20 | 幻读是什么,幻读有什么问题?
InnoDB 的默认事务隔离级别是可重复读--rr
-
- 快照读(snapshot read)
单纯的select操作,不包括上述 select ... lock in share mode, select ... for update。
Read Committed隔离级别:每次select都生成一个快照读。
Read Repeatable隔离级别:开启事务后第一个select语句才是快照读的地方,而不是一开启事务就快照读。
快照读的实现方式:undolog和多版本并发控制MVCC
- 快照读(snapshot read)
2.当前读(current read)
当前读, 读取的是最新版本, 并且对读取的记录加锁, 阻塞其他事务同时改动相同记录,避免出现安全问题。
select ... lock in share mode
select ... for update
insert,update,delete
在RR级别下,当前读的实现方式:next-key锁(行记录锁+Gap间隙锁)幻读是什么?

这里,我需要对“幻读”做一个说明:- 1.在可重复读隔离级别下,普通的查询是快照读,是不会看到别的事务插入的数据的。因此,幻读在“当前读”下才会出现。
2.上面 session B 的修改结果,被 session A 之后的 select 语句用“当前读”看到,不能称为幻读。幻读仅专指“新插入的行”。
如何解决幻读?
现在你知道了,产生幻读的原因是,行锁只能锁住行,但是新插入记录这个动作,要更新的是记录之间的“间隙”。因此,为了解决幻读问题,InnoDB 只好引入新的锁,也就是间隙锁 (Gap Lock)。
顾名思义,间隙锁,锁的就是两个值之间的空隙。比如文章开头的表 t,初始化插入了 6 个记录,这就产生了 7 个间隙。这样就确保了无法再插入新的记录。
间隙锁和行锁合称 next-key lock,每个 next-key lock 是前开后闭区间。
也就是说,我们的表 t 初始化以后,如果用 select from t for update 要把整个表所有记录锁起来,就形成了 7 个 next-key lock,分别是 (-∞,0]、(0,5]、(5,10]、(10,15]、(15,20]、(20, 25]、(25, +supremum]。
间隙锁和 next-key lock 的引入,帮我们解决了幻读的问题,但同时也带来了一些“困扰”。
如果我们的项目中需要解决幻读的话也有两个办法:
1.使用串行化读的隔离级别
2.mysql的innodb引擎--间隙锁和 next-key lock 解决了幻读的问题
---21 | 为什么我只改一行的语句,锁这么多?
我总结的加锁规则里面,包含了两个“原则”、两个“优化”和一个“bug”。
原则 1:加锁的基本单位是 next-key lock。希望你还记得,next-key lock 是前开后闭区间。
原则 2:查找过程中访问到的对象才会加锁。
优化 1:索引上的等值查询,给唯一索引加锁的时候,next-key lock 退化为行锁。
优化 2:索引上的等值查询,向右遍历时且最后一个值不满足等值条件的时候,next-key lock 退化为间隙锁。
一个 bug:唯一索引上的范围查询会访问到不满足条件的第一个值为止。
22 | MySQL有哪些“饮鸩止渴”提高性能的方法?
第一种方法:先处理掉那些占着连接但是不工作的线程。
max_connections 的计算,不是看谁在 running,是只要连着就占用一个计数位置。对于那些不需要保持的连接,我们可以通过 kill connection 主动踢掉。这个行为跟事先设置 wait_timeout 的效果是一样的。设置 wait_timeout 参数表示的是,一个线程空闲 wait_timeout 这么多秒之后,就会被 MySQL 直接断开连接。
第二种方法:减少连接过程的消耗。
慢查询性能问题
在 MySQL 中,会引发性能问题的慢查询,大体有以下三种可能:
索引没有设计好;
SQL 语句没写好;
MySQL 选错了索引。
---
23 | MySQL是怎么保证数据不丢的?
binlog 的写入机制
其实,binlog 的写入逻辑比较简单:事务执行过程中,先把日志写到 binlog cache,事务提交的时候,再把 binlog cache 写到 binlog 文件中。
一个事务的 binlog 是不能被拆开的,因此不论这个事务多大,也要确保一次性写入。这就涉及到了 binlog cache 的保存问题。
系统给 binlog cache 分配了一片内存,每个线程一个,参数 binlog_cache_size 用于控制单个线程内 binlog cache 所占内存的大小。如果超过了这个参数规定的大小,就要暂存到磁盘。
redo log 的写入机制

这三种状态分别是:
1.存在 redo log buffer 中,物理上是在 MySQL 进程内存中,就是图中的红色部分;
2.写到磁盘 (write),但是没有持久化(fsync),物理上是在文件系统的 page cache 里面,也就是图中的黄色部分;
3.持久化到磁盘,对应的是 hard disk,也就是图中的绿色部分。
日志写到 redo log buffer 是很快的,wirte 到 page cache 也差不多,但是持久化到磁盘的速度就慢多了。
24 | MySQL是怎么保证主备一致的?
图 2 中,包含了我在上一篇文章中讲到的 binlog 和 redo log 的写入机制相关的内容,可以看到:主库接收到客户端的更新请求后,执行内部事务的更新逻辑,同时写 binlog。
备库 B 跟主库 A 之间维持了一个长连接。主库 A 内部有一个线程,专门用于服务备库 B 的这个长连接。一个事务日志同步的完整过程是这样的:
1.在备库 B 上通过 change master 命令,设置主库 A 的 IP、端口、用户名、密码,以及要从哪个位置开始请求 binlog,这个位置包含文件名和日志偏移量。
2.在备库 B 上执行 start slave 命令,这时候备库会启动两个线程,就是图中的 io_thread 和 sql_thread。其中 io_thread 负责与主库建立连接。
3.主库 A 校验完用户名、密码后,开始按照备库 B 传过来的位置,从本地读取 binlog,发给 B。
4.备库 B 拿到 binlog 后,写到本地文件,称为中转日志(relay log)。
5.sql_thread 读取中转日志,解析出日志里的命令,并执行。
binlog 的三种格式对比
一种是 statement,一种是 row ,第三种格式,叫作 mixed
---
25 | MySQL是怎么保证高可用的?
正常情况下,只要主库执行更新生成的所有 binlog,都可以传到备库并被正确地执行,备库就能达到跟主库一致的状态,这就是最终一致性。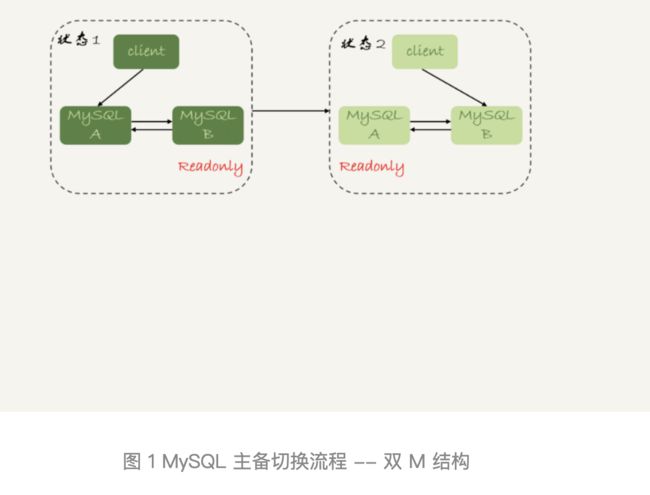
主备延迟
在介绍主动切换流程的详细步骤之前,我要先跟你说明一个概念,即“同步延迟”。与数据同步有关的时间点主要包括以下三个:
1.主库 A 执行完成一个事务,写入 binlog,我们把这个时刻记为 T1;
2.之后传给备库 B,我们把备库 B 接收完这个 binlog 的时刻记为 T2;
3.备库 B 执行完成这个事务,我们把这个时刻记为 T3。所谓主备延迟,就是同一个事务,在备库执行完成的时间和主库执行完成的时间之间的差值,也就是 T3-T1。
主备延迟的来源
首先,有些部署条件下,备库所在机器的性能要比主库所在的机器性能差。
第二种常见的可能了,即备库的压力大
这就是第三种可能了,即大事务。
不要一次性地用 delete 语句删除太多数据。其实,这就是一个典型的大事务场景。