面试官:谈谈你对mysql索引的认识?
引言
大家好,我渣渣烟。我曾经写过一篇《面试官:谈谈你对表设计的认识?》于是呢,决定再来一个mysql的数据库专题,这篇我们就来谈谈关于索引方面的mysql面试题。还是老规矩,讲的是在Innodb存储引擎下的情形,毕竟我还真没用过Mysiam之类的存储引擎。ps:其实很早就想写了,一直偷懒!
其实这下面每个问题,我都可以讲一篇文章出来!而且这些问题,不是我凭空编的。如下图所示(注意看第三题)

所以我回忆了一下,索引常见考点有哪些,总结成了这篇文章!
主要题目有下面这些
-
(1)你一般怎么建索引的?
-
(2)讲讲索引的分类?你知道哪些?
-
(3)如何避免回表查询?什么是索引覆盖?
-
(4)现在我有一个列,里头的数据都是唯一的,需要建一个索引,选唯一索引还是普通索引?
-
(5)mysql索引是什么结构的?用红黑树可以么?
-
(6)mysql某表建了多个单索引,查询多个条件时如何走索引的?
正文
1、你一般怎么建索引的?烟哥注:曾记得有一个粉丝来找我的时候,出现如下搞笑一幕
渣渣烟:"你这个简历上写了拥有SQL优化经验,你怎么建索引的?"
只见该粉丝嘿嘿一笑..说道:"就那样建啊…"
渣渣烟:"噢(第二声),就哪样建啊…"
粉丝:"…就网上说的那些索引规则啊"
渣渣烟:"那你怎么知道那些SQL出问题,需要建索引呢?"粉丝:"我….."
嗯,这道题其实很基础。但是有没有做过,这题是可以看出来的。
打开慢查询日志
slow_query_log=1
慢查询日志存储路径
slow_query_log_file=/var/log/mysql/log-slow-queries.log
SQL执行时间大于3秒,则记录日志
long_query_time=3
监控到慢SQL后,就马上开始建索引?例如,当只要一行数据时使用 limit 1
然而大多数情况下,业务SQL十分复杂,没法优化。所以就要建立索引了。这个时候,参照如下规则建立索引
-
(1)索引并非越多越好,大量的索引不仅占用磁盘空间,而且还会影响insert,delete,update等语句的性能
-
(2)避免对经常更新的表做更多的索引,并且索引中的列尽可能少;对经常用于查询的字段创建索引,避免添加不必要的索引
-
(3)数据量少的表尽量不要使用索引,由于数据较少,查询花费的时间可能比遍历索引的时间还要短,索引可能不会产生优化效果
-
(4)在条件表达式中经常用到不同值较多的列上创建索引,在不同值很少的列上不要建立索引。比如性别字段只有“男”“女”俩个值,就无需建立索引。如果建立了索引不但不会提升效率,反而严重减低数据的更新速度
-
(5)在频繁进行排序或者分组的列上建立索引,如果排序的列有多个,可以在这些列上建立联合索引。
2、讲讲索引的分类?你知道哪些?
从物理存储角度:
聚簇索引和非聚簇索引
从数据结构角度:
B+树索引、hash索引、FULLTEXT索引、R-Tree索引
从逻辑角度:
-
主键索引:主键索引是一种特殊的唯一索引,不允许有空值
-
普通索引或者单列索引
-
多列索引(复合索引):复合索引指多个字段上创建的索引,只有在查询条件中使用了创建索引时的第一个字段,索引才会被使用。使用复合索引时遵循最左前缀集合
-
唯一索引或者非唯一索引
-
空间索引:空间索引是对空间数据类型的字段建立的索引,MYSQL中的空间数据类型有4种,分别是GEOMETRY、POINT、LINESTRING、POLYGON。
3、如何避免回表查询?什么是索引覆盖?
这个问题,如果要看详细版,请参阅文章《Innodb中索引的原理》
这里简单说一下。
例如此时有一张表table1,有一个联合索引(a,b)
执行如下SQL
select a,b from table1
在索引上就能找到结果,就不用回表去查询!
select a,b,c from table2
c列在索引上不存在,就需要回表查询。
需要说明的是覆盖索引必须要存储索引列的值,而哈希索引、空间索引和全文索引不存储索引列的值,所以mysql只能用B+ tree索引做覆盖索引。
4、现在我有一个列,里头的数据都是唯一的,需要建一个索引,选唯一索引还是普通索引?
【强制】业务上具有唯一特性的字段,即使是多个字段的组合,也必须建成唯一索引
说明:不要以为唯一索引影响了 insert 速度,这个速度损耗可以忽略,但提高查找速度是明显的;另外,即使在应用层做了非常完善的校验控制,只要没有唯一索引,根据墨菲定律,必然有脏数据产生。
那好,下一问出现了!
为什么唯一索引的插入速度比不上普通索引?为什么唯一索引的查找速度比普通索引快?
这么做的优点:能将多个插入合并到一个操作中,就大大提高了非聚簇索引的插入性能。
InnoDB 从 1.0.x 版本开始引入了 Change Buffer,可以算是对 Insert Buffer 的升级。从这个版本开始,InnoDB 存储引擎可以对 insert、delete、update 都进行缓存。
唯一速度的插入比普通索引慢的原因就是:
-
唯一索引无法利用Change Buffer
-
普通索引可以利用Change Buffer
于是乎下一问又来了!为什么唯一索引的更新不使用 Change Buffer?
因为唯一索引为了保证唯一性,需要将数据页加载进内存才能判断是否违反唯一性约束。但是,既然数据页都加载到内存了,还不如直接更新内存中的数据页,没有必要再使用Change Buffer。
最后回答一下,唯一索引的搜索速度比普通索引快的原因就是:
-
普通索引在找到满足条件的第一条记录后,还需要判断下一条记录,直到第一个不满足条件的记录出现。
-
唯一索引在找到满足条件的第一条记录后,直接返回,不用判断下一条记录了。
5、mysql索引是什么结构的?用红黑树可以么?
那为啥不用B Tree,而选择B+ tree呢?
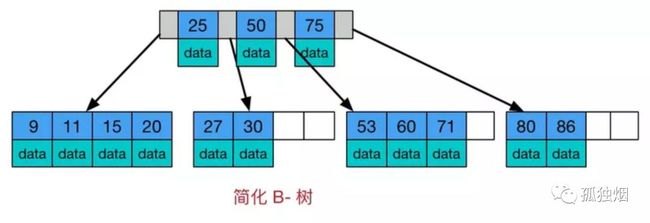
注意一下B tree的两个明显特点
-
树内存储数据
-
叶子节点上无链表
而B+ tree长下面这样的
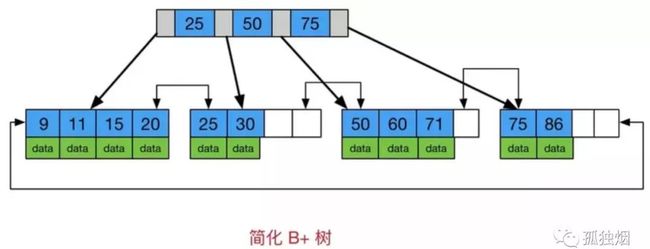
注意一下B+ tree的两个明显特点
-
数据只出现在叶子节点
-
所有叶子节点增加了一个链指针
接下来就可以开始编了~~比如数据库索引采用B+ tree的主要原因是B Tree在提高了磁盘IO性能的同时并没有解决元素遍历的效率低下的问题。正是为了解决这个问题,B+ tree应运而生。B+ tree只要遍历叶子节点就可以实现整棵树的遍历。而且在数据库中基于范围的查询是非常频繁的,如果使用B Tree,则需要做局部的中序遍历,可能要跨层访问,效率太慢。
提示,我下一问就是:
6、mysql某表建了多个单索引,查询多个条件时如何走索引的?
这里希望大家先看看我的另一篇文章
Mysql在优化器中有一个优化器称为Range 优化器,负责进行范围查询的优化!
它们是MySQL优化器对开销代价的估算方法,前者统计速度慢但是能得到精准的值,后者统计速度快但是数据未必精准。
坦白说写到这里,我内心痛哭流涕,要把index dive和index statistics写明白,真不是一件容易的事,这里只能稍微扯扯。
对于index dive:
COST = CPU COST + IO COST
其中CPU COST指的是处理返回记录所花的开销。而IO COST指的是读取页面的开销。
mysql会对每种索引的执行情况,进行上述成本计算,最后以成本小的方式进行执行。
但是呢,在某些情况下mysql执行index dive的成本太大。因此优化器会选择以index statistics方式进行估算成本。
SHOW INDEX FROM tbl_name [FROM db_name]
此时出来的结果中,有一列名为Cardinality,该值表示索引列中不重复值的个数。Cardinality值越大,就意味着,使用索引能排除越多的数据,执行也更为高效。