介绍
CNN模型简化以减少参数数量及增加计算效率可分为两种主要方法:一类是设计参数更少、所需计算更少的CNN结构像MobileNet/SqueezeNet/ShuffleNet等;另一类则是在常规CNN模型(如VGG/Resnet/Inception v3 etc.)
之上进行参数Quantization,Binarization,以及filters或weights pruning以来减少原生CNN模型所需的参数数目及计算量,从而加快其计算速度,减少模型体积。
Filters pruning属于上面说的第二类方法。
Filters及相关feature maps pruning
下图是filters pruning的本质方法。一目了然,就是将每一个Weight tensor中不重要的output filters set去掉,并去掉与其相关联的下一层输入filters。

上述filters pruning方法可归纳为以下四个步骤:
- 对每个Filter Fi,j,计算每个输入filter set Fj的和(使用L1-Norm来计算filter之上weight的绝对值之和),即Sj = Σi(|Fi,j|);
- 对上步计算出的Sj进行排序,Sj大小反映了相关filter的重要性;
- 去掉m个权重最小的filters,并同时去掉与其相关的feature maps及下一层的所有相关的输入filters;
- 在本层(第i层)及下一层(i+1层)上分别新建两个Kernel weight矩阵,用来存取余下的filters(注意余下filters的顺序仍然与之前的相同)。
如何确定哪些filters需要被pruning
上面也大致说明了我们是通过计算每组输入filter之上的L1-norm,然后来将那些具有较小L1-norm值的filters pruning掉。这么做看似说得过去,毕竟小的参数对最终其输出影响肯定愈小,所谓人微了自然言轻,
因此在选择时,忽略掉小人物的声音而重点听取大人物的看法确实能对我们正确决策某件事情提供捷径。
文章中,也有试着在算出所有的filters的L1-norm后pruning掉那些L1-norm值大的filters,或者随机地裁filters,而不论其L1-norm值大小,不过最终结果却表明还是如我们经验所假定的那样即裁L1-norm最小的
filters,最终所获得的accuracy loss最小。
每层的filters被pruning多少比较合适呢
显然这里无法逃避,我们肯定要有一个meta variable用来表明裁多少filters比较合适,而且最好是layer-wise的一个参数,毕竟每一层上面filters的L1-norm分布不同,有些层是某些寡头说了算,实行中央集权制管理,
而有些则是西方民主型,必须得每个filter都发光发热、建言献策决定下一层才行。
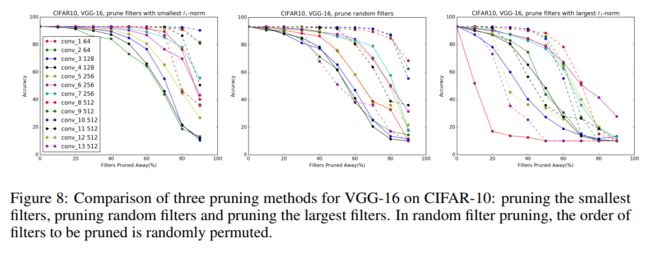
下图可表明VGG-16在CIFAR10上训练得到的模型不同层filters L1-norm分布及其可被裁filters份量而不过分减少整个模型accuracy loss之间的关系。

总结一下那就是不同的layer(模型的不同阶段,输入、输出feature maps大小不同,网络位置不同)具有迥然不同的filters L1-norm分布,需要特殊情况特殊处理。
有些Layers上的filters L1-norm分布非常不均(贫富差距大,大佬说了算),这时我们prun掉那些L1-norm小的filters,对最终的model accuracy影响并不大,有些还反而会有所提升(汗),当然是在pruning后再进行re-training得到的。
而有些layers上的filters L1-norm分布则非常平均(理想的大同社会吗?或者是当下日本所谓的橄榄球式社会财富结构?),这时若prun掉其中任意一些filters,都会使得整体模型的accuracy受到影响,有些甚至是大受影响。。
Okay..
有了以上信息后,我们的对策如下,(没错就是党一直告诉我们的办法,不同问题不同解决,实事求是。)
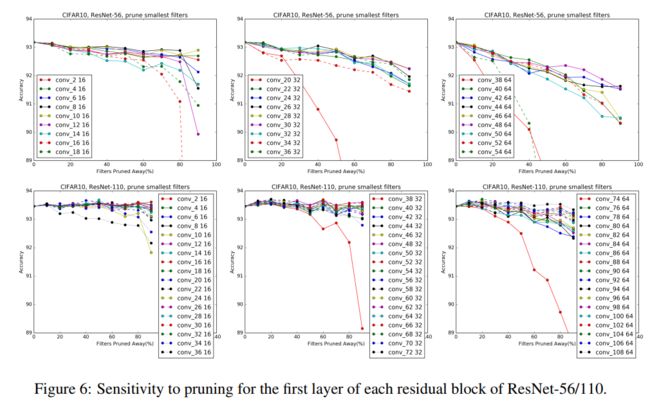
对那些分布不均的layers狠劲儿裁,反正那些L1-norm小的没啥用,不值得过多的资源耗在它们身上。
而对分布均匀的layer则小心裁,甚至不裁。有些layer我们裁了可能对model accuracy loss会有显著影响,但若影响尚能接受,而且裁后带来的计算效率明显提升,那么我们也可狠心将其裁掉。而有些layer则是硬骨头,我们稍动下它们,就翻脸无情地
将model accuracy给我们搞到最低,对这些狠角色,我们还是躲着点走好了,少动它们为妙。。
具体pruning时需考虑的策略
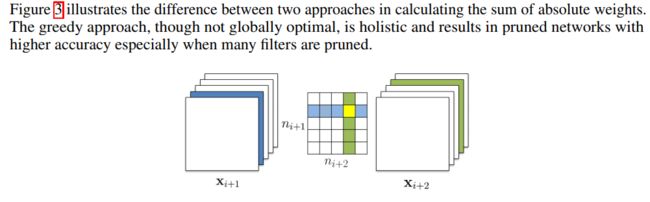
单个layer裁减时,我们要考虑是否应该考虑上一层被pruning layer对本layer的影响呢?其实有两种选择,要么考虑,要么就不考虑。
可由下图来看得出,无非就是在计算第j个输出filter set L1-norm Sj时是否考虑上个layer的pruning而已。
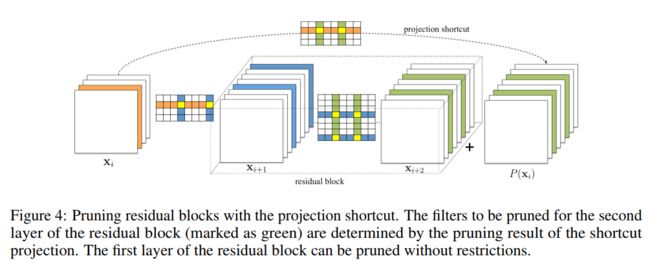
另外对于Residual block这种特殊结构,我们同样要具体问题具体分析。
对于residual模块有多个conv layer的情况,第一个conv layer无所谓,可以正常pruning,而第二个的oc数目多少则需要保证跟identity mapping出来的数目一致,同时也要保证它们裁减相同的filters(不然残差的表示就无法跟自已本家对得上了。。请
仔细考虑residual learning的含意。。)
Prun后如何Retrain
共有两种方式:一种是将整个network的每一层layer都prun后再整体进行re-train;另外一种则是每prun一层layer或者一个stage的layers组合,就进行一轮retrain。
其优点缺点显而易见,第一种比较省时省力,第二种更加精耕细作,但也麻烦不少。
一般如果一个模型中要裁的layers大多是那种对model accuracy loss不敏感的那么可以使用第一种方法,不然若想裁得比较多(狠),而且想动那些对accuracy敏感的层,那么就得使用第二种方法了。
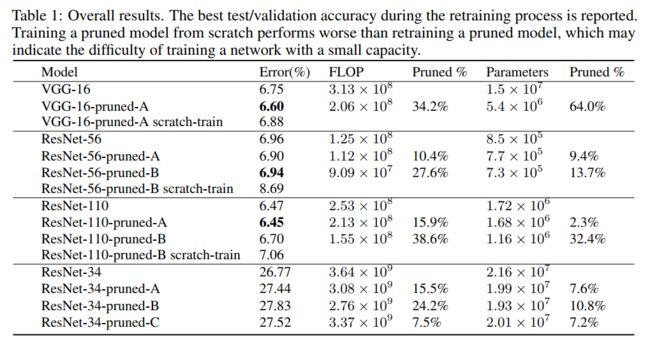
实验结果
下面为作者使用Resnet56/Resnet-110/VGG16(在CIFAR10上)以及Resnet-34(在Imagenet上)分别使用pruning及re-training后得到的结果。
参考文献
- PRUNING FILTERS FOR EFFICIENT CONVNETS, Hao-Li, 2017