内核中各种同步机制(自旋锁大内核锁顺序锁等)
- 原子操作
- 自旋锁
- 读写自旋锁
- 信号量
- 读写信号量
- 互斥量
- 完成变量
- 大内核锁
- 顺序锁
- 禁止抢占
- 顺序和屏障
- 如何选择
原子操作
原子操作是由编译器来保证的,保证一个线程对数据的操作不会被其他线程打断。
自旋锁
原子操作只能用于临界区只有一个变量的情况,实际应用中,临界区的情况要复杂的多。对于复杂的临界区,Linux 内核提供了多种方法,自旋锁就是其一。
自旋锁的特点就是当一个线程获取了锁之后,其他试图获取这个锁的线程一直在循环等待获取这个锁,直至锁重新可用。由于线程一直在循环获取这个锁,所以会造成 CPU 处理时间的浪费,因此最好将自旋锁用于很快能处理完的临界区。
自旋锁使用时两点注意:
- 自旋锁是不可递归的,以为自选锁内部关了抢占,递归的话最深层级的函数调用尝试获取自旋锁但是由于第一层级函数调用还没释放,所以会一直死自旋下去。
- 线程获取自旋锁之前,要禁止当前处理器上的中断。(事实上,spin_lock() 函数内部会自己做这个)。
小知识:为什么自旋锁调用底层不仅关中断而且关抢占?
关中断是因为中断处理程序有可能重入已获得自旋锁的代码段,造成递归死锁。
但是关了中断,时钟中断也关了,那么时间片无法计算了,不会调度了,为什么还要关抢占?
关抢占是因为虽然时钟中断被关掉,但是 Linux 有两种调度策略,SCHED_FIFO 和 SCHED_RR,FCHED_FIFO 是简单的队列调度,并没有时间片的限制,先来先运行,除非是阻塞或者主动让出(yield),否则一直占用 CPU,即使关中断也不能阻止优先级高的进程被调度运行。
中断处理下半部操作中使用尤其需要小心:
- 下半部处理和进程共享上下文数据时,由于下半部的处理可以抢占进程上下文的代码,所以进程上下文在对共享数据加锁前要禁止下半部的执行,解锁时再允许下半部执行。
- 中断处理程序(上半部)和下半部处理共享数据时,由于中断处理(上半部)可以抢占下半步的执行,所以下半部在对共享数据加锁前要禁止中断处理(上半部),解锁时再允许中断的执行。
- 同一种 tasklet 不能同时运行,所以同类 tasklet 中的共享数据就不需要保护。
- 不同类 tasklet 中共享数据时,其中一个 tasklet 获得锁后,不用禁止其他 tasklet 的执行。
- 同类型或者非同类型的软中断在共享数据时,也不用禁止下半部,因为在同一个处理器上不会有软中断相互抢占的情况。
读写自旋锁
- 读写自旋锁除了和普通自选锁一样有自旋特性外,还有以下特点,读锁之间是共享的,即一个线程持有了读锁之后,其他线程也可以以读的方式持有这个锁。
- 写锁之间是互斥的,即一个县城持有了写锁之后,其他线程不能以读或者写的方式持有这个锁。
- 读写锁之间是互斥的,即一个县城持有了读锁之后,其他线程不能以写的方式持有这个锁。
用法:
DEFINE_RWLOCK(mr_rwlock);
read_lock(&mr_rwlock);
/*critical region, only for read*/
read_unlock(&mr_rwlock);
write_lock(&mr_lock);
/*critical region, only for write*/
write_unlock(&mr_lock);
信号量
信号量也是一种锁,和自旋锁不同的是,线程获取不到信号量的时候,不会像自旋锁一样循环区试图获取锁,而是进入睡眠,直至有信号量释放出来时,才会唤醒睡眠的线程,进入临界区执行。
由于使用信号量时,线程会睡眠,所以等待的过程不会占用 CPU 时间。所以信号量适用于等待时间较长的临界区。
信号量消耗 CPU 时间的地方在于使线程睡眠和唤醒线程。
如果(使线程睡眠 + 唤醒线程)的 CPU 时间 > 线程自旋等待 CPU 时间,那么可以考虑使用自旋锁。
信号量睡眠一般会进入 TASK_INTERRUPTIBLE 状态,因为另一个无法被信号唤醒。
小知识:二值信号量和 mutex 的区别?
区别在于 mutex 只能被统一线程加锁解锁,二值信号量可以被不同线程加锁解锁。
读写信号量
读写信号量和信号量的关系与读写自旋锁和自旋锁的关系差不多。
互斥量
问题:互斥体也是一种可以用于睡眠的锁,嗯?为什么?为什么 spin_lock 不可以它可以?
在 mutex 锁定的临界区中调用 sleep(),那么底层会调用 schedule() 函数去进行进程调度,假设调度的新进程再次执行这段代码,由于 mutex 被之前的进程持有,该进程无法获得该锁,所以在 mutex_lock() 中又会调用 sleep() 去调用 schedule(),会切换到先前的进程,这样先前的进程迟早会 unlock(),不会死锁。所以mutex 中可以睡眠。而 spin_lock 就不一样了,调度的进程尝试获取 spin_lock,失败后会一直自旋,占据 CPU 不放,根本不会切换回去,所以死锁!所以在 spin_lock 的 lock() 函数中会关中断和抢占。
mutex 使用的场景比二值信号量严格,如下:
- mutex 计数值只能为 1,也就是说最多允许一个线程访问临界区。
- 必须在同一个上下文问加锁和解锁。
- 不能递归的上锁和解锁。
- 持有 mutex 时,进程不能退出。
- mutex 不能在中断或者下半部使用,也就是 mutex 只能在进程上下文中使用。
- mutex 只能通过官方 API 管理,不能自己写代码操作它 :)
知识点:中断上下文中为什么不能使用 mutex ?
因为 mutex 可能会引发睡眠或者进程调度,而进程调度是针对进程而言的,进程有 task_struct 结构体,中断上下文确不是一个进程,它没有 task_struct 结构体, 是不可调度的。没有 task_struct 的原因是中断调用频繁,并且处理程序很快,如果为中断维护一个 task_struct,那么对系统的吞吐量有所影响。同理,具有睡眠功能的如信号量也不能再中断上下文中使用。
mutex 和 spin_lock 如何选择:
| 需求 | 建议加锁方法 |
|---|---|
| 低开销加锁 | 优先使用spin_lock |
| 短期锁定 | 优先使用spin_lock |
| 长期加锁 | 优先使用mutex |
| 中断上下文中加锁 | 使用spin_lock |
| 持有者需要睡眠 | 使用mutex |
mutex 比 spin_lock 开销多在进程上下文切换。中断上下文见上面小知识。
完成变量
完成变量名为 completion,就不具体介绍了,我倒是没见用过。
完成变量类似于信号量,当线程完成任务出了临界区之后,使用完成变量唤醒等待线程(更像 condition)。
大内核锁
一个粗粒度锁,Linux 过度到细粒度锁之前版本使用,现在几乎退役?
顺序锁
顺序锁在我的理解是一个部分优化的读写锁。它的特点是,读锁被获取的情况下,写锁仍然可以被获取。
使用顺序锁的读操作在读之前和读之后都会检查顺序锁的序列值。如果前后值不服,这说明在读的过程中有写的操作发生。那么该操作会重新执行一次,直至读前后的序列值是一样的。
do{
/*读之前获取序列值*/
seq = read_seqbegin(&foo);
//do somethin
}while(read_seqretry(&foo, seq); /*顺序锁foo此时的序列值不同则重来
禁止抢占
自旋锁同时关闭中断和抢占,但有时后只需要关闭抢占,我们来看一下它的方法:
| 方法 | 描述 |
|---|---|
| preempt_disable() | 增加抢占计数值,从而禁止内核抢占 |
| preempt_enable() | 减少抢占计算,并当该值将为0时检查和执行被挂起的需要调度的任务 |
| preempt_enable_no_resched() | 激活内核抢占但不再检查任何被挂起的需调度的任务 |
| preempt_count() | 返回抢占计数 |
顺序和屏障
防止编译器优化我们的代码,让我们代码的执行顺序与我们所写的不同,就需要顺序和屏障。
函数如下:
| 方法 | 描述 |
|---|---|
| rmb | 阻止跨越屏障的载入动作发生重排序 |
| read_barrier_depends() | 阻止跨越屏障的具有数据依赖关系的载入动作重排序 |
| wmb() | 阻止跨越屏障的存储动作发生重排序 |
| mb() | 阻止跨越屏障的载入和存储动作重新排序 |
| smp_rmb() | 在SMP上提供rmb()功能,在UP上提供barrier()功能 |
| smp_read_barrier_depends() | 在SMP上提供read_barrier_depends()功能,在UP上提供barrier()功能 |
| smp_wmb() | 在SMP上提供wmb()功能,在UP上提供barrier()功能 |
| smp_mb | 在SMP上提供mb()功能,在UP上提供barrier()功能 |
| barrier | 阻止编译器跨越屏障对载入或存储操作进行优化 |
举例如下:
void thread_worker()
{
a = 3;
mb();
b = 4;
}上述用法就会保证 a 的赋值永远在 b 赋值之前,而不会被编译器优化弄反。在某些情况下,弄反了可能带来难以估量的后果。
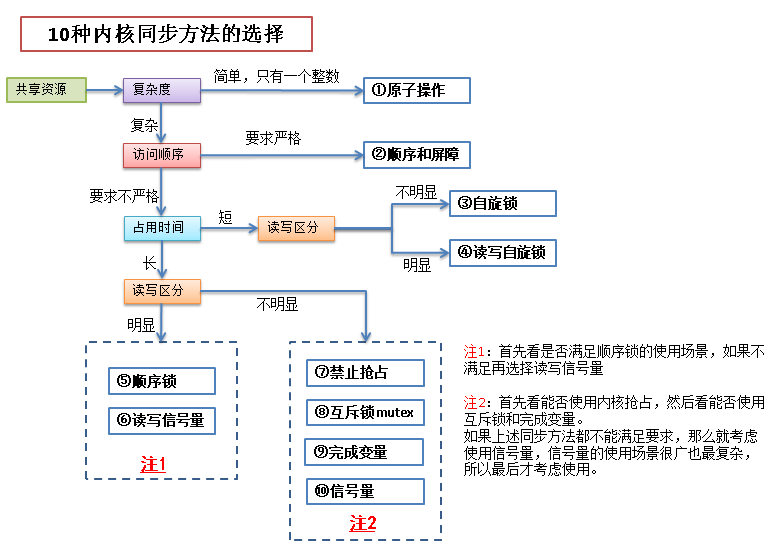
如何选择
对于以上 10 中同步方法,应该如何选择?如图:
参考:《Linux内核设计与实现》读书笔记(十)- 内核同步方法