【TensorFlow】两种方式restore训练好的模型预测图片
训练神经网络模型并不是我们的最终目的,我们想要实现的是用训练好的模型来预测未知图片。深度学习领域框架众多,本文仅讨论TensorFlow框架及其生成的ckpt模型。如何实现网络模型的restore呢?简单来说,restore训练好的模型有两种思路:
思路一:恢复网络结构 + 参数
1.1 思路解析
先从已经训练好的模型的默认图中得到模型的输入输出计算节点,也就是x节点和y(也即logits),然后使用sess.run的方式启动运算过程计算y的输出,期间将需要预测的图片feed给x节点。这种思路将图片数据输入到训练好的模型结构中进行计算,得到一个预测值,该方式不需要重建网络结构,但要求训练模型时为输入输出节点分别命名,以便restore期间使用get_tensor_by_name方法获取这些节点。该种思路如下图所示:

1.2 示例代码
以训练一个仅有两层卷积层、两层池化层和两个全连接层,输入维度为[20, 20, 1],结果分为3类的简单网络为例具体阐释以上思路。首先是训练网络的脚本train.py:
# ================================ #
# 网络结构定义
# 输入层:[None, 20, 20, 1]
# 卷积层一:[None, 20, 20, 6]
# 池化层一:[None, 10, 10, 6]
# 卷积层二:[None, 10, 10, 16]
# 池化层二:[None, 5, 5, 16]
# 全连接层一:[None, 120]
# 全连接层二:[None, 3]
# ================================ #
x = tf.placeholder(tf.float32, shape=[None, 20, 20, 1], name='x-input')
with tf.variable_scope('layer1-conv1'):
conv1_weights = tf.get_variable('weight', [5,5,1,6],
initializer=tf.truncated_normal_initializer(stddev=0.1))
conv1_biases = tf.get_variable('bias',[6],
initializer=tf.constant_initializer(0.0))
conv1 = tf.nn.conv2d(x, conv1_weights, strides=[1, 1, 1, 1], padding='SAME')
relu1 = tf.nn.relu(tf.nn.bias_add(conv1, conv1_biases))
with tf.name_scope('layer2-pool1'):
pool1 = tf.nn.max_pool(relu1, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
with tf.variable_scope('layer3-conv2'):
conv2_weights = tf.get_variable('weight', [5,5,6,16],
initializer=tf.truncated_normal_initializer(stddev=0.1))
conv2_biases = tf.get_variable('bias',[16],
initializer=tf.constant_initializer(0.0))
conv2 = tf.nn.conv2d(pool1, conv1_weights, strides=[1, 1, 1, 1], padding='SAME')
relu2 = tf.nn.relu(tf.nn.bias_add(conv2, conv2_biases))
with tf.name_scope('layer4-pool2'):
pool2 = tf.nn.max_pool(relu2, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
pool2_shape = pool2.get_shape().as_list() # 得到池化层二的维度信息,如[10, 5, 5, 16],用于计算一维张量长度
nodes = pool2_shape[1] * pool2_shape[2] * pool2_shape[3] # 每一张图被展开为长度5 * 5 * 16的一维张量
reshaped = tf.reshape(pool2, [-1, nodes]) # reshape成行数不定,长度为400的张量
with tf.variable_scope('layer5-fc1'):
fc1_weights = tf.get_variable('weight', [400, 120],
initializer=tf.truncated_normal_initializer(stddev=0.1))
tf.add_to_collection('losses', regularizer(fc1_weights))
fc1_biases = tf.get_variable('bias', [120],
initializer=tf.constant_initializer(0.0))
fc1 = tf.nn.relu(tf.matmul(reshaped, fc1_weights) + fc1_biases)
with tf.variable_scope('layer6-fc2'):
fc2_weights = tf.get_variable('weight', [120, 3],
initializer=tf.truncated_normal_initializer(stddev=0.1))
tf.add_to_collection('losses', regularizer(fc2_weights))
fc2_biases = tf.get_variable('bias', [3],
initializer=tf.constant_initializer(0.0))
logit = tf.add(tf.matmul(fc1, fc2_weights), fc2_biases, name='logit') # 这个logit即我们想要的计算结果
上述网络经过一定迭代次数的训练,可以得到训练完成的模型文件ckpt,我们可以使用下列代码restore网络的结构和权重,进而完成图片的预测predict.py:
import tensorflow as tf
with tf.Session() as sess:
saver = tf.train.import_meta_graph('./model/model3.ckpt-10000.meta') # 得到模型的网络结构
saver.restore(sess, tf.train.latest_checkpoint('./model')) # 从checkpoint中得到最新模型的权重文件路径进而恢复权重
graph = tf.get_default_graph() # 加载默认图
x = graph.get_tensor_by_name("x-input:0") # 张量名称构成为:
y = graph.get_tensor_by_name("layer6-fc2/logit:0") # 注意,如果网络结构中有variable_scope时,需要在name之前加上scope名作为前缀
for img_path in imgs_path: # 遍历所有图片
img_array = get_one_image(img_path)
logits = sess.run(y, feed_dict={x: img_array}) # 得到预测值
y = np.argmax(logits, axis=1)[0]
思路二:恢复网络参数
2.1 思路解析
重建训练期间使用的网络结构,restore时将各个参数恢复至相应的计算节点,然后sess.run想要预测的结果。这种思路适用于:1)模型训练期间未给输入输出计算节点命名的;2)模型模块化封装较好的,如把网络结构封装成了一个函数model或者函数inference。该种思路示意图如下:
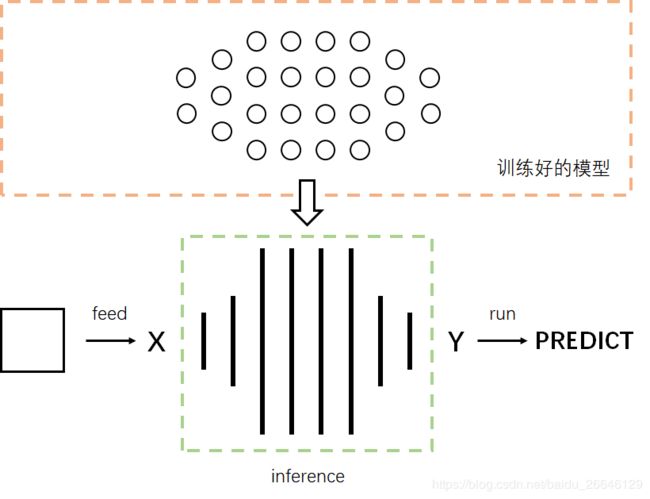
2.2 示例代码
网络结构和思路一中基本相同,但是这里在构建网络时做了一些封装工作,将网络作为一个函数inference,如下model.py:
def inference(input_tensor, train_or_eval, regularizer):
with tf.variable_scope('layer1-conv1'):
conv1_weights = tf.get_variable('weight', [5,5,1,6],
initializer=tf.truncated_normal_initializer(stddev=0.1))
conv1_biases = tf.get_variable('bias',[6],
initializer=tf.constant_initializer(0.0))
conv1 = tf.nn.conv2d(input_tensor, conv1_weights, strides=[1, 1, 1, 1], padding='SAME')
relu1 = tf.nn.relu(tf.nn.bias_add(conv1, conv1_biases))
with tf.name_scope('layer2-pool1'):
pool1 = tf.nn.max_pool(relu1, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
with tf.variable_scope('layer3-conv2'):
conv2_weights = tf.get_variable('weight', [5,5,6,16],
initializer=tf.truncated_normal_initializer(stddev=0.1))
conv2_biases = tf.get_variable('bias',[16],
initializer=tf.constant_initializer(0.0))
conv2 = tf.nn.conv2d(pool1, conv1_weights, strides=[1, 1, 1, 1], padding='SAME')
relu2 = tf.nn.relu(tf.nn.bias_add(conv2, conv2_biases))
with tf.name_scope('layer4-pool2'):
pool2 = tf.nn.max_pool(relu2, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
pool2_shape = pool2.get_shape().as_list() # 得到池化层二的维度信息,如[10, 5, 5, 16],用于计算一维张量长度
nodes = pool2_shape[1] * pool2_shape[2] * pool2_shape[3] # 每一张图被展开为长度5 * 5 * 16的一维张量
reshaped = tf.reshape(pool2, [-1, nodes]) # reshape成行数不定,长度为400的张量
with tf.variable_scope('layer5-fc1'):
fc1_weights = tf.get_variable('weight', [400, 120],
initializer=tf.truncated_normal_initializer(stddev=0.1))
if regularizer != None:
tf.add_to_collection('losses', regularizer(fc1_weights))
fc1_biases = tf.get_variable('bias', [120],
initializer=tf.constant_initializer(0.0))
fc1 = tf.nn.relu(tf.matmul(reshaped, fc1_weights) + fc1_biases)
if train_or_eval:
fc1 = tf.nn.dropout(fc1, 0.5) # drop
with tf.variable_scope('layer6-fc2'):
fc2_weights = tf.get_variable('weight', [120, 3],
initializer=tf.truncated_normal_initializer(stddev=0.1))
if regularizer != None:
tf.add_to_collection('losses', regularizer(fc1_weights))
tf.add_to_collection('losses', regularizer(fc2_weights))
fc2_biases = tf.get_variable('bias', [3],
initializer=tf.constant_initializer(0.0))
logits = tf.add(tf.matmul(fc1, fc2_weights), fc2_biases)
return logits # 这个logit即我们想要的计算结果
同样,训练完成会得到ckpt模型文件,这里不同于思路一我们的网络结构作为一个提供公共服务的函数接口并没有对输入输出节点设置特别的名字,那么如何使用训练好的模型呢?答案是再次使用inference构建出原来的网络结构,然后恢复模型的权重值,最后把图片喂给它,predict.py:
import tensorflow as tf
import model
with tf.Graph().as_default():
x = tf.placeholder(tf.float32, [1,20,20,1]) # 每次只预测一张图
# 也可以在此使用tf接口定义图片预处理节点
# image = tf.cast(image_array, tf.float32) # 图片转为float32
# image = tf.image.per_image_standardization(image) # 图片标准化
# image = tf.reshape(image, [1, 20, 20, 1]) # 图片转为指定的维度
y = model.inference(x, False, None)
with tf.Session() as sess:
saver = tf.train.Saver()
ckpt = tf.train.get_checkpoint_state('./model')
if ckpt and ckpt.model_checkpoint_path:
saver.restore(sess, ckpt.model_checkpoint_path)
print('模型加载成功!')
else:
print('模型不存在!')
for img_path in imgs_path: # 遍历所有图片
img_array = get_one_image(img_path)
logits = sess.run(y, feed_dict={x: img_array}) # 得到预测值
y = np.argmax(logits, axis=1)[0]