TensorFlow是谷歌推出的深度学习平台,目前在各大深度学习平台中使用的最广泛。
一、安装命令
pip3 install -U tensorflow --default-timeout=1800 -i https://mirrors.ustc.edu.cn/pypi/web/simple
上面是不支持GPU的版本,支持GPU版本的安装命令如下
pip3 install -U tensorflow-gpu --default-timeout=1800 -i https://mirrors.ustc.edu.cn/pypi/web/simple
https://mirrors.ustc.edu.cn/pypi/web/simple 是国内的镜像,安装速度更快
二、基本数据类型
TensorFlow 中最基本的单位是常量(Constant)、变量(Variable)和占位符(Placeholder)。常量在定义后它的值和维度不可变,变量在定义后它的值可变而维度不可变。在神经网络中,变量一般可作为存储权重和其他信息的矩阵,常量可作为存储超参数或其他结构信息的变量。
三、使用TensorFlow进行机器学习的基本流程
● 准备样本数据(训练样本、验证样本、测试样本)
● 定义节点准备接收数据
● 设计神经网络:隐藏层和输出层
● 定义损失函数loss
● 选择优化器(optimizer) 使 loss 达到最小
● 对所有变量进行初始化,通过 sess.run optimizer,迭代N次进行学习
下面的示意图是所有 TensorFlow 机器学习模型所遵循的构建流程,即构建计算图、把数据输入张量、更新权重变量并返回输出值。
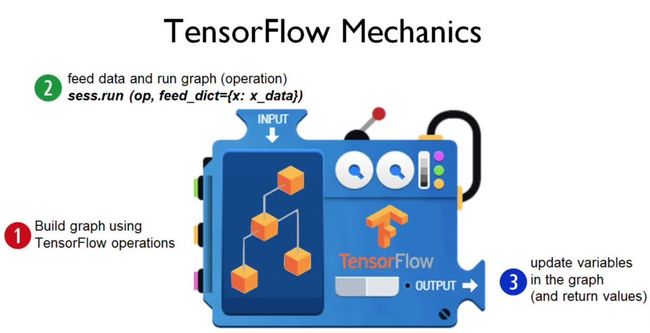
在第一步使用 TensorFlow 构建计算图中,需要构建整个模型的架构。例如在神经网络模型中,需要从输入层开始构建整个神经网络的架构,包括隐藏层的数量、每一层神经元的数量、层级之间连接的情况与权重、整个网络中每个神经元使用的激活函数等。此外,还需要配置整个训练、验证与测试的过程。例如在神经网络中,定义整个正向传播的过程与参数并设定学习率、正则化率和批量大小等各类超参数。
第二步将训练数据或测试数据等输送到模型中,TensorFlow 在这一步中一般需要打开一个会话(Session)来执行参数初始化和输送数据等任务。例如在计算机视觉中,需要随机初始化整个模型参数数值,并将图像成批(图像数等于批量大小)地输送到定义好的卷积神经网络中。
第三步更新权重并获取返回值,控制训练过程与获得最终的预测结果。
TensorFlow 线性回归示例
线性回归模型如下图所示
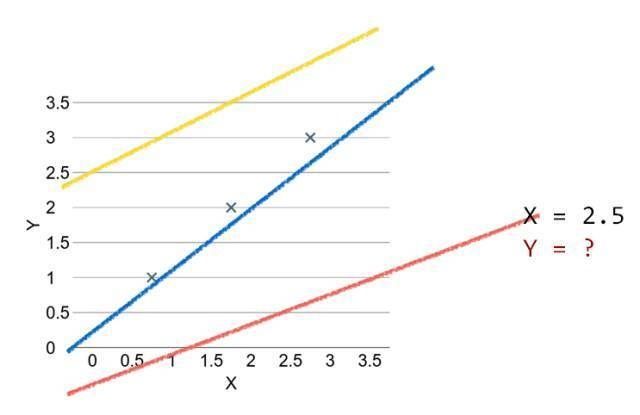
其中「×」为数据点,找到一条直线最好地拟合这些数据点,这条直线和数据点之间的距离即损失函数,所以我们希望找到一条能令损失函数值最小的直线。以下是使用 TensorFlow 构建线性回归的简单示例。
1、构建目标函数(即直线)
目标函数即 H(x)=Wx+b,其中 x 是特征向量、W是特征向量中每个元素对应的权重(Weight)、b(Bias)是偏置项。
# 用来训练模型的样本数据
x_train = [1, 2, 3]
y_train = [1, 2, 3]
W = tf.Variable(tf.random_normal([1]), name='weight')
b = tf.Variable(tf.random_normal([1]), name='bias')
# hypothesis函数 XW+b
hypothesis = x_train * W + b
如上所示定义了 y=wx+b 的运算,即需要拟合的一条直线。
2、构建损失函数
下面构建损失函数,即各数据点到该直线的距离,这里构建的损失函数是均方误差函数:
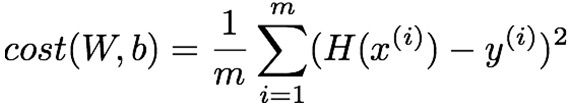
该函数表明根据数据点预测的值和该数据点真实值之间的距离,代码实现:
# 代价/损失 函数
cost = tf.reduce_mean(tf.square(hypothesis - y_train))
其中 tf.square() 是取某个数的平方, tf.reduce_mean() 是取均值。
3、采用梯度下降更新权重
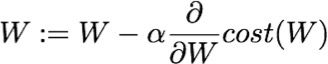
α是学习速率(Learning rate),控制学习速度,需要调节的超参数。
# 最小化
optimizer = tf.train.GradientDescentOptimizer(learning_rate=0.01)
train = optimizer.minimize(cost)
为了寻找能拟合数据的最好直线,需要最小化损失函数,即数据与直线之间的距离,采用梯度下降算法。
4、 运行计算图开始训练模型
# 打开一个会话Session
sess = tf.Session()
# 初始化变量
sess.run(tf.global_variables_initializer())
# 迭代
for step in range(2000):
sess.run(train)
if step % 200 == 0:
print(step, sess.run(cost), sess.run(W), sess.run(b))
上面的代码打开了一个会话并执行变量初始化和输送数据。
5、完整的实现代码
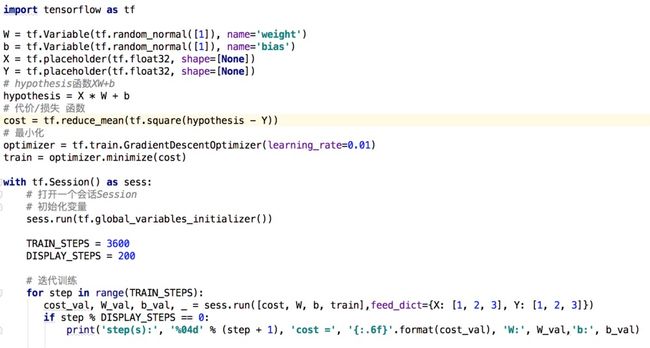
6、某次训练时的输出
step(s): 0001 cost = 0.595171
step(s): 0201 cost = 0.002320
step(s): 0401 cost = 0.000886
step(s): 0601 cost = 0.000338
step(s): 0801 cost = 0.000129
step(s): 1001 cost = 0.000049
step(s): 1201 cost = 0.000019
step(s): 1401 cost = 0.000007
step(s): 1601 cost = 0.000003
step(s): 1801 cost = 0.000001
四、简单小结
本文简述了使用TensorFlow训练模型的过程,无论设计多么复杂的神经网络,都可以参考以上过程,当然在实际生产中还需要考虑很多因素,比如:样本数据的收集、样本数据的预处理、模型的选择和神经网络的设计、过拟合/欠拟合问题、梯度消失/膨胀问题、超参数的设置、是否需要GPU和分布式加快训练速度等等。
在设计深度网络时需要注意每层神经元的维度,这个地方容易出错,特别是层数深、每层神经元数量多的复杂神经网络, 参见《介绍一个快速确定神经网络模型中各层矩阵维度的方法》。
ps:目前多个厂家都推出了机器学习公有平台,一般都会支持TensorFlow,在公有平台上学习AI算法比自己搭建平台省心。