深度学习之风格迁移(一)——Neural Style(Gatys)
本文介绍一个酷炫的深度学习应用:风格迁移。作者Gatys等人在2015年提出基于神经网络的风格迁移算法[1],随后发表在CVPR 2016上[2]。斯坦福大学的Justin Johnson(cs231n课程的主讲人之一)给出了Torch实现neural-style([3])。
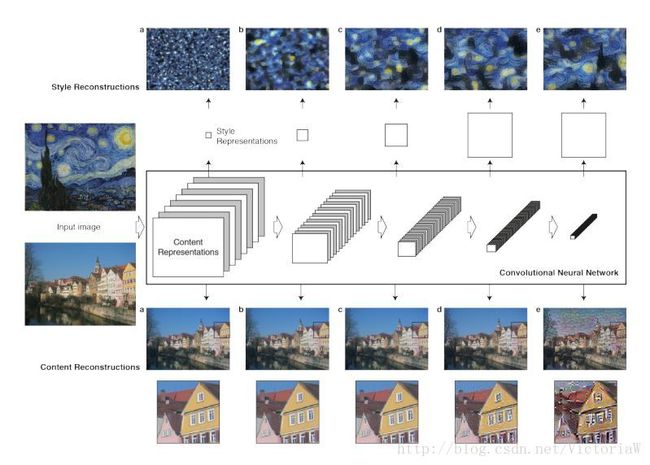
内容重构content reconstruction
给定一张图片 p⃗ 和训练好的卷积网络,那么在每层可以得到多个feature map,个数取决于每层滤波器的个数 Nl 。我们把个feature map向量化,得到大小为 Ml 的向量。把每一层的 Nl 个特征向量保存到矩阵 Fl∈ℝNl×Ml 中,其元素 Flij 表示第 l 层的第 i 个滤波器在位置 j 上的激活响应。
现在指定一层的特征表示,希望生成一张新的图片 x⃗ 使其在该层的特征表示 Pl 等于原特征表示 Fl (内容匹配)。定义损失函数如下:
文中是通过把 x⃗ 初始化为白噪声图片,然后通过反向传播算法进行优化得到的。其实生成的 x⃗ 可以认为是该层特征向量包含的信息的可视化。
高层的特征映射只包含了图像的内容(高层次)以及图像的空间结构信息,忽略了颜色、纹理及形状等信息。
风格重构style reconstruction
本文用Gram矩阵作为风格图片的风格。
Gram矩阵包含了图片纹理信息以及颜色信息,其定义如下:
于是 Gl∈ℝNl×Nl ,称为风格表示style representation。现在希望通过反向传播算法优化白噪声图片,使其风格特征和原风格特征一致。给定风格图片 a⃗ ,希望生成的图片为 x⃗ ,对应第 l 层的Gram矩阵分别为 Al 和 Gl ,定义该层损失函数如下:
总损失函数为
ωl 是每层的权重,文章中取style层对应的权重是style层数目的倒数,其他层权重为0。
看到到这里不得不问两个问题:为什么Gram矩阵可以表示图片的风格?是否有其他方法表示图片风格?
风格迁移
为了生成融合图片 a⃗ 的风格和图片 p⃗ 的内容的图片 x⃗ ,同时最小化图片 x⃗ 与 p⃗ 的某层内容表示之间的差距和 x⃗ 与 a⃗ 的多层风格表示之间的差距。损失函数为
实验
网络模型采用19层的VGG网络。首先以内容图片作为输入,得到内容层的特征矩阵,作为内容目标;以风格图片作为输入,得到风格层的Gram矩阵,作为风格目标。在VGG中添加内容损失层以及风格损失层,以白噪声图片作为输入,通过反向传播计算损失函数关于输入的梯度,然后更新图片。这个过程不同于一般的训练过程:并不更新中间层的参数,这是Deconvolution操作。
Johnson的复现实验[3]指定输入图片的大小默认为512*512,这个时候需要的内容大概是4.5G(通过监控实验过程中消耗的内存百分比得到的)。我的GPU内存只有3G,所以如果在GPU上运行程序,会出现内存不够的错误。所以改用较慢的CPU,为一幅图片进行风格迁移花了大概50mins。
算法存在的问题
本文算法虽然生成的图片看起来很不错,但是仍存在以下问题:
- 由于每次迁移都要对网络进行训练,速度是非常慢的,无法实现实时迁移;
- 应用在照片上进行风格迁移,会出现失真的情况;
针对第一个问题,Johnson提出的fast-neural -style在本文网络模型前增加一个转换网络,转换网络的输入是内容图片,输出是风格迁移图片。而本文的网络模型称为损失网络,用于计算损失。为每个风格图片训练一个网络,这样在测试时,给定一张内容图片,只需要一次前向过程即可得到生成图片。关于此改进的详细信息,请查看博客 深度学习之风格迁移(二)——Fast Neural Style(Johnson) 。
这对第二个问题,康奈尔大学和Adobe公司合作推出了一篇文章:Deep Photo Style Transfer,通过对损失函数进行改进,使得可以在照片之间进行风格迁移且不失真。具体请看博客 深度学习之风格迁移(三)——Deep Photo Style Transfer(Fujun Luan) 。
参考
[1] A Neural Algorithm of Artistic Style. Leon A. Gatys, Alexander S. Ecker, and Matthias Bethge.
[2] Image Style Transfer Using Convolutional Neural Networks. Leon A. Gatys, Alexander S. Ecker, and Matthias Bethge. CVPR 2016.
[3] neural-style in Github by Johnson.