NL2SQL的发展
前言
NL2SQL(Natural Language to SQL)是一项将用户的自然语句转为可执行 SQL 语句的技术,有很大的实际应用价值,对改善用户与数据库之间的交互方式有很大意义。在本文中,追一科技介绍了 NL2SQL 的价值,及其过去、现在与未来,希望能有更多关于 NL2SQL 的落地场景研究。
NL2SQL 的价值
在 AI、区块链、IoT、AR 等高新技术飞速发展的当下,数据库这一宝库似乎被大家遗忘在了角落。数据库存储了大量的个人或者企业的生产运营数据,我们每天都会和数据库产生或多或少的交互。通常,查询数据库中的数据需要通过像 SQL 这样的程序式查询语言来进行交互,这就需要懂 SQL 语言的专业技术人员来执行这一操作。为了让非专业用户也可以按需查询数据库,当前流行的技术方案设计了基于条件筛选的专门界面,用户可以通过点选不同的条件来查询数据库,比如下面这个筛选汽车的界面。
然而,在这个界面上操作,极大地限制了数据库查询的使用场景和查询界限。同时,即使对于精通数据库程序语言的专业人士,经常构思 SQL 语句、维护这样一个查询界面也是一项重复度较高的工作。
在 CUI(Conversation User Interface)的大背景下,如何通过自然语言自由地查询数据库中的目标数据成为了新兴的研究热点。Natural Language to SQL (NL2SQL) 就是这样的一项技术,它可以将用户的自然语句转为可以执行的 SQL 语句。
Nothing is better than an example. 针对上图这样的数据库表格,用户可能会想知道「宝马的车总共卖了多少辆?」,其相应的 SQL 表达式是「SELECT SUM(销量) FROM TABLE WHERE 品牌==」宝马」;」。而 NL2SQL 做的,就是结合用户想要查询的表格,将用户的问句转化为相应的 SQL 语句,从而得到答案「8」。
表格数据是信息在经过人为整理、归纳后的一种高效的结构化表达形式,信息的价值、密度和质量高于普通的文字文本。用很多文字才能描述清楚的信息,可能一张表格就够了。在行业研报、业绩报告、新闻公告、使用说明书等各种书面信息载体上,尤其是金融、快消等行业的各种报告中,充斥着许多表格形式的结构化数据。而当用户去查询表格中的内容时,需要肉眼去从表格中筛选满足条件的数据,准确率和效率都较低。通过 NL2SQL,用户在查询这些表格的内容时,可以直接通过自然语言与表格进行交互,并得到结果,用户体验会很自然。比如下面这张出自某房地产行业研报的表格:
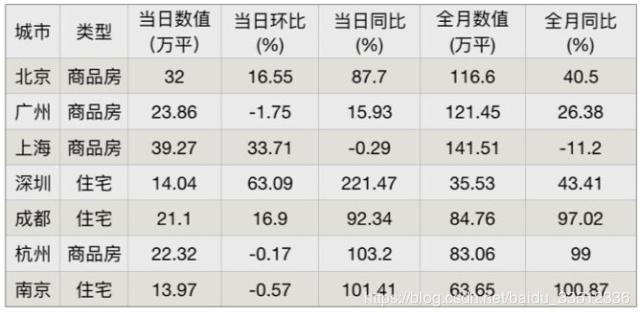
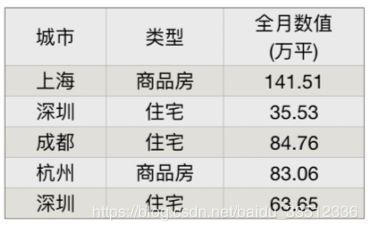
针对这张表格,用户可能会想问「哪些城市的全月销量同比超过了 50% 或者当日环比大于 25%?相应的房产类型和销售面积情况如何?」这样的问题。通过 NL2SQL 模型,可以直接得到相应的 SQL 语句「select 城市, 类型, 全月数值 (万平) from table where 全月同比 (%) > 50 or 当日环比 (%) > 25」,并进一步返回执行该 SQL 语句后的结果,如下表所示:
如今,在很多日常应用场景中,用户都会和数据库进行交互,比如订餐、订票、查天气、查报表等等,绝大部分的解决方案也是通过输入条件和点选条件来进行查询。即使部分场景已经进行了技术升级,可以通过对话机器人的方式来进行交互,但其背后仍然预设了不同的条件入口,需要模型通过一系列的实体识别、槽值提取等流程来填充预先规定好的 SQL 模板。对于这样的方案,不仅查询的信息和筛选的条件会局限于预先设好的字段,这些功能模块的开发和维护也需要大量的人力资源。而如果使用 NL2SQL 的技术方案,用户与数据库之间的距离可以进一步缩短,用户可以更自由地查询更多信息、表达自己更丰富的查询意图,还可以减轻目前技术方案的繁琐,解放程序员。
NL2SQL 不仅可以独当一面,降低人机交互的距离和门槛,也可以与其它技术相辅相成。比如,现今的机器阅读理解技术已经可以在 SQUAD 1.0、SQUAD 2.0 等数据集上超越人类水平,还可以在其它各种形式的数据集上寻找答案,比如多段落、多文档、抽取式答案、生成式答案等形式。但目前机器阅读理解技术还不能对文章中出现的表格进行解读,如果用户想要的答案存在于文章中的表格内,那么现有的模型就都束手无策了。
然而表格数据在真实场景中存在很多,且表格中的数据很有价值,用户也会经常针对其中的数据进行提问。比如下图中的这一真实场景,用户如果想问「在哪些年里平均溢价率高于 20%」这样的问题,依靠现有的机器阅读理解技术,在文本中是找不到答案的。而 NL2SQL 可以很好地弥补现有技术的不足,完善非结构化文本问答在真实落地场景中的应用,更充分地发掘此类结构化数据的价值。
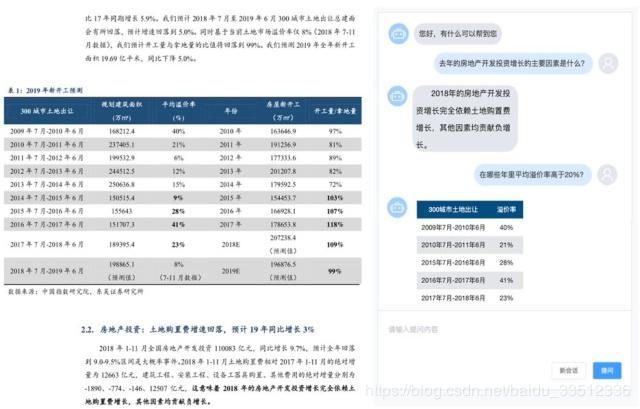
研报部分来源于东吴证券《房地产行业 2019 年度策略》
存储在 Excel 中的表格数据也可以被利用起来。设想一下这样的场景,财务人员将日常的财务数据存储在 Excel 中,日积月累产生了大量的 Excel 文件。财务人员需要了解其中的数据时,首先要从层层深入的文件夹、密密麻麻的 Excel 中找到正确的文件,然后打开 Excel 文件去密集的单元格中找到想要的答案。在这个过程中找错文件是常事,效率十分低下。如果利用 NL2SQL 技术,这一场景就会非常的优雅高效:首先定位预处理存入数据库的表格,再执行查询逻辑,最后将结果直接返回。
我们可以期待,NL2SQL 将改变传统的人与表格之间的交互方式,作为不可或缺的功能来改善人与机器之间的交流,让这场 CUI 升级革命可以走进更多的场景、行业,惠及更广泛的群体。
NL2SQL 的历史与现在
早在上世纪中后期,人们就已经在尝试开发通过自然语言直接访问数据库中存储数据的界面了(NLIDB,Natural Language Interfaces to Databases),其中最知名的是二十世纪六十年代的 LUNAR 系统,它通过对问句的句式语法分析,来回答关于从阿波罗任务中带回的月岩的地质学分析问题。再比如二十世纪七十年代初的 LADDER 系统,它已经支持通过一定的语义语言从数据库提取信息。但这种系统对自然语言问题的解析并不依赖于句子成分,这要求每一个具有特定知识的数据库都需要特定的语义语法,所以该方法在普适性上不够完善。
受限于当时技术发展,NLIDB 面临很大的挑战,系统语言的支持上限以及对于语言的理解上限不明确、语言上逻辑和含义的歧义、生僻词的出现等,以及替代品的发展(如 Excel 表格这种存储表格新形式的出现),这些都极大限制了这个领域的发展。
直到 2015 年 AI 的复苏和自然语言处理的创新,人们才慢慢把关注拉回了 NLIDB。如何利用自然语言更自然更自由地与数据库交互成为了新兴的研究热点。
那 NL2SQL 在学术中的定位是怎么样的呢?NL2SQL 这一任务的本质,是将用户的自然语言语句转化为计算机可以理解并执行的规范语义表示 (formal meaning representation),是语义分析 (Semantic Parsing) 领域的一个子任务。NL2SQL 是由自然语言生成 SQL,那么自然也有 NL2Bash、NL2Python、NL2Java 等类似的研究。下面是来自 NL2Bash Dataset 的一条数据:
NL: Search for the string ‘git’ in all the files under current directory tree without traversing into ‘.git’ folder and excluding files that have ‘git’ in their names.
Bash: find . -not -name ".git" -not -path "*.git*" -not –name "*git*" | xargs -I {} grep git {}
虽然生成的程序语言不同,但核心任务与 NL2SQL 相同,都是需要计算机理解自然语言语句,并生成准确表达语句语义的可执行程序式语言。广义来说,KBQA 也与 NL2SQL 技术有着千丝万缕的联系,其背后的做法也是将用户的自然语言转化为逻辑形式,只不过不同点在于前者转化的逻辑形式是 SPARQL,而不是 SQL。将生成的查询语句在知识图谱执行,直接得到用户的答案,进而提升算法引擎的用户体验。
目前,NL2SQL 方向已经有 WikiSQL、Spider、WikiTableQuestions、ATIS 等诸多公开数据集。不同数据集都有各自的特点,这里简单介绍一下这四个数据集。
WikiSQL 是 Salesforce 在 2017 年提出的大型标注 NL2SQL 数据集,也是目前规模最大的 NL2SQL 数据集。它包含了 24,241 张表、80,645 条自然语言问句及相应的 SQL 语句。下图是其中的一条数据样例,包括一个 table、一条 SQL 语句及该条 SQL 语句所对应的自然语言语句。
该数据集自提出之后,已经有 18 次公开提交。由于 SQL 的形式较为简单,该数据集不涉及高级用法,Question 所对应的正确表格已经给定,不需要联合多张表格,这些简化使得强监督模型已经可以在 WikiSQL 上达到执行 91.8% 的执行准确率。
Spider是耶鲁大学 2018 年新提出的一个较大规模的 NL2SQL 数据集。该数据集包含了 10,181 条自然语言问句、分布在 200 个独立数据库中的 5,693 条 SQL,内容覆盖了 138 个不同的领域。虽然在数据数量上不如 WikiSQL,但 Spider 引入了更多的 SQL 用法,例如 Group By、Order By、Having,甚至需要 Join 不同表,这更贴近真实场景,也带来了更高的难度。因此目前在该榜单上只有 8 次提交,在不考虑条件判断中 value 的情况下,准确率最高只有 54.7,可见这个数据集的难度非常大。
上图是该数据集中的一条样例。在这个以 College 为主题的数据库中,用户询问「讲师的工资高于平均工资水平的部门以及相应的预算是什么?」,模型需要根据用户的问题和已知的数据库中各种表格、字段及其之间错综复杂的关系来生成正确的 SQL。
WikiTableQuestions 是斯坦福大学于 2015 年提出的一个针对维基百科中那些半结构化表格问答的数据集,包含了 22,033 条真实问句以及 2,108 张表格。由于数据的来源是维基百科,因此表格中的数据是真实且没有经过归一化的,一个 cell 内可能包含多个实体或含义,比如「Beijing, China」或「200 km」;同时,为了很好地泛化到其它领域的数据,该数据集测试集中的表格主题和实体之间的关系都是在训练集中没有见到过的。下图是该数据集中的一条示例,数据阐述的方式展现出作者想要体现的问答元素。
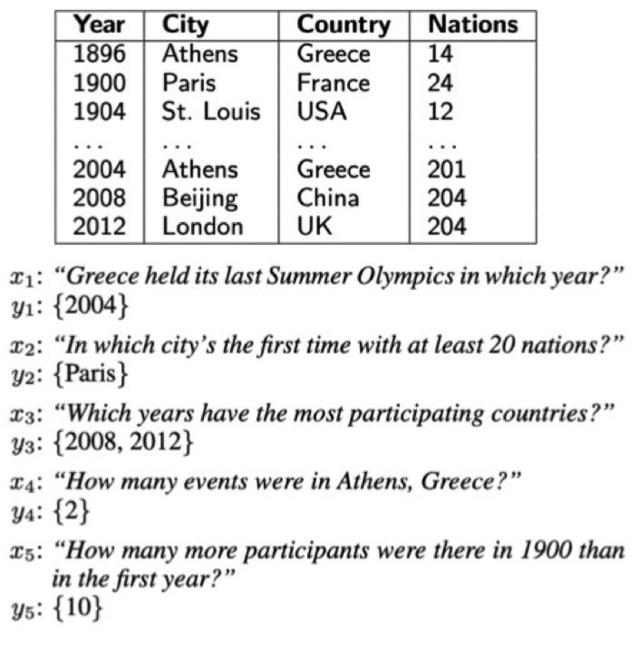
The Air Travel Information System (ATIS) 是一个年代较为久远的经典数据集,由德克萨斯仪器公司在 1990 年提出。该数据集获取自关系型数据库 Official Airline Guide (OAG, 1990),包含 27 张表以及不到 2,000 次的问询,每次问询平均 7 轮,93% 的情况下需要联合 3 张以上的表才能得到答案,问询的内容涵盖了航班、费用、城市、地面服务等信息。下图是取自该数据集的一条样例,可以看出比之前介绍的数据集更有难度。

图片来自于 http://www.aclweb.org/anthology/H90-1021
在深度学习端到端解决方案流行之前,这一领域的解决方案主要是通过高质量的语法树和词典来构建语义解析器,再将自然语言语句转化为相应的 SQL。

图片来自于 Natural Language Interfaces to Databases(https://arxiv.org/pdf/cmp-lg/9503016.pdf)
现在的解决方案则主要是端到端与 SQL 特征规则相结合。以在 WikiSQL 数据集上的 SOTA 模型 SQLova 为例:首先使用 BERT 对 Question 和 SQL 表格进行编码和特征提取,然后根据数据集中 SQL 语句的句法特征,将预测生成 SQL 语句的任务解耦为 6 个子任务,分别是 Select-Column、Select-Aggregation、Where-Number、Where-Column、Where-Operation 以及 Where-Value,不同子任务之间存在一定的依赖关系,最终使用提取到的特征依次进行 6 个任务的预测。
图片来自于 SQLNet(https://arxiv.org/pdf/1711.04436.pdf)
NL2SQL 的未来
WikiSQL 数据集虽然是目前规模最大的有监督数据集,但其数据形式和难度过于简单:对于 SQL 语句,条件的表达只支持最基础的>、<、=,条件之间的关系只有 and,不支持聚组、排序、嵌套等其它众多常用的 SQL 语法,不需要联合多表查询答案,真实答案所在表格已知等,所以在这个数据集上,SQL 执行结果的准确率目前已经达到了 91.8%。
但存在一个问题,这样的数据集并不符合真实的应用场景。在真实场景中,用户问题中的值很可能不是数据表中所出现的,需要一定的泛化才可以匹配到;真实的表之间存在错综复杂的键关联关系,想要得到真实答案,通常需要联合多张表进行查询;每张表都有不同的意义,并且每张表中列的意义也各不不同,甚至可能相同名字的列在不同的表格中所代表的含义也是不同的;真实场景中,用户的问题表达会很丰富,会使用各种各样的条件来筛选数据。诸如此类的实际因素还有很多。因此,WikiSQL 数据集起到的作用很大程度上是抛砖引玉,而不具备实际应用场景落地的价值。
相比之下,Spider 等数据集更贴近真实应用场景:涉及到查询语句嵌套、多表联合查询,并且支持几乎所有 SQL 语法的用法,用户问句的表达方式和语义信息也更丰富。但即使作者们考虑到数据集的难度,贴心地将数据集按照难度分为简单、中等和困难,该数据集的难度也依然让人望而生畏,目前各项指标也都很低。如何更好地结合数据库信息来理解并表达用户语句的语义、如何编码及表达数据库的信息、如何生成复杂却有必要的 SQL 语句,此类挑战还有很多需要解决,它们都是非常值得探索的方向。
现在很多 NLP 子任务的指标已经刷得让人无路可走了,低垂的果实被摘得七零八落。而 NL2SQL 以及其它的语义分析任务,因为各种各样的原因,现在还没有引起大家足够的关注,但它们有着相比于其它任务更高的实际应用价值。如果可以落地真实场景,这将极大地改变现有的用户和数据库之间的交互方式,人们可以自由地和数据库进行交互,充分挖掘数据的价值,也减轻程序员的负担。学界和工业界也越来越关注这方面的研究,追一科技 6 月份将发起首届中文 NL2SQL 挑战赛,期待 NL2SQL 在不远的将来会迎来属于自己的春天,学术应用两开花。