近日,有越来越多的学者正在探讨机器学习(和深度学习)的局限性,并试图为人工智能的未来探路,纽约大学教授 Gary Marcus 就对深度学习展开了系统性的批判。此前,图灵奖获得者,UCLA 教授 Judea Pearl 题为《Theoretical Impediments to Machine Learning with Seven Sparks from the Causal Revolution》的论文中,作者就已探讨了当前机器学习存在的理论局限性,并给出了面向解决这些问题,来自因果推理的七个启发。Pearl 教授在 NIPS 2017 系列活动中对本文进行了讨论,随后,他也对一些人们关心的问题进行了解答。

论文地址:http://ftp.cs.ucla.edu/pub/stat_ser/r475.pdf
当前的机器学习几乎完全是统计学或黑箱的形式,从而为其性能带来了严重的理论局限性。这样的系统不能推断干预和反思,因此不能作为强人工智能的基础。为了达到人类级别的智能,学习机器需要现实模型(类似于因果推理的模型)的引导。为了展示此类模型的关键性,我将总结展示 7 种当前机器学习系统无法完成的任务,并使用因果推理的工具完成它们。
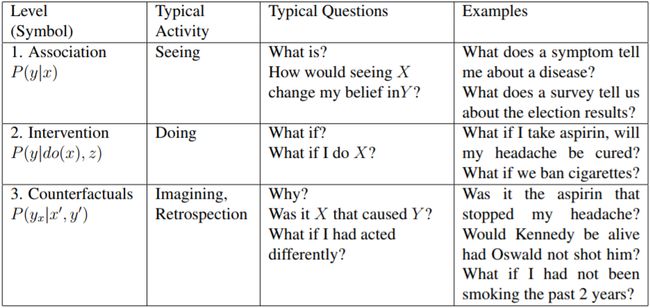
图 1:因果关系的类型
因果推理模型的 7 种特性
考虑以下 5 个问题:
- 给定的疗法在治疗某种疾病上的有效性?
- 是新的税收优惠导致了销量上升吗?
- 每年的医疗费用上升是由于肥胖症人数的增多吗?
- 招聘记录可以证明雇主的性别歧视罪吗?
- 我应该放弃我的工作吗?
这些问题的一般特征是它们关心的都是原因和效应的关系,可以通过诸如「治疗」、「导致」、「由于」、「证明」和「我应该」等词识别出这类关系。这些词在日常语言中很常见,并且我们的社会一直都需要这些问题的答案。然而,直到最近也没有足够好的科学方法对这些问题进行表达,更不用说回答这些问题了。和几何学、机械学、光学或概率论的规律不同,原因和效应的规律曾被认为不适合应用数学方法进行分析。
这种误解有多严重呢?实际上仅几十年前科学家还不能为明显的事实「mud does not cause rain」写下一个数学方程。即使是今天,也只有顶尖的科学社区能写出这样的方程并形式地区分「mud causes rain」和「rain causes mud」。
过去三十年事情已发生巨大变化。一种强大而透明的数学语言已被开发用于处理因果关系,伴随着一套把因果分析转化为数学博弈的工具。这些工具允许我们表达因果问题,用图和代数形式正式编纂我们现有的知识,然后利用我们的数据来估计答案。进而,这警告我们当现有知识或可获得的数据不足以回答我们的问题时,暗示额外的知识或数据源以使问题变的可回答。
我把这种转化称为「因果革命」(Pearl and Mackenzie, 2018, forthcoming),而导致因果革命的数理框架我称之为「结构性因果模型」(SCM)。
SCM 由三部分构成:
- 图模型
- 结构化方程
- 反事实和介入式逻辑
图模型作为表征知识的语言,反事实逻辑帮助表达问题,结构化方程以清晰的语义将前两者关联起来。
接下来介绍 SCM 框架的 7 项最重要的特性,并讨论每项特性对自动化推理做出的独特贡献。
1. 编码因果假设—透明性和可试性
图模型可以用紧凑的格式编码因果假设,同时保留透明性和可试性。其透明性使我们可以了解编码的假设是否可信(科学意义上),以及是否有必要添加其它假设。可试性使我们(作为人类或机器)决定编码的假设是否与可用的数据相容,如果不相容,分辨出需要修改的假设。利用 d-分离(d-separate)的图形标准有助于以上过程的执行,d-分离构成了原因和概率之间的关联。通过 d-分离可以知道,对模型中任意给定的路径模式,哪些依赖关系的模式才是数据中应该存在的(Pearl,1988)。
2. do-calculus 和混杂控制
混杂是从数据中提取因果推理的主要障碍,通过利用一种称为「back-door」的图形标准可以完全地「解混杂」。特别地,为混杂控制选择一个合适的协变量集合的任务已被简化为一种简单的「roadblocks」问题,并可用简单的算法求解。(Pearl,1993)
为了应对「back-door」标准不适用的情况,人们开发了一种符号引擎,称为 do-calculus,只要条件适宜,它可以预测策略干预的效应。每当预测不能由具体的假设确定的时候,会以失败退出(Pearl, 1995; Tian and Pearl, 2002; Shpitser and Pearl, 2008)。
3. 反事实算法
反事实分析处理的是特定个体的行为,以确定清晰的特征集合。例如,假定 Joe 的薪水为 Y=y,他上过 X=x 年的大学,那么 Joe 接受多一年教育的话,他的薪水将会是多少?
在图形表示中使用反事实推理是将因果推理应用于编码科学知识的非常有代表性的研究。每一个结构化方程都决定了每一个反事实语句的真值。因此,我们可以解析地确定关于语句真实性的概率是不是可以从实验或观察研究(或实验加观察)中进行估计(Balke and Pearl, 1994; Pearl, 2000, Chapter 7)。
人们在因果论述中特别感兴趣的是关注「效应的原因」的反事实问题(和「原因的效应」相对)。(Pearl,2015)
4. 调解分析和直接、间接效应的评估
调解分析关心的是将变化从原因传递到效应的机制。对中间机制的检测是生成解释的基础,且必须应用反事实逻辑帮助进行检测。反事实的图形表征使我们能定义直接和间接效应,并确定这些效应可从数据或实验中评估的条件(Robins and Greenland, 1992; Pearl, 2001; VanderWeele, 2015)
5. 外部效度和样本选择偏差
每项实验研究的有效性都需要考虑实验和现实设置的差异。不能期待在某个环境中训练的模型可以在环境改变的时候保持高性能,除非变化是局域的、可识别的。上面讨论的 do-calculus 提供了完整的方法论用于克服这种偏差来源。它可以用于重新调整学习策略、规避环境变化,以及控制由非代表性样本带来的偏差(Bareinboim and Pearl, 2016)。
6. 数据丢失
数据丢失的问题困扰着实验科学的所有领域。回答者不会在调查问卷上填写所有的条目,传感器无法捕捉环境中的所有变化,以及病人经常不知为何从临床研究中突然退出。对于这个问题,大量的文献致力于统计分析的黑箱模型范式。使用缺失过程的因果模型,我们可以形式化从不完整数据中恢复因果和概率的关系的条件,并且只要条件被满足,就可以生成对所需关系的一致性估计(Mohan and Pearl, 2017)。
7. 挖掘因果关系
上述的 d-分离标准使我们能检测和列举给定因果模型的可测试推断。这为利用不精确的假设、和数据相容的模型集合进行推理提供了可能,并可以对模型集合进行紧凑的表征。人们已在特定的情景中做过系统化的研究,可以显著地精简紧凑模型的集合,从而可以直接从该集合中评估因果问询。
NIPS 2017 研讨会 Q&A
我在一个关于机器学习与因果性的研讨会(长滩 NIPS 2017 会议之后)上发表了讲话。随后我就现场若干个问题作了回应。我希望从中你可以发现与博客主题相关的问题和回答。
一些人也想拷贝我的 PPT,下面的链接即是,并附上论文:
- http://ftp.cs.ucla.edu/pub/stat_ser/r475.pdf
- NIPS 17 – What If? Workshop Slides (PDF)(http://causality.cs.ucla.edu/blog/wp-content/uploads/2017/12/nips-dec2017-bw.pdf)
- NIPS 17 – What If? Workshop Slides (PPT [zipped])(http://causality.cs.ucla.edu/blog/wp-content/uploads/2017/12/nips-dec2017-bw.pdf)
问题 1:「因果革命」是什么意思?
回答:「革命」是诗意用法,以总结 Gary King 的奇迹般的发现:「在过去几十年里,对于因果推断的了解比以前所有历史记载的总和还要多」(参见 Morgan 和 Winship 合著的书的封面,2015)。三十年之前,我们还无法为「Mud does not
cause Rain」编写一个公式;现在,我们可以公式化和评估每一个因果或反事实陈述。
问题 2:由图模型产生的评估与由潜在结果的方法产生的评估相同吗?
回答:是的,假设两种方法开始于相同的假设。图方法(graphical approach)中的假设在图中被展示,而潜在结果方法(potential outcome approach)中的假设则通过使用反事实词汇被审查者单独表达。
问题 3:把潜在的结果归因于表格个体单元的方法似乎完全不同于图方法中所使用的方法。它们的区别是什么?
回答:只在有可条件忽略的特定假设成立的情况下,归因才有效。表格本身并未向我们展示假设是什么,其意义是什么?为了搞明白其意义,我们需要一个图,因为没有人可在头脑中处理这些假设。流程上的明显差异反映了对假设可见的坚持(在图框架中),而不是使其隐藏。
问题 4:有人说经济学家并不使用图,因为其问题不同,并且也没能力建模整个经济。你同意这种解释吗?
回答:不同意!从数学上讲,经济问题与流行病学家(或其他科学家)面临的问题并无不同,对于后者来讲,图模型已经成为了第二语言。此外,流行病学家从未抱怨图迫使其建模整个人体解剖结构。(一些)经济学家中的图规避(graph-avoidance)是一种文化现象,让人联想到 17 世纪意大利教会天文学家避开望远镜。底线:流行病学家可以判断他们的假设的合理性——规避掉图的经济学家做不到(我提供给他们很多公开证明的机会,并且我不责怪他们保持沉默;没有外援,这个问题无法被处理)。
问题 5:深度学习不仅仅是盛赞曲线拟合?毕竟,曲线拟合的目标是最大化拟合,同时深度学习中很多努力也在最小化过拟合。
回答:在你的学习策略中不管你使用何种技巧来最小化过拟合或其他问题,你依然在优化已观察数据的一些属性,同时不涉及数据之外的世界。这使你立即回到因果关系阶梯的第一阶段,其中包含了第一阶段要求的所有限制。
原文链接:http://causality.cs.ucla.edu/blog/index.php/2017/12/19/nips-2017-qa-follow-up/