取消Cookies
# Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False
# Override the default request headers:
#DEFAULT_REQUEST_HEADERS = {
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
#}
# Enable or disable spider middlewares
# See http://scrapy.readthedocs.org/en/latest/topics/spider-middleware.html
#SPIDER_MIDDLEWARES = {
# 'taobao.middlewares.TaobaoSpiderSpiderMiddleware': 543,
#}
# Enable or disable downloader middlewares
# See http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html
#DOWNLOADER_MIDDLEWARES = {
# 'taobao.middlewares.MyCustomDownloaderMiddleware': 543,
#}
# Enable or disable extensions
# See http://scrapy.readthedocs.org/en/latest/topics/extensions.html
#EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
#}
# Configure item pipelines
# See http://scrapy.readthedocs.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'taobao.pipelines.TaobaoJsonPipeline':300 #导出文json文件
'taobao.pipelines.TaobaoPipeline':200 #导出至Mysql
}
# Enable and configure the AutoThrottle extension (disabled by default)
# See http://doc.scrapy.org/en/latest/topics/autothrottle.html
#AUTOTHROTTLE_ENABLED = True
# The initial download delay
#AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
#AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
#AUTOTHROTTLE_DEBUG = False
# Enable and configure HTTP caching (disabled by default)
# See http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
#HTTPCACHE_ENABLED = True
#HTTPCACHE_EXPIRATION_SECS = 0
#HTTPCACHE_DIR = 'httpcache'
#HTTPCACHE_IGNORE_HTTP_CODES = []
#HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
3.在items.py中添加存储容器对象
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# http://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class TaobaoItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field()
link = scrapy.Field()
#price = scrapy.Field()
comment = scrapy.Field()
now_price = scrapy.Field()
address = scrapy.Field()
sale_count = scrapy.Field()
brand = scrapy.Field()
produce = scrapy.Field()
effect = scrapy.Field()
pass
第二步 将数据导出并存储至Mysql数据库
1. 将数据导出为json
在pipeline.py文件内写入如下内容,在setting.py文件中开启(详见settings.py),
# -*- coding: utf-8 -*-
import json
import codecs
class TaobaoJsonPipeline:
def __init__(self):
self.file=codecs.open('taobao.json','w',encoding='utf-8')
def process_item(self, item, spider):
lines = json.dumps(dict(item), ensure_ascii=False) + '\n'
self.file.write(lines)
return item
def close_spider(self, spider):
self.file.close()
运行爬虫,在终端输入
scrapy crawl tb --nolog
导出后文件自动存储在爬虫目录下:

2.将数据导出至MySQL
1)首先要先下载安装MySQL数据库
下载链接,dmg格式,一键安装。(安装过程中要求设置root用户的密码,选择普通加密,如果选高级加密的话后面会一直连接失败....)
设置完成后开启数据库:

可视化操作安装 Workbentch,
Workbentch连接数据库,建立新的数据库,并新建表格并设置好字段:
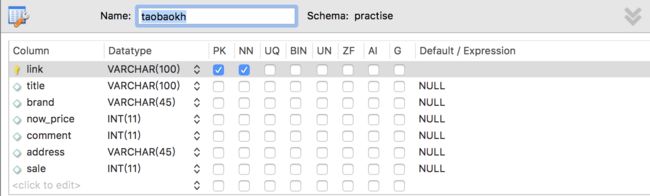
2)在Python中安装pymysql包
cmd输入:conda install pymysql
或者直接用pip install pymysql
3)pipelines.py文件设置
这里数据库存储使用了异步操作,目的是防止插入数据的速度跟不上网页的爬取解析速度,造成阻塞。Python 中提供了 Twisted 框架来实现异步操作,该框架提供了一个连接池,通过连接池可以实现数据插入 MySQL 的异步化。详细教程参考Scrapy 入门笔记(4) --- 使用 Pipeline 保存数据
在pipeline.py文件中加入以下代码,并在setting.py中开启对应pipeline(详见settings.py),
# -*- coding: utf-8 -*-
import pymysql
import pymysql.cursors
from twisted.enterprise import adbapi
class TaobaoPipeline(object):
#链接数据库
def __init__(self,):
dbparms = dict(
host='127.0.0.1',
db='数据库名称',
user='root',
passwd='数据库密码',
charset='utf8',
cursorclass=pymysql.cursors.DictCursor,
use_unicode=True,
)
# 指定擦做数据库的模块名和数据库参数参数
self.dbpool = adbapi.ConnectionPool("pymysql", **dbparms)
# 使用twisted将mysql插入变成异步执行
def process_item(self, item, spider):
query = self.dbpool.runInteraction(self.do_insert, item)
query.addErrback(self.handle_error, item, spider) #处理异常
#处理异步插入的异常
def handle_error(self, failure, item, spider):
print (failure)
#执行具体的插入
def do_insert(self, cursor, item):
#从item中导入
title = item['title'][0]
link = item['link']
#price = item['price'][0]
comment = item['comment'][0]
now_price = item['now_price']
address = item['address']
sale = item['sale_count']
brand=item['brand'][0]
produce=item['produce'][0]
effect = item['effect'][0]
print('商品标题\t', title)
print('商品链接\t', link)
#print('商品原价\t', price)
print('商品现价\t', now_price)
print('商家地址\t', address)
print('评论数量\t', comment)
print('销量\t', sale)
print('品牌\t',brand)
print('产地\t',produce)
print('功效\t',effect)
try:
sql="insert into taobaokh(title,link,comment,now_price,address,sale,brand,produce,effect) values(%s,%s,%s,%s,%s,%s,%s,%s,%s)"
values=(title,link,comment,now_price,address,sale,brand,produce,effect)
cursor.execute(sql,values)
print('导入成功')
print('------------------------------\n')
return item
except Exception as err:
pass
运行爬虫:
scrapy crawl tb --nolog

到此,爬虫基本已经可以正常运转起来了。
第三步 设置设置随机User-Agent
目的是每次请求时通过更换不同的user-agent,可以更好地伪装浏览器。
1.更新了源码的ua列表(PC端),添加到settings.py最后
USER_AGENT_LIST = [ "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36",
"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_5) AppleWebKit/603.2.4 (KHTML, like Gecko) Version/10.1.1 Safari/603.2.4",
"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; WOW64; rv:54.0) Gecko/20100101 Firefox/54.0",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36",
"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:54.0) Gecko/20100101 Firefox/54.0",
"Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:54.0) Gecko/20100101 Firefox/54.0",
"Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36",
"Mozilla/5.0 (Windows NT 6.1; WOW64; Trident/7.0; rv:11.0) like Gecko",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10.12; rv:54.0) Gecko/20100101 Firefox/54.0",
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36",
"Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:54.0) Gecko/20100101 Firefox/54.0",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.79 Safari/537.36 Edge/14.14393",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.109 Safari/537.36",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_6) AppleWebKit/603.2.5 (KHTML, like Gecko) Version/10.1.1 Safari/603.2.5",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.104 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; WOW64; Trident/7.0; rv:11.0) like Gecko",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36 Edge/15.15063",
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36",
"Mozilla/5.0 (Windows NT 6.3; WOW64; rv:54.0) Gecko/20100101 Firefox/54.0",
"Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36",
"Mozilla/5.0 (iPad; CPU OS 10_3_2 like Mac OS X) AppleWebKit/603.2.4 (KHTML, like Gecko) Version/10.0 Mobile/14F89 Safari/602.1",
"Mozilla/5.0 (Windows NT 6.1; rv:54.0) Gecko/20100101 Firefox/54.0",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; WOW64; rv:53.0) Gecko/20100101 Firefox/53.0",
"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:53.0) Gecko/20100101 Firefox/53.0",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10.11; rv:54.0) Gecko/20100101 Firefox/54.0",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.109 Safari/537.36",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.109 Safari/537.36",
"Mozilla/5.0 (X11; Linux x86_64; rv:54.0) Gecko/20100101 Firefox/54.0",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.104 Safari/537.36",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36",
"Mozilla/5.0 (X11; Linux x86_64; rv:52.0) Gecko/20100101 Firefox/52.0",
"Mozilla/5.0 (Windows NT 6.1; Trident/7.0; rv:11.0) like Gecko",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_4) AppleWebKit/603.1.30 (KHTML, like Gecko) Version/10.1 Safari/603.1.30",
"Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:54.0) Gecko/20100101 Firefox/54.0",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.86 Safari/537.36",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36",
"Mozilla/5.0 (Windows NT 5.1; rv:52.0) Gecko/20100101 Firefox/52.0",
"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.109 Safari/537.36",
"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:52.0) Gecko/20100101 Firefox/52.0",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.86 Safari/537.36",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Ubuntu Chromium/58.0.3029.110 Chrome/58.0.3029.110 Safari/537.36",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_5) AppleWebKit/603.2.5 (KHTML, like Gecko) Version/10.1.1 Safari/603.2.5",
"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.104 Safari/537.36",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.104 Safari/537.36",
"Mozilla/5.0 (X11; Linux x86_64; rv:45.0) Gecko/20100101 Firefox/45.0",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36",
"Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:53.0) Gecko/20100101 Firefox/53.0",
"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.86 Safari/537.36",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.86 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.86 Safari/537.36 OPR/46.0.2597.32",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Ubuntu Chromium/59.0.3071.109 Chrome/59.0.3071.109 Safari/537.36",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10.12; rv:53.0) Gecko/20100101 Firefox/53.0",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36",
"Mozilla/5.0 (Windows NT 6.3; WOW64; Trident/7.0; rv:11.0) like Gecko",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36 OPR/45.0.2552.898",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36",
"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:40.0) Gecko/20100101 Firefox/40.1",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36 OPR/46.0.2597.39",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10.10; rv:54.0) Gecko/20100101 Firefox/54.0",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_6) AppleWebKit/601.7.7 (KHTML, like Gecko) Version/9.1.2 Safari/601.7.7",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_3) AppleWebKit/602.4.8 (KHTML, like Gecko) Version/10.0.3 Safari/602.4.8",
"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; WOW64; Trident/7.0; Touch; rv:11.0) like Gecko",
"Mozilla/5.0 (Windows NT 6.1; rv:52.0) Gecko/20100101 Firefox/52.0",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.106 Safari/537.36",
]
DOWNLOADER_MIDDLEWARES = {
'taobao.middlewares.ProcessHeaderMidware': 543,
}
github上有人专门写了一个user-agent 的插件,也可以直接调用,链接
2.在middlewares.py文件里添加如下代码:
# encoding: utf-8
from scrapy.utils.project import get_project_settings
import random
settings = get_project_settings()
class ProcessHeaderMidware():
"""process request add request info"""
def process_request(self, request, spider):
"""
随机从列表中获得header, 并传给user_agent进行使用
"""
ua = random.choice(settings.get('USER_AGENT_LIST'))
spider.logger.info(msg='now entring download midware')
if ua:
request.headers['User-Agent'] = ua
# Add desired logging message here.
spider.logger.info(u'User-Agent is : {} {}'.format(request.headers.get('User-Agent'), request))
pass
设置完成。
第四步 使用Scrapy-redis实现分布式爬虫
为了进一步提高效率和防反爬虫能力,就要用到多进程和分布式爬虫了。
Scrapy-redis还有一个好处是支持断点续传,爬的过程中遇到过sracpy卡主住不动的情况,直接重新打开一个终端,输入爬虫指令,又继续跑起来~
1. Scrapy-redis环境搭建:
需要分别安装redis,scrapy-redis,和redis-py三个库:
1)redis
直接使用conda install redis安装(或pip install redis)
2) scrapy-redis
由于anaconda中没有scrapy-redis的安装包,需要下载第三方zip安装包,下载链接。安装过程:cmd依次输入
cd /Users/用户名/Downloads
unzip scrapy-redis-master.zip -d/Users/用户名/Downloads/ #解压文件到指定路径
cd scrapy-redis-master
python setup.py install #安装文件
password:***** #输入密码
如果不使用Anaconda,直接在终端pip install scrapy-redis应该也可以。
3) redis-py
装完redis之后,运行程序一直报错"ImportError: No module named redis",搜过之后发现是Python默认不支持Redis,需要安装redis-py才能正常调用。下载链接
安装方法同上。
2.修改Scrapy项目文件
1)在settings.py中增加以下内容
SCHEDULER = "scrapy_redis.scheduler.Scheduler" #启用Redis调度存储请求队列
SCHEDULER_PERSIST = True #不清除Redis队列、这样可以暂停/恢复 爬取
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter" #确保所有的爬虫通过Redis去重
SCHEDULER_QUEUE_CLASS = 'scrapy_redis.queue.SpiderPriorityQueue'
REDIS_HOST = '127.0.0.1' # 也可以根据情况改成 localhost
REDIS_PORT = 6379
REDIS_URL = None
2)在items.py中增加以下内容
from scrapy.loader import ItemLoader
from scrapy.loader.processors import MapCompose, TakeFirst, Join
class TaobaoSpiderLoader(ItemLoader):
default_item_class = TaobaoItem
default_input_processor = MapCompose(lambda s: s.strip())
default_output_processor = TakeFirst()
description_out = Join()
3)对tb.py文件进行更改
import相关包:
from scrapy_redis.spiders import RedisSpider
修改TbSpider类:
class TbSpider(RedisSpider):
name = 'tb'
#allowed_domains = ['taobao.com']
#start_urls = ['http://taobao.com/']
redis_key = 'Taobao:start_urls'
配置完成!
3. 运行分布式爬虫
1)打开终端,启动redis服务器redis-server:
localhost:~ $ redis-server
3708:C 20 Jul 22:42:41.914 # oO0OoO0OoO0Oo Redis is starting oO0OoO0OoO0Oo
3708:C 20 Jul 22:42:41.915 # Redis version=4.0.10, bits=64, commit=00000000, modified=0, pid=3708, just started
3708:C 20 Jul 22:42:41.915 # Warning: no config file specified, using the default config. In order to specify a config file use redis-server /path/to/redis.conf
3708:M 20 Jul 22:42:41.916 * Increased maximum number of open files to 10032 (it was originally set to 256).
_._
_.-``__ ''-._
_.-`` `. `_. ''-._ Redis 4.0.10 (00000000/0) 64 bit
.-`` .-```. ```\/ _.,_ ''-._
( ' , .-` | `, ) Running in standalone mode
|`-._`-...-` __...-.``-._|'` _.-'| Port: 6379
| `-._ `._ / _.-' | PID: 3708
`-._ `-._ `-./ _.-' _.-'
|`-._`-._ `-.__.-' _.-'_.-'|
| `-._`-._ _.-'_.-' | http://redis.io
`-._ `-._`-.__.-'_.-' _.-'
|`-._`-._ `-.__.-' _.-'_.-'|
| `-._`-._ _.-'_.-' |
`-._ `-._`-.__.-'_.-' _.-'
`-._ `-.__.-' _.-'
`-._ _.-'
`-.__.-'
3708:M 20 Jul 22:42:41.920 # Server initialized
3708:M 20 Jul 22:42:41.920 * DB loaded from disk: 0.000 seconds
3708:M 20 Jul 22:42:41.920 * Ready to accept connections
看到这个界面就证明服务器开启,关掉窗口。
2)打开一个新的终端,运行爬虫:
scrapy crawl tb --nolog
此时爬虫处于等待状态,需要设置start_url。
3)再打开一个新的终端,输入:
redis-cli
127.0.0.1:6379>LPUSH Taobao:start_urls http://taobao.com
(integer) 1
返回(integer) 1 则表示设置成功。(指令中的Taobao:start_urls对应tb.py文件中的设置redis_key = 'Taobao:start_urls')
4)此时,爬虫开始运行....MacOS不会像windows一样,弹出多个终端,只在一个终端里跑,但明显速度加快了好多。
5)如果要中途停止爬虫,按ctrl+c。
停止后再输入 scrapy crawl taobao –nolog 运行的话,程序会断点续传,原因是在setting.py中设置了 SCHEDULER_PERSIST = True 。
如果想取消这个功能,要把True改为False。
6)爬取完毕后,要清除redis缓存
127.0.0.1:6379>flushdb
ok
完毕!
总结:
通过Python3.6和scrapy构建了一个淘宝商品的爬虫,通过scrapy-redis实现了分布式爬虫,最后用MySQL来存储数据。
问题
- tmall链接下的商品原价格一直抓取失败,xpath在xpath finder验证可行,运行后一直是空值,猜测可能是网页有异步加载,待研究。
- tmall链接抓取过程中,很多链接进行了重定向(301、302)导致数据无法抓取,应该是跳转登录之类的反爬措施。
(声明:此文章仅作为学习交流,不做为其它用途)