tensorflow实战---手写体识别
基础解释
digits = load_digits() #载入数据集
print (digits.target_names) #输出数据集中所有标签
print (digits.keys()) #输出数据类型
print (digits.data[12]) #获取标签为12的数字图片数据,8 ×8 的矩阵
print (digits.target[12]) #获取标签为12的数字图片所识别的数字#输出
[0 1 2 3 4 5 6 7 8 9] #所有标签(即所有分类)
dict_keys(['data', 'target', 'target_names', 'images', 'DESCR']) #数据类型,即数据集包括的属性
[ 0. 0. 5. 12. 1. 0. 0. 0. 0. 0. 15. 14. 7. 0. 0.
0. 0. 0. 13. 1. 12. 0. 0. 0. 0. 2. 10. 0. 14. 0.
0. 0. 0. 0. 2. 0. 16. 1. 0. 0. 0. 0. 0. 6. 15.
0. 0. 0. 0. 0. 9. 16. 15. 9. 8. 2. 0. 0. 3. 11.
8. 13. 12. 4.] #8×8的矩阵,第12张图的矩阵表示
2 #标签为12的图识别的数字1.softmax回归
准确率91%,较低
数据集下载自MNIST官网
包含四个压缩文件

不必解压放到目录就好
#完整代码
#仅做记录,详细解释有待补充
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("G:/MNIST_data/",one_hot=True)
print('训练集信息:')
print(mnist.train.images.shape,mnist.train.labels.shape)
print('测试集信息')
print(mnist.test.images.shape,mnist.test.labels.shape)
print('验证集信息')
print(mnist.validation.images.shape,mnist.validation.labels.shape)
sess = tf.InteractiveSession()
x = tf.placeholder(tf.float32,[None,784])
w = tf.Variable(tf.zeros([784,10]))
b = tf.Variable(tf.zeros([10]))
y = tf.nn.softmax(tf.matmul(x,w) + b)
y_ = tf.placeholder(tf.float32,[None,10])
#交叉熵
cross_entropy = tf.reduce_mean(-tf.reduce_sum(y_*tf.log(y),reduction_indices = [1]))
train_step = tf.train.GradientDescentOptimizer(0.5).minimize(cross_entropy)
#训练
tf.global_variables_initializer().run()
for i in range(1000):
batch_xs,batch_ys = mnist.train.next_batch(100)
train_step.run({x:batch_xs,y_:batch_ys})
#模型评估
correct_prediction = tf.equal(tf.argmax(y,1),tf.argmax(y_,1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction,tf.float32))
print('MNIST手写图片准确率')
print(accuracy.eval({x:mnist.test.images,y_:mnist.test.labels}))代码来源
2.CNN实现手写体
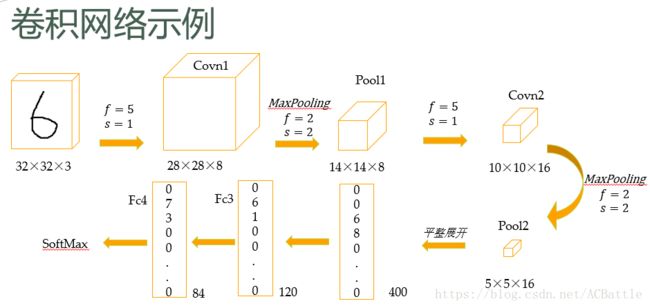
这个完全可以通过代码学习典型CNN。
看吴恩达视频的时候,没注意到有dropout这个概念,但是代码中加了这一步,补充一下概念dropout:
主要是为了防止发生过拟合,可以看做是一种模型平均,所谓模型平均,顾名思义就是把来自不同模型的估计或者预测通过一定的权重平均起来,在一些文献中也称为模型组合,它一般包括组合估计和组合预测。
dropout 我们随机选择隐藏层节点,在每个批次的训练过程中,每次随机忽略的隐层节点都不同,这样就使得每次训练的网络都是不一样的,每次训练都可以单做一个“新”的模型;
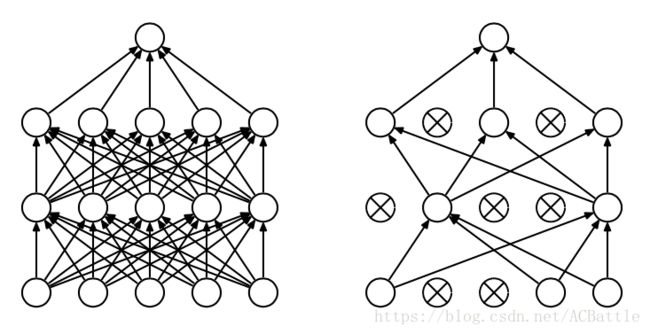
即每次做完dropout ,相当于从原始的网络中找到一个更瘦的网络。
此外,隐含节点都是以一定概率随机出现,因此不能保证每2个隐含节点每次都同时出现。阻止了某些特征仅仅在其他特征下才有效果的情况。
这样的dropout过程通过训练大量的不同的网络,来平均预测概率,不同的模型在不同训练集上训练(每个批次的训练数据都是随机选择),最后再每个模型用相同的权重“融合”,类似boosting算法。

完整代码:
有待补充更详细:
import tensorflow as tf
import numpy as np
from tensorflow.examples.tutorials.mnist import input_data
batch_size = 128
test_size = 256
def init_weights(shape):
return tf.Variable(tf.random_normal(shape,stddev=0.01))
def model(X,w,w2,w3,w4,w_o,p_keep_conv,p_keep_hidden): #p_keep_conv 是概率
# tf.nn.cov2d(输入,过滤器,步长[1,水平滑动步长,垂直滑动步长,1],padding)
# 其中步长为1×4的矩阵,前后规定为1------------------------------???????????????????????????
#tf.max_pool(输入,滑动窗口,步长,padding)
#tf.dropout(输入,卷积层)
#----------------------------------------------第一层---------------------------------------
#第一个卷积层:padding=SAME
l1a = tf.nn.relu(tf.nn.conv2d(X,w,strides=[1,1,1,1],padding='SAME'))
#第一个最大池化层:窗口大小为2×2
l1 = tf.nn.max_pool(l1a,ksize=[1,2,2,1],strides=[1,2,2,1],padding='SAME') #输入,窗口大小,步长,padding
#没明白drop_out的含义----------------------------------??????????????????????????
#dropout:每个神经元有p_keep_conv的概率以1/p_keep_conv的比例进行归一化,有()
l1 = tf.nn.dropout(l1,p_keep_conv)
# -------------------------------------------第二层-------------------------------
#第二个卷积层:padding = same
l2a = tf.nn.relu(tf.nn.conv2d(l1,w2,strides=[1,1,1,1],padding='SAME'))
#第二个最大池化层:窗口大小为2×2
l2 = tf.nn.max_pool(l2a,ksize=[1,2,2,1],strides=[1,2,2,1],padding='SAME')
l2 = tf.nn.dropout(l2,p_keep_conv)
# -------------------------------------------第三层-------------------------------
# 第三个卷积层:padding = same
l3a = tf.nn.relu(tf.nn.conv2d(l2,w3,strides=[1,1,1,1],padding='SAME'))
# 第三个最大池化层:窗口大小为2×2
l3 = tf.nn.max_pool(l3a,ksize=[1,2,2,1],strides=[1,2,2,1],padding='SAME')
# -------------------------------------------第四层-------------------------------
# 后面两层为全连接层
#将所有的feature map合并成一个2048维向量
l3 = tf.reshape(l3,[-1,w4.get_shape().as_list()[0]])
l3 = tf.nn.dropout(l3,p_keep_conv) #p_keep_conv 是概率
# -------------------------------------------第五层-------------------------------
# 输出层用了一次激活函数,没用到softmax回归?????????????????????????????
l4 = tf.nn.relu(tf.matmul(l3,w4))
l4 = tf.nn.dropout(l4,p_keep_hidden) #???????参数的含义?????????????????
#l4 和 w_o
pyx = tf.matmul(l4,w_o)
return pyx
#读取数据
mnist = input_data.read_data_sets("G:/MNIST_data/",one_hot = True)
trX = mnist.train.images
trY = mnist.train.labels
teX = mnist.test.images
teY = mnist.test.labels
trX = trX.reshape(-1,28,28,1)
teX = teX.reshape(-1,28,28,1)
X = tf.placeholder("float",[None,28,28,1])
Y = tf.placeholder("float",[None,10])
#---------------------------过滤器是随机初始化的?????????????
w = init_weights([3,3,1,32])
w2 = init_weights([3,3,32,64])
w3 = init_weights([3,3,64,128])
w4 = init_weights([128*4*4,625]) #2048输入,625输出
w_o = init_weights([625,10]) #2625输入,10输出
p_keep_conv = tf.placeholder("float") #值确定吗??????????????????
p_keep_hidden = tf.placeholder("float")
py_x = model(X, w, w2, w3, w4, w_o,p_keep_conv, p_keep_hidden)
#损失函数
cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=py_x,labels=Y)) #求平均值
#------------------------------------------------------------??????????????--------------------------------------------
train_op = tf.train.RMSPropOPtimizer(0.001,0.9).minimize(cost)
predict_op = tf.argmax(py_x,1)
with tf.Session() as sess:
tf.initialize_all_variable().run()
for i in range(100):
training_batch = zip(range(0,len(trX),batch_size),
range(batch_size,len(trX)+1,batch_size))
for start,end in training_batch:
sess.run(train_op,feed_dict={X:trX[start:end],Y:trY[start:end],p_keep_conv:0.8,p_keep_hidden:0.5})
test_indices = np.arange(len(teX))
np.random.shuffle(test_indices)
test_indices = test_indices[0:test_size]
print(i,np.mean(np.argmax(teY[test_indices],axis=1) ==
sess.run(predict_op,feed_dict = {X: teX[test_indices],
Y: teY[test_indices],
p_keep_conv:1.0,
p_keep_hidden:1.0})))3.使用最近邻实现手写体识别?????
看到还有这么一种方法,未细看