大数据视觉智能实践及医学影像智能诊断探索(讲座精华笔记)

一、视觉智能实践
阿里团队主要专注云上的智能视觉技术。
人工智能曾经过两次繁荣,现在是它的第三次繁荣,主要原因有:一是以深度学习技术为代表的技术的迅速发展,尤其是在图象领域取得了重大的突破;二是有强大的计算能力;三是数据越来越多。正因为有了数据计算能力和算法,可以在更多的方面解决更多商业问题。
阿里巴巴在视觉智能实践的探索体现在如下四个方面。
1.电商搜索
目前电商搜索是一个比较成熟的产品,现在已经开始大规模的部署。拍立淘的目标是希望在电商搜索上,提供除了文字的另外一种搜索,如探索视频广告和视觉诊断。因为有深度学习快速的发展,电商环境下的图象搜索已经取得了重大的突破,几乎实现了所见即所得的效果,网上已经能够搜到相关的资料。
2.城市之眼
城市之眼的目标是希望对城市里面大量摄像头的分析,为我们的交通、安全提供更好的智能决策。
目标检测识别需要一些强大的计算、系统的支持,以及对视频数据结构化以后,做的一些搜索和挖掘。
交通流量识别分析在实际中遇到的挑战还是非常多的。如小目标怎么办?车辆如果远处有遮挡怎么办?枪机通常做得很好,球机行不行?还有就是黄色车牌的识别,数据识别少怎么办?阿里团队在做这个项目中从算法到数据都遇到了一系列的问题,最后阿里团队发明了一种新的网络,对小目标、遮挡目标、模糊的目标都取得了显著的效果,最近在非常有挑战性的KITTI数据库上车辆检测取得了第一名的成绩。阿里采用的手段是利用最新的对抗网络的方法,通过生成大量的假车牌,然后通过这些大量的假车牌训练车牌识别分析器,最终实现车牌的识别率能够提升10%以上。
从计算上来说,对整个城市上万个摄像头进行分析,计算量非常大。但由于有阿里云、大批量计算平台的支持,通过对视频数据结构化,可以实现对全网视频数据大范围搜索。如通过车辆的属性和车牌,在视频数据中进行搜索,可以追查肇事车辆的逃逸。
如果把视频数据结构化以后,还可以通过分析一段时间交通流量对红绿灯进行调控,来优化我们的交通效率。
3.视频广告
第一个方面的探索就是希望能够在视频中找到一个合适的位置,把广告无缝嵌入进去,并且不影响大家的观看体验。

第二个方面希望通过对视频内容的分析,嵌入合适的符合这个场景的广告。
第三个方面是智能广告设计,通过机器学习的手段使得广告海报的生成更加便捷。用户能够通过简单的画直线和方框,生成一幅跟人工几乎可以相媲美的广告海报。
4.视觉诊断
视觉诊断包含两个部分,一个是诊断机器,一个诊断生物。
传统的工业诊断方法是人拿工具到现场检查,诊断机器的目标是通过视觉分析的手段能够代替人工对机器的检查。通过现场拍摄录像,通过视觉分析的手段,能够自动的诊断出机器的故障。
诊断生物就是医学影象智能诊断。
阿里在娱乐、交通、安防、设计和制造领域取得了一系列的进展,下面介绍视觉智能算法应用到医疗影象领域,为医疗带来的改变。
二、医学影像智能诊断探索
阿里在4月份的时候在深圳发布了ET医疗大脑,即阿里基于影像云的服务,提供医学影像的存储、计算和医学影像智能诊断服务。
1.医学影像数据
常见的医学影像数据有如下几种:从早期的X线,到后来的CT,超声,核磁共振(MRI),到现在的正电子发射计算机断层显像(PET-CT)。各种设备不断出现,对病灶的观察越来越精确,已成为临床诊断最重要的依据之一。
医学影像数据数量增长非常迅速,成为了真正意义上的大数据:一是数据种类多,且新的成像方式还在不断涌现。二是数据增长快,麦肯锡的数据显示,2020年医疗数据将达35ZB,为2009年的44倍,其中医学影像数据占绝大部分。三是数据体量大,一家大型医院历史影像数据量为50-200T左右,每年新增20T-50T左右。四是价值密度低,LUNA16数据库CT影像数据111G,只包含1186个结节信息。
2.影像智能诊断的迫切需求
与数据快速增长相对应的,是不满足需求的诊断方式。现有的医学影像方法主要靠医生人工读片,由于有经验的影像科医生培养周期长,加上优秀的资源分布极不均衡,导致患者预约拍片时间长、以及拍片后的等待时间长。由于医生的工作量大,以CT为例,一个医生一天要看上万张影像,精神高度集中,容易疲劳,人工误差不可避免。为了缓解医疗资源紧张,有的公司开发了辅助诊断系统,但是这些辅助系统大多是事先创造一套规则,程序根据规则对影像进行处理,由于规则难以穷尽,这些系统应用到现实复杂的环境中通常准确率不高。而且这些辅助系统增加了医生的使用难度,实际使用效果不理想。
海量的医学影像数据,迫切的现实需求,高效的图像识别算法,加上强大的计算能力,需求、数据、算法、计算等因素综合在一起,为医学影像的智能诊断带来了难得的历史机遇。
一旦智能诊断成为现实,其相比原有的诊断方式的优势是非常明显的。由于强大的云计算和大数据的支持,基于深度学习的智能诊断可以短时间内快速达到普通影像科医生的水平,并且诊断过程可以在瞬间完成,一旦完成训练,“智能诊断服务”可以快速复制,边际成本非常低。
3.CT影像肺结节智能检测的实践探索
以CT影像肺结节检测为例介绍在医学影像智能诊断方面的一些探索。
这里是一个肺部CT扫描序列的片段,红色圆圈标注的是一个肺结节。智能检测的目标是设计深度学习算法让计算机自动从CT扫描序列中自动找出肺结节的位置,估计肺结节位置和大小。
问题分析:
这个问题的存在一系列的挑战:1是结节模态多,不像人脸、行人等目标有相对固定的模态。2是早期结节小,早期的肺结节通常小于10毫米。3是标注样本少,由于医学影像的标注成本高,常见的数据集非常少,数据集的数量也很少。我们期待计算机可以把有问题的结节都找出来,同时误报比较少。这样才能降低医生的工作量。
实现步骤:
基于深度学习的方法比较有效的克服了上述挑战,其主要步骤有:肺部区域提取、肺结节分割和肺结节分类。

使用图像分割算法生成肺部区域图,然后根据肺部区域图生成肺部图像。利用肺部分割生成的肺部区域图像,加上结节标注信息生成结节区域图像,训练基于全卷积神经网络的肺结节分割器,然后对图像做肺结节分割,得到疑似肺结节区域。找到疑似肺结节后,使用3D卷积神经网络对肺结节进行分类,得到真正肺结节的位置和置信度。
具体实现:
肺部提取采用传统的图像处理算法加上一些规则虽然也能得到不错的效果,但是在实验过程中发现,针对某个数据集设定的规则,在别的数据集上总是效果不佳。
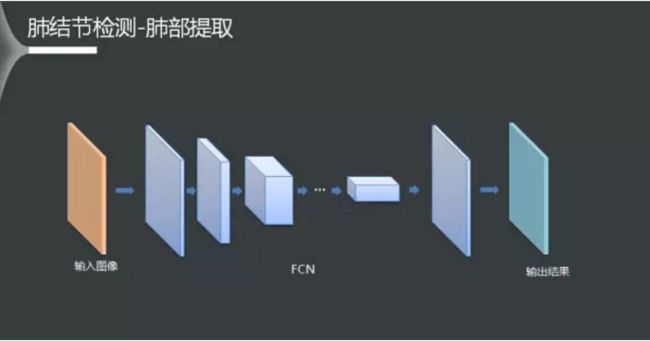
这里采用了FCN全卷积网络,同时采用别的大数据集训练的模型作为预训练模型,训练了一个16层的网络(13个卷积层,3个反卷积层)。模型测试的效果表明,基于深度学习的方法有着更为鲁棒的效果。
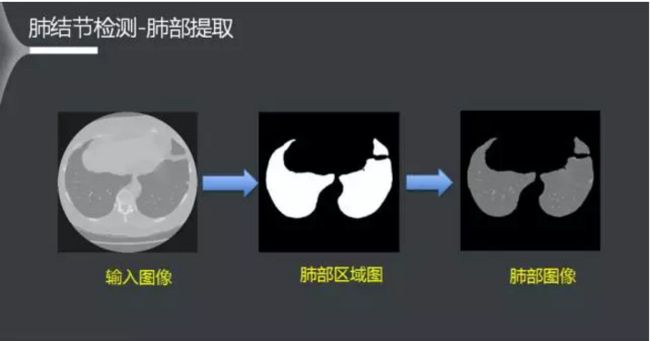
得到肺部区域图后,需要在肺部图像中找出肺结节的位置。由于早期的肺结节比较小,使用常见的网络做影像分割通常对小目标容易漏检。
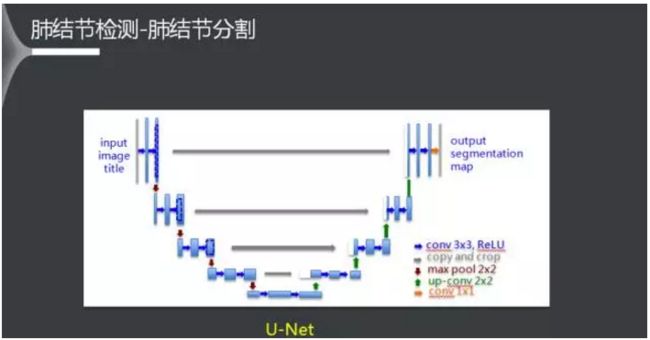
这里采用了U-Net网络模型。因模型长得像个巨大的U,故取名U-Net。它的显著特征是在上采样过程中把下采样过程中生成对应特征图拿过来组合在一起,这样在最终生成的特征图中既包含高层的抽象特征,也包含低层的细节特征,能同时对影像中的大小目标进行检测。同时,由于这是正负样本严重不均衡问题,训练的loss函数设计、训练策略都需要特殊的考虑。
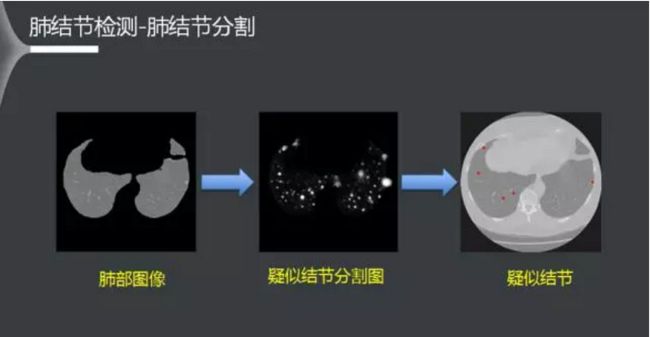
对肺部图像做U-Net分割后,得到疑似肺结节分割图像。图像明暗程度代表了肺结节出现的概率,可以看出,真正结节所在的位置为白色。然后对分割图做二值化、提取连通块等后处理,得到疑似结节的位置。从上图中可以看出得到了五个疑似结节。
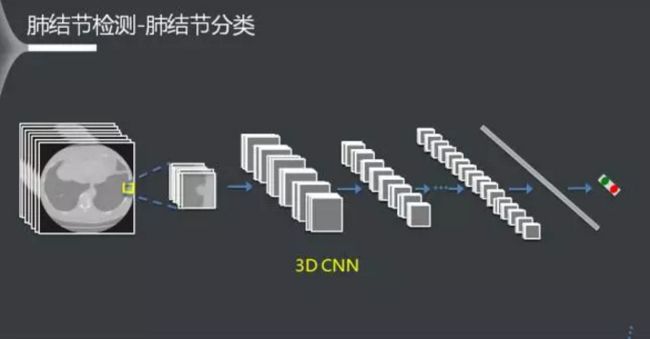
最后是疑似结节分类。对每个疑似结节,从其相邻多帧切片中提取一个影像数据块,使用一个3DCNN网络中对其分类。由于3D网络充分学习到了肺结节内在的3维形状结构,可以获得比2D更好的结果。
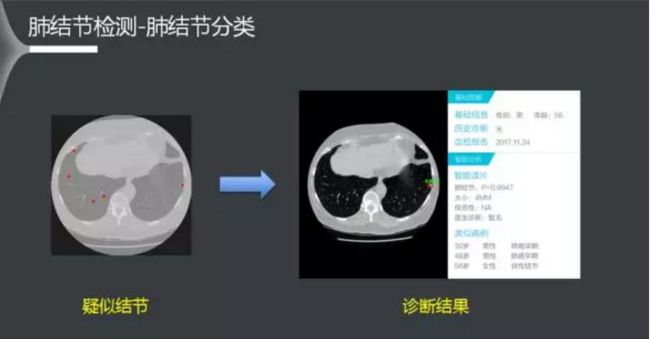
上图是得到的最终结果。左图在肺结节分割环境中找到了5个肺结节,经过肺结节分类后,找到了那个真正肺结节的位置。
以上是肺结节检测一个初步的探索,如果要真正应用于实践,成为一个真正的产品,无论是算法、数据、计算,还是商业都还有很多工作要做。