PyTorch动态神经网络(莫烦)上
一 简述
1.神经网络简述(以图片为例)
对于和给定的一张猫的图片,相当于一个激励,在每个神经网络层中有部分的神经元被激活(发),最后会得出一个结果,比如是狗,知道是错的,再反向传(感觉用词不太准确),之前被激发的神经元不会像之前那么活跃,但同时会有新的神经元被激活,其实相当于修改参数,多次重复后,就会得到一个比较完美的结果,识别为猫。
2.神经网络:梯度下降(向着梯度降低最快的方向走到梯度最小的地方)
优化问题:Newton's method , Least Squares method ,GradientDesent
全部最优,局部最优,与起点位置有关系
3.PyTorch(动态图)
边建数据边建流程图
优点以及安装详见 https://blog.csdn.net/xiangxianghehe/article/details/80103095

第二部分
1.Numpy 和 Torch 对比
numpy 矩阵计算 pytorch是tensor(张量)的形式,可以等同于神经网络里的numpy
(1)tensor 和 numpy 的转换

(2)各种运算(详见官网 https://pytorch.org/docs/stable/torch.html 全)
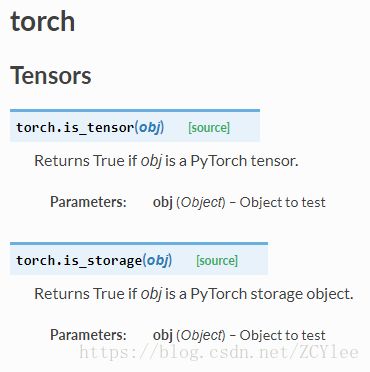
[1]abs绝对值

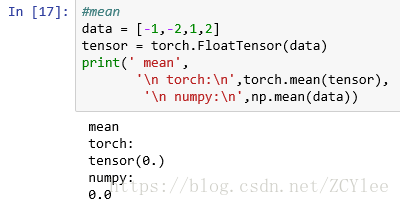
[2]mean 均值(直接换后面的函数.sin,.cos 都可以 )
2.Variable变量
![]()
详见 https://blog.csdn.net/quincuntial/article/details/78023298
Variable变量是将tensor中的数据来搭建图的,当requires_grad = True 时,对梯度进行跟踪,这样当计算误差时即可按所建的图反向走回去,不断减小误差,从而进行更好的拟合。
3.激励函数
![]()
详见 https://blog.csdn.net/quincuntial/article/details/78023838 (源代码有错的地方)
激活函数的选择:一般的层比较少的,可以随便选;卷积神经网络:relu;循环神经网络:relu,tanh
第三部分
1.回归函数
https://blog.csdn.net/quincuntial/article/details/78033097
Net有重复定义,删掉就好,它是对上面的print的一个输出;以及有个range写成了xrange

[1] torch.unsqueeze(torch.linespace(-1,1,100),dim=1)
作用:把一维数据变成二维,torch只能处理二维的数据 比如:[1,2,3,4]--->[[1,2,3,4]]
[2] plt.scatter 作用:画散点图
官方模块
# 定义pytorch网络# 构建网络
net = Net(1, 10, 1) #1:一个x对应一个值 10:有10个隐藏层 1:和x对应的一个输出y
#print (net)
# 选择优化方法
optimizer = torch.optim.SGD(net.parameters(), lr = 0.5) #0.5学习率<1 有的时候太大也不好
# 选择损失函数
loss_func = torch.nn.MSELoss()#用均方差处理回归问题
plt.ion() #实时打印
# 训练
for i in range(100): #训练100步
# 对x进行预测
prediction = net(x)
# 计算损失
loss = loss_func(prediction, y)
# 每次迭代清空上一次的梯度
optimizer.zero_grad() #优化神经网络中的参数,将他们的梯度初始化为0
# 反向传播
loss.backward()
# 更新梯度
optimizer.step()
if i % 5 == 0: #每五步打印一次
plt.cla()
plt.scatter(x.data.numpy(), y.data.numpy())
plt.plot(x.data.numpy(), prediction.data.numpy(), 'r-', lw = 5)
plt.text(0.5, 0, 'Loss=%.4f' % loss.data[0], fontdict={'size': 10, 'color': 'red'})
plt.pause(0.1)
plt.ioff()
plt.show()
2.回归问题
详见 https://blog.csdn.net/quincuntial/article/details/78034428
![]()
# 定义网络
net = Net( 2, 10,2)
#2:输入点的坐标有两个参数横纵 10:10个神经元 2:两个输出 0/1
#二分类 [0,1]默认为1类 [1,0]默认为 class0 定义损失函数
loss_func = torch.nn.CrossEntropyLoss() #计算概率
#对于三分类的问题 可能输出[0.1,0.2,0.7]=1 那么该点可能为第三类3.快速搭建法
详见 https://blog.csdn.net/quincuntial/article/details/78044579
net = torch.nn.Sequential(
torch.nn.Linear(2, 10),
torch.nn.ReLU(),
torch.nn.Linear(10, 2))
4.保存和提取
https://blog.csdn.net/quincuntial/article/details/78045036
推荐保存网络参数
5.批训练
https://blog.csdn.net/quincuntial/article/details/78045803
对于大批量数据,可拆分成小批量进行训练,
在pycharm中复制源码有错误,但是在 jupyter notebook中结果是对的
batch_size = 5 shuffle = True

shuffle = False

这乱七八糟的结果有什么用 emmmm 等我懂了再补上
6.加速神经网络训练
对于复杂的神经网络,处理数据,训练想让他快起来,就要使用以下方法
SGD,Momentum,NAG,Adagrad,Adadelte,Rmsprop
(1)最基础的是SGD(stochastic gradient descent)(是几个方法中最慢的)

缺点:虽然不能整体很好的反映,但是小批量的训练误差不会太大,也不会丢失太大的准确率,并且速度加快很多
(2)其他方法主要是在神经网络更新参数上做了手脚
[1] Momentum (提供下坡)
W += -Learning rate * dx (dx 校正值)
数学表达式:m = b1*m - Learning rate *dx
W += m
[2] AdaGrad (一双不好走的鞋,直着向下)
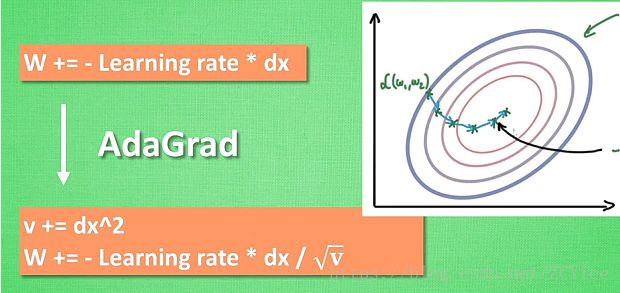
[3] RMSProp

[4] Adam(大多数时候使用该方法可以很好的收敛)

7.优化器
对上述几种方法的性能比较
https://blog.csdn.net/quincuntial/article/details/78055971
第四部分 卷积神经网络
应用:图像识别,视频分析,自然语言处理
1.卷积神经网络的运作(以图片为例)
卷积:不是对单独像素区域做处理,而是对于图像的每一小块像素区域做处理,这样加强了图片信息的连续性,使得神经网络可以看到图形而不是单独的一个点,同时加强了神经网络对图片的理解。
总的来说卷积神经网络有一个批量过滤器,持续不断地在图像上滚动收集信息,每次收集来的信息只是一小块区域的信息,把收集来的信息进行整理,这时候神经网络可以看到一些边缘图像信息,然后再以同样的步骤用类似的批量过滤器扫过已经得到的边缘信息,总结出更高层的结构,可能这个时候就能画出眼睛鼻子等,再经过一次过滤,脸部信息就会被总结出来,最后再将这些信息套入几个简单的全连接层进行分类,这样就能得到输入的图片被分为哪一类了。
图片是有长宽高的,高指的是颜色信息,过滤器不断地扫描像素块收集信息,即每一次的卷积,会将长宽压缩,增加高度,经过不断卷积,长宽不断减小,高度不断增加,这样就对图像有了更深的理解,嵌在普通神经层上就可以分类了。
研究发现,每次卷积时,神经层会无意的丢失一些边缘信息,这时Pooling 可以很好的解决这个问题,卷积时不压缩长宽,尽量保留信息,压缩的工作就交给迟化Pooling,这样可以很有效的提高准确率,这样就可以搭建自己的神经网络了。
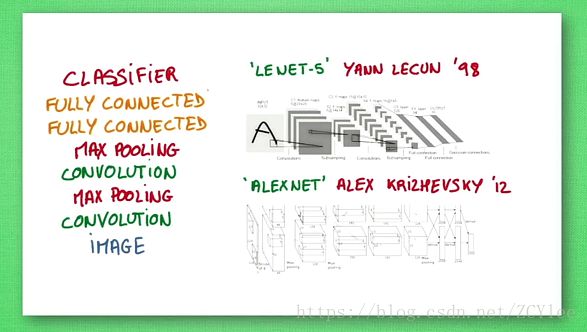
针对图像分类的卷积神经网络的基本搭建过程(从下到上)
2.CNN卷积神经网络
import torch
import torchvision
import torch.nn as nn
import torch.utils.data as Data
import matplotlib.pyplot as plt
from torch.autograd import Variable
# 超参数定义
# EPOCH = 1 #定义太大的话CPU计算时间会太长 train the training data n times
LR = 0.01
BATCH_SIZE = 50
DOWNLOAD_MNIST = False #没下载好的时候是True 下载好了改成 False
# 下载MNIST数据集
train_data = torchvision.datasets.MNIST(
root = './mnist/',
# 是否是训练数据
train = True,
# 数据变换(0, 255) -> (0, 1) 把下载的数据改成TENSOR
transform = torchvision.transforms.ToTensor(),
# 是否下载MNIST数据
download = DOWNLOAD_MNIST
)
test_data = torchvision.datasets.MNIST(
root = './mnist/',
# 是否是训练数据
train = False,
# 数据变换(0, 255) -> (0, 1)
transform = torchvision.transforms.ToTensor(),
# 是否下载MNIST数据
download = DOWNLOAD_MNIST
)
# 查看图像
plt.imshow(train_data.train_data[0].numpy(), cmap = 'gray')
plt.title('%i' % train_data.train_labels[0])
plt.show()
plt.imshow(test_data.test_data[0].numpy(), cmap = 'gray')
plt.title('%i' % test_data.test_labels[0])
plt.show()
# 数据加载
train_loader = Data.DataLoader(dataset = train_data, batch_size = BATCH_SIZE, shuffle = True, num_workers = 2)
#test_x = Variable(torch.unsqueeze(test_data.test_data,dim=1),volatile=True).type(torch.FloatTensor)[:2000]/255.
#test_y = test_data.test_lable[:2000] #测试只取了前两千个 为了节省时间 这里和莫烦视频里的不一样
test_loader = Data.DataLoader(dataset = test_data, batch_size = BATCH_SIZE, shuffle = False, num_workers = 1)
# 定义卷积神经网络 (重点)
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.conv1 = nn.Sequential( #卷积层
nn.Conv2d( #(1,28,28) #卷积层相当于一个三维过滤器(有高度)(高度用来提取的特征属性)
in_channels = 1, #图片有多少个层 黑白图:1层 彩图:RGB 3层
out_channels = 16, #16个过滤器 同时提取16个特征
kernel_size = 5, #过滤器的大小 5*5
stride = 1, #每隔一步跳一下
padding = 2 #扫到边缘过滤器超出范围时,多加一圈为0的信息
#padding 的值的计算 if stride=1,padding=(kernel_size-1)/2=(5-1)/2=2
),#-->(16,28,28)
nn.ReLU(), #-->(16,28,28) #神经网络
nn.MaxPool2d(kernel_size = 2)#池化层
#-->(16,14,14) #使用了一个2*2的过滤器,选择2*2区域中的最大值,相当于把原始图片裁剪了一下,
#换成长宽变小,高度不变
)
# conv1输出为(16, 14, 14)
self.conv2 = nn.Sequential(
nn.Conv2d(16, 32, 5, 1, 2), #-->(32,14,14)
nn.ReLU(), #-->(32,14,14)
nn.MaxPool2d(2) #-->(32,7,7)
#Pooling 有两种MaxPool2d,AvgPool2d(平均值) 一般选MAX的
)
# conv2输出为(32, 7, 7)
self.output = nn.Linear(32 * 7 * 7, 10)
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x) #(batch,32,7,7) 考虑了batch
x = x.view(x.size(0), -1) #(batch,32*7*7)
prediction = self.output(x) #这样就有了上面的参数值
return prediction
cnn = CNN()
print (cnn)
# 定义优化器
optimizer = torch.optim.Adam(cnn.parameters(), lr = LR, betas= (0.9, 0.999))
# 定义损失函数
loss_func = nn.CrossEntropyLoss()
# 训练
for epoch in range(EPOCH):
for step, (x, y) in enumerate(train_loader):
x_var = Variable(x)
y_var = Variable(y)
prediction = cnn(x_var)
loss = loss_func(prediction, y_var)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if step % 50 == 0: #这里出现了一些问题,编译不过,这部分和视频里的也不一样,不会改了,有大神的话,可以改改,评论一下告诉大家哪里错了
correct = 0.0
for step_test, (test_x, test_y) in enumerate(test_loader):
test_x = Variable(test_x)
test_output = cnn(test_x)
pred_y = torch.max(test_output, 1)[1].data.squeeze()
correct += sum(pred_y == test_y)
accuracy = correct / test_data.test_data.size(0)
print ('Epoch: ', epoch, '| train loss: %.4f' % loss.data[0], '| accuracy: ', accuracy)结果输出:计算一下有百分之多少的图片预测对了
最后的话也可以放前10个测试数据进去,看预测结果对不对
#print 10 predictions from test data
test_output = cnn(test_x[:10])
pred_y = torch.max(test_output,1)[1].data.numpy().squeeze()
print(pred_y,'prediction number')
print(test_y[:10].numpy(),'real number')